1. 要旨
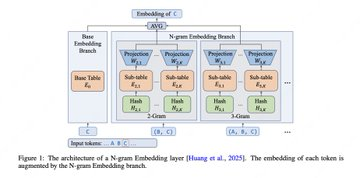
LongCat-Flash-Liteは、高スパーシティMoEシナリオを対象としたオープンソースの大規模モデルです。総パラメータは68.5Bですが、1トークンあたり有効化されるのは約2.9B~4.5B程度です。 その主な考え方は、MoE専門家の数を増やし続けるのではなく、特定のスパース区間でNグラム埋め込み(約30B+パラメータ)の能力を拡大し、システム側の最適化による推論スループットを向上させることで、より良い「効果コスト」の妥協を実現することです。 モデルは256Kコンテキスト(YaRN)をサポートしています。
2. コア機能
- Nグラム埋め込み展開:非常に疎なMoEの下でより大きなNグラム埋め込みテーブルでパレートのフロンティア性能を向上させる。
- 推論効率最適化:Nグラムキャッシュと同期カーネルを導入し、MoE層のI/O圧力を低く、低遅延かつ高スループットに配置します。
- エージェント/コーディング志向:ツールの使用およびコーディング評価(SWE-Bench、τ²-Bench、TerminalBenchなど)で卓越したパフォーマンスを発揮すること。
- 長いコンテキスト:256Kのコンテキストウィンドウで、コードリポジトリレベルの入力や長いダイアログタスク分解に適しています。
3. 設置
- 環境:Python≥ 3.10、Torch≥2.6、Transformers≥4.57.6、Accelerate≥ 1.10.0。
2. 従属インストール:pip install -U transformers==4.57.6 accelerate==1.10.0
3. 読み込み方法:トランスを使ってtrust_remote_code=Trueをロードし起動します(本番環境に入る前にカスタムコードを確認することを推奨します)。
- ハードウェアのヒント:公式の例では、動作のために少なくとも2台の80GBメモリGPU(例:A100/H100 80GB)が挙げられています。
4. 典型的なユースケース
- コードプロキシ:複数ファイルの変更、単一テスト修正、PR生成および反復。
- ツールコールエージェント:機能/ツールオーケストレーション、ワークフロー自動化、検索+実行クローズドループ。
- 長いコンテキストコーディング:大規模な倉庫読み取り、長いログ/長いエラーの位置付け、モジュール間トラッキング。
- 一般的な推論:コストを抑えることを前提に、日々のQ&Aや推論作業を行う。
5. 生態系と競合製品
- 生態:トランスフォーマーを提供して迅速に始めること; また、SGLang側の適応や単一マシンマルチカード(TP/EP)の導入例も示しています。
- 競合製品参照:公式比較表にはKimi-Linear-48B-A3B、Qwen3-Next-80B-A3B-Instruct、そしてクローズドソースのGemini 2.5 Flash-Lite(これもMoE)が含まれます。 LongCat-Flash-Liteは「低活性化計算+埋め込みスケーリング+システム最適化」という複合ルートに焦点を当てています。
6. 制限事項と注意事項
- ビデオメモリと帯域幅の圧力:埋め込みパラメータの割合が高いため、ビデオメモリやメモリ帯域幅を消費することがあります。 収入はハードウェアによって不安定になります。
2. trust_remote_codeリスク:本番環境ではコード監査と固定バージョンが必要です。
- 評価の再現性:一部の比較項目は公開レポートから得られます。 実際の効果は、あなたのデータ、プロンプト、プロキシフレームワークの再テストに基づいています。
- 長いコンテキストコスト:256Kはより多くの情報を収容できますが、検索、切断、プロンプトエンジニアリングが最終的な安定性とコストを決定します。
7. プロジェクトアドレス
https://huggingface.co/meituan-longcat/LongCat-Flash-Lite
8. よくある質問
Q: LongCat-Flash-Liteの「N-gram埋め込み」はどんな問題を解決していますか?
A: 目標は、より大きなNグラム埋め込み表を用いて、非常にスパーなMoEシナリオで表現と命中効率を改善し、同様の活性化計算においてより良い効果コストの妥協を得ることです。
Q: なぜLongCat-Flash-Liteはtrust_remote_code有効化が必要なのですか?
A: モデルにはカスタムの読み込み/推論ロジックが含まれているため、 バージョンはロックし、該当コードは本番環境に移行する前に必ず確認すべきです。
Q: LongCat-Flash-Liteはローカルのシングルカードに適していますか?
A: 公式のクイックスタート推奨は少なくとも2×80GBのGPUです。 単一カードはより積極的な量子化・並列処理やエンジニアリング変換を必要とし、効果や安定性を保証するものではありません。
Q: 256K長のコンテキストは、コードリポジトリでどのようにより信頼性が高く機能しますか?
A: 検索とチャンク(RAG/ファイルレベルのインデックス作成)を組み合わせることは、「完全なコンテキストを詰め込む」よりも一般的に安定してコスト効率が良いです。
Q: SGLangがLongCat-Flash-Liteを展開する際の重要なポイントは何ですか?
A: TP/EPの組み合わせを対応するカーネル/依存関係バージョンと並列にマッチさせることに重点が置かれています。 公式の開始パラメータテンプレートから始めるのが推奨されます。