1. Résumé
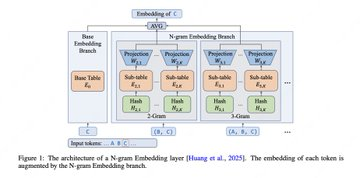
LongCat-Flash-Lite est un modèle open source de grande taille ciblant des scénarios MoE à haute parcimonie : les paramètres totaux sont de 68,5 milliards, mais seulement environ 2,9 milliards ~4,5 milliards sont activés par jeton. Son idée clé n’est pas de continuer à accumuler le nombre d’experts MoE, mais d’obtenir un meilleur compromis « effet-coût » en élargissant la capacité de l’embedding N-gramme (environ 30B+ paramètres pour l’embedding) dans des intervalles clairsemés spécifiques, et d’améliorer le débit d’inférence grâce à l’optimisation côté système. Le modèle prend en charge le contexte 256K (YaRN).
2. Caractéristiques principales
- Expansion d’inclusion N-gramme : Améliorer les performances frontières de Pareto avec une table d’embedding N-gramme plus grande sous un MoE très clairsemé.
- Optimisation de l’efficacité d’inférence : introduction du cache N-gramme et du noyau synchrone pour réduire la pression d’E/S de la couche MoE, l’orientant vers une faible latence et un haut débit.
- Orientation agentique/codage : Performance exceptionnelle dans l’utilisation des outils et les évaluations de codage (telles que SWE-Bench, τ²-Bench, TerminalBench).
- Contexte long : fenêtre contextuelle de 256K, adaptée à la saisie au niveau dépôt de code et à la décomposition de tâches de dialogue long.
3. Installation
- Environnement : Python≥ 3.10, Torch≥2.6, Transformers≥4.57.6, Accelerate≥ 1.10.0.
2. Installation dépendante : pip install -U transformers==4.57.6 accelerate==1.10.0
3. Méthode de chargement : Utilisez des transformateurs pour charger et allumer le trust_remote_code=True (il est recommandé de consulter le code personnalisé avant de passer à la production).
- Conseils matériels : L’exemple officiel mentionne au moins 2 GPU mémoire de 80 Go (comme A100/H100 80 Go) pour le fonctionnement.
4. Cas d’usage typiques
- Proxy de code : modifications multi-fichiers, corrections de tests uniques, génération de PR et itération.
- Agent d’appel d’outil : orchestration fonction/outil, automatisation du workflow, récupération + exécution en boucle fermée.
- Codage de contexte long : lecture d’entrepôt de grande taille, long log/positionnement d’erreur long, suivi inter-modules.
- Raisonnement général : Effectuer des questions et réponses quotidiennes et des tâches de raisonnement sous prétexte de maintenir les coûts contrôlables.
5. Écologie et produits concurrents
- Écologie : Fournir des Transformers pour démarrer rapidement ; Il donne également un exemple de l’adaptation du côté SGLang et du déploiement de la carte multi-machine (TP/EP).
- Références de produits concurrentes : Le tableau de comparaison officiel inclut Kimi-Linear-48B-A3B, Qwen3-Next-80B-A3B-Instruct, et le Gemini 2.5 Flash-Lite en code fermé, également MoE ; LongCat-Flash-Lite se concentre sur la voie combinée « calcul à faible activation + mise à l’échelle d’embedding + optimisation du système ».
6. Limitations et précautions
- Pression sur la mémoire vidéo et la bande passante : la proportion des paramètres d’intégration est élevée, ce qui peut consommer plus de mémoire vidéo et de bande passante mémoire ; Les revenus seront irréguliers selon le matériel.
2. trust_remote_code Risque : L’environnement de production nécessite un audit de code et une version fixe.
- Reproductibilité de l’évaluation : certains éléments de comparaison proviennent de rapports publics ; L’effet réel doit être basé sur vos données, vos invites et vos tests du framework proxy.
- Coût en contexte long : Bien que le 256K puisse contenir plus d’informations, l’ingénierie de récupération, troncature et d’incitation détermine toujours la stabilité et le coût finaux.
7. Adresse du projet
https://huggingface.co/meituan-longcat/LongCat-Flash-Lite
8. Questions fréquemment posées
Q : Quel problème le « N-gram Embedding » de LongCat-Flash-Lite résout-il ?
R : L’objectif est d’utiliser une table d’embedding N-gramme plus grande pour améliorer l’expression et l’efficacité des succès dans un scénario de MoE très clairsemé, afin d’obtenir un meilleur compromis effet-coût dans des calculs d’activation similaires.
Q : Pourquoi LongCat-Flash-Lite doit-il être activé trust_remote_code ?
R : Parce que le modèle contient une logique de chargement/inférence personnalisée ; La version doit être verrouillée et le code pertinent doit être examiné avant d’entrer en production.
Q : LongCat-Flash-Lite est-il adapté aux cartes locales individuelles ?
R : La recommandation officielle de démarrage rapide est d’avoir au moins 2×80 Go de GPU ; Les cartes individuelles nécessitent une quantification/parallélisme plus agressifs et une transformation technique, et ne garantissent pas l’efficacité et la stabilité.
Q : Comment le contexte long de 256K fonctionne-t-il de manière plus fiable dans les dépôts de code ?
R : Combiner la récupération et le fragmentation (indexation RAG/au niveau des fichiers) est généralement plus stable et économique que de « bourrer le contexte complet ».
Q : Quels sont les points clés pour que SGLang déploie LongCat-Flash-Lite ?
R : L’accent est mis sur la correspondance de la combinaison TP/EP avec la version correspondante noyau/dépendance en parallèle. Il est recommandé de commencer par le modèle officiel des paramètres de départ.