1. Zusammenfassung
LongCat-Flash-Lite ist ein Open-Source-Großmodell, das auf hoch-spärliche MoE-Szenarien abzielt: Die Gesamtparameter betragen 68,5 B, aber pro Token werden nur etwa 2,9 B~4,5 B aktiviert. Die Hauptidee ist nicht, die Anzahl der MoE-Experten weiter zu vergrößern, sondern einen besseren "Effekt-Kosten"-Kompromiss zu erreichen, indem die Kapazität der N-Gramm-Einbettung (etwa 30 B+ Parameter für die Einbettung) in bestimmten spärlichen Intervallen erweitert und der Inferenzdurchsatz durch systemseitige Optimierung verbessert wird. Das Modell unterstützt 256K Kontext (YaRN).
2. Kernmerkmale
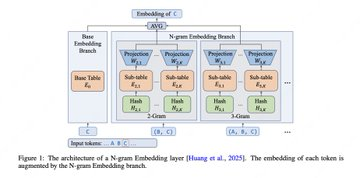
- N-Gramm-Einbettungserweiterung: Verbesserung der Frontier-Leistung von Pareto mit einer größeren N-Gramm-Einbettungstabelle unter sehr spärlichem MoE.
- Optimierung der Inferenzeffizienz: Einführung von N-Gramm-Cache und synchronem Kernel, um den I/O-Druck der MoE-Schicht zu reduzieren und sie auf eine niedrige Latenz und hohen Durchsatz auszurichten.
- Agentische/Codierungsorientierung: Hervorragende Leistung bei der Werkzeugnutzung und bei Codierungsbewertungen (wie SWE-Bench, τ²-Bench, TerminalBench).
- Langer Kontext: 256K Kontextfenster, geeignet für Code-Repository-Eingabe und lange Dialogaufgaben-Zerlegung.
3. Installation
- Umgebung: Python≥ 3.10, Torch≥2.6, Transformers≥4.57.6, Accelerate≥ 1.10.0.
2. Abhängige Installation: pip install -U transformers==4.57.6 accelerate==1.10.0
3. Lademethode: Verwenden Sie Transformatoren, um die trust_remote_code=True zu laden und einzuschalten (es wird empfohlen, den benutzerdefinierten Code vor Produktionsstart zu überprüfen).
- Hardware-Tipps: Das offizielle Beispiel nennt mindestens 2 GPUs mit jeweils 80 GB Speicher (wie A100/H100 80 GB) für den Betrieb.
4. Typische Anwendungsfälle
- Code-Proxy: Mehrfachdateiänderungen, einzelne Testfixes, PR-Generierung und Iteration.
- Tool Call Agent: Funktions-/Werkzeugorchestrierung, Workflow-Automatisierung, Abruf + Ausführung in geschlossener Schleife.
- Lange Kontextkodierung: großes Lagerhaus-Lesen, lange Log-/lange Fehlerpositionierung, Cross-Module-Tracking.
- Allgemeine Begründung: Führen Sie tägliche Frage-und-Antwort- und Argumentationsaufgaben durch, um die Kosten kontrollierbar zu halten.
5. Ökologie und konkurrierende Produkte
- Ökologie: Stell Transformers bereit, um schnell loszulegen; Es gibt auch ein Beispiel für die Anpassung der SGLang-Seite und den Einsatz von Single-Machine Multi-Card (TP/EP).
- Konkurrierende Produktreferenzen: Die offizielle Vergleichstabelle umfasst Kimi-Linear-48B-A3B, Qwen3-Next-80B-A3B-Instruct und das geschlossene Gemini 2.5 Flash-Lite, das ebenfalls MoE ist; LongCat-Flash-Lite konzentriert sich auf den kombinierten Weg von "Lower Activation Compute + Embedding Scaling + System Optimization".
6. Einschränkungen und Vorsichtsmaßnahmen
- Videospeicher- und Bandbreitendruck: Der Anteil der Einbettungsparameter ist hoch, was mehr Videospeicher und Speicherbandbreite beanspruchen kann; Das Einkommen wird unter anderer Hardware inkonsistent sein.
2. trust_remote_code Risiko: Die Produktionsumgebung erfordert ein Code-Audit und eine feste Version.
- Bewertungsreproduzierbarkeit: Einige Vergleichspunkte stammen aus öffentlichen Berichten; Der tatsächliche Effekt sollte auf deinen Daten, Prompts und dem erneuten Testen des Proxy-Frameworks basieren.
- Kosten für den langen Kontext: Obwohl der 256K mehr Informationen aufnehmen kann, bestimmen die Abruf-, Abschneidungs- und Prompting-Technik dennoch die endgültige Stabilität und Kosten.
7. Projektadresse
https://huggingface.co/meituan-longcat/LongCat-Flash-Lite
8. Häufig gestellte Fragen
F: Welches Problem löst LongCat-Flash-Lites "N-Gram Embedding"?
A: Das Ziel ist es, eine größere N-Gramm-Einbettungstabelle zu verwenden, um die Expressions- und Treffereffizienz in einem sehr spärlichen MoE-Szenario zu verbessern und so unter ähnlichen Aktivierungsberechnungen einen besseren Effekt-Kosten-Kompromiss zu erzielen.
F: Warum muss LongCat-Flash-Lite trust_remote_code aktiviert werden?
A: Da das Modell benutzerdefinierte Lade-/Inferenzlogik enthält; Die Version sollte gesperrt und der relevante Code vor der Produktion überprüft werden.
F: Ist LongCat-Flash-Lite für lokale Einzelkarten geeignet?
A: Die offizielle Schnellstart-Empfehlung lautet mindestens 2×80 GB GPU; Einzelkarten erfordern eine aggressivere Quantisierung/Parallelität und technische Transformation und garantieren keine Effektivität und Stabilität.
F: Wie funktioniert ein 256K-Langkontext zuverlässiger in Code-Repositories?
A: Die Kombination von Retrieval und Chunking (RAG/Datei-Indexierung) ist im Allgemeinen stabiler und kostengünstiger als das "Füllen des vollständigen Kontexts".
F: Was sind die wichtigsten Punkte für SGLang, LongCat-Flash-Lite einzusetzen?
A: Der Fokus liegt darauf, die TP/EP-Kombination parallel mit der entsprechenden Kernel/Dependenz-Version abzugleichen. Es wird empfohlen, mit der offiziellen Startparameter-Vorlage zu beginnen.