1. 초록
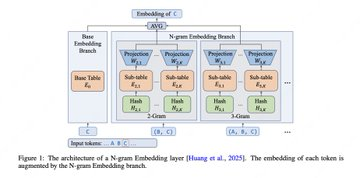
LongCat-Flash-Lite는 고희소성 MoE 시나리오를 대상으로 한 오픈 소스 대형 모델로, 총 매개변수는 68.5B이지만, 토큰당 활성화되는 것은 약 2.9B~4.5B에 불과합니다. 핵심 아이디어는 MoE 전문가 수를 계속 늘리는 것이 아니라, 특정 희소 구간에서 N-gram 임베딩(약 30B+ 파라미터)의 용량을 확장하여 더 나은 '효과-비용' 타협을 달성하고, 시스템 측면 최적화를 통해 추론 처리량을 향상시키는 것입니다. 이 모델은 256K 컨텍스트(YaRN)를 지원합니다.
2. 핵심 특징
- N-그램 임베딩 확장: 매우 희소한 MoE 하에서 더 큰 N-그램 임베딩 테이블로 파레토의 프런티어 성능을 향상시킵니다.
- 추론 효율 최적화: N그램 캐시와 동기 커널을 도입하여 MoE 계층의 I/O 압력을 줄이고, 지연 시간과 처리량이 높은 방향으로 정렬합니다.
- 에이전트/코딩 지향: 도구 사용 및 코딩 평가(예: SWE-Bench, τ²-Bench, TerminalBench)에서 뛰어난 성과를 보입니다.
- 긴 컨텍스트: 256K 컨텍스트 창으로, 코드 저장소 수준의 입력과 긴 대화 작업 분해에 적합합니다.
3. 설치
- 환경: 파이썬≥ 3.10, 토치≥2.6, 트랜스포머≥4.57.6, 가속≥ 1.10.0.
2. 종속 설치: pip install -U transformers==4.57.6 accelerate==1.10.0
3. 로딩 방법: 트랜스포머를 사용해 trust_remote_code=True를 로드하고 켜세요(운영 전에 커스텀 코드를 검토하는 것이 권장됩니다).
- 하드웨어 팁: 공식 예시에는 최소 2개의 80GB 메모리 GPU(예: A100/H100 80GB)가 작동을 위해 언급되어 있습니다.
4. 일반적인 사용 사례
- 코드 프록시: 다중 파일 변경, 단일 테스트 수정, PR 생성 및 반복.
- 툴 콜 에이전트: 함수/도구 오케스트레이션, 워크플로우 자동화, 검색 + 실행 폐쇄 루프.
- 긴 컨텍스트 코딩: 대규모 창고 읽기, 긴 로그/긴 오류 위치 지정, 모듈 간 추적.
- 일반 추론: 비용 통제를 전제로 매일 Q&A 및 추론 작업을 수행합니다.
5. 생태와 경쟁 제품
- 생태학: 빠르게 시작할 수 있도록 트랜스포머 제공; 또한 SGLang 측의 적응과 단일 머신 멀티카드(TP/EP) 배포 사례도 제시합니다.
- 경쟁 제품 참조: 공식 비교 표에는 Kimi-Linear-48B-A3B, Qwen3-Next-80B-A3B-Instruct, 그리고 MoE에 속하는 폐쇄형 Gemini 2.5 Flash-Lite가 포함됩니다; LongCat-Flash-Lite는 "낮은 활성화 계산 + 임베딩 스케일링 + 시스템 최적화"라는 결합된 경로에 중점을 둡니다.
6. 제한 및 주의사항
- 비디오 메모리 및 대역폭 압력: 임베딩 매개변수의 비율이 높아 비디오 메모리와 메모리 대역폭을 더 많이 소모할 수 있습니다; 다른 하드웨어에서는 수입이 불안정할 것입니다.
2. trust_remote_code 위험: 운영 환경에서는 코드 감사와 고정 버전을 요구합니다.
- 평가 재현성: 일부 비교 항목은 공개 보고서에서 나옵니다; 실제 효과는 데이터, 프롬프트, 프록시 프레임워크 재테스트에 따라 달라져야 합니다.
- 긴 컨텍스트 비용: 256K는 더 많은 정보를 담을 수 있지만, 검색, 절단, 프롬프트 엔지니어링이 최종 안정성과 비용을 결정합니다.
7. 프로젝트 주소
https://huggingface.co/meituan-longcat/LongCat-Flash-Lite
8. 자주 묻는 질문
Q: LongCat-Flash-Lite의 "N-gram 임베딩"이 해결한 문제는 무엇인가요?
A: 목표는 더 큰 N-그램 임베딩 테이블을 사용하여 매우 희소한 MoE 시나리오에서 표현식과 명중 효율을 개선하고, 유사한 활성화 계산 하에서 더 나은 효과-비용 타협을 얻는 것입니다.
Q: 왜 LongCat-Flash-Lite를 trust_remote_code 활성화해야 하나요?
A: 모델에 맞춤형 로딩/추론 논리가 포함되어 있기 때문입니다; 버전은 잠기고 관련 코드를 검토한 후 프로덕션으로 넘어가야 합니다.
Q: LongCat-Flash-Lite는 지역 단일 카드에 적합한가요?
답변: 공식 빠른 시작 권장 GPU는 최소 2×80GB 이상입니다; 단일 카드는 더 공격적인 양자화/병렬성과 엔지니어링 변환이 필요하며, 효과와 안정성을 보장하지는 않습니다.
Q: 256K 길이의 컨텍스트가 코드 저장소에서 어떻게 더 신뢰성 있게 작동하나요?
답변: 검색과 청킹(RAG/파일 수준 인덱싱)을 결합하는 것이 일반적으로 '전체 문맥 채우기'보다 더 안정적이고 비용 효율적입니다.
Q: SGLang이 LongCat-Flash-Lite를 배포하는 주요 사항은 무엇인가요?
A: 초점은 TP/EP 조합을 해당 커널/의존성 버전과 병렬로 매칭하는 데 있습니다. 공식 시작 매개변수 템플릿에서 시작하는 것이 권장됩니다.