1. Abstract
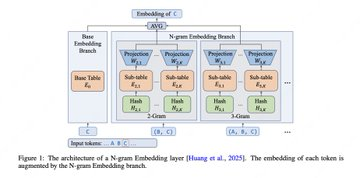
LongCat-Flash-Lite is an open-source large model targeting high-sparsity MoE scenarios: the total parameters are 68.5B, but only about 2.9B~4.5B are activated per token. Its key idea is not to continue to pile the number of MoE experts, but to achieve a better "effect-cost" compromise by expanding the capacity of N-gram embedding (about 30B+ parameters for embedding) in specific sparse intervals, and to improve inference throughput with system-side optimization. The model supports 256K context (YaRN).
2. Core features
- N-gram embedding expansion: Improve Pareto's frontier performance with a larger N-gram embedding table under highly sparse MoE.
- Inference efficiency optimization: Introducing N-gram Cache and synchronous kernel to reduce the I/O pressure of the MoE layer, orienting it to low latency and high throughput.
- Agentic/Coding orientation: Outstanding performance in tool usage and coding evaluations (such as SWE-Bench, τ²-Bench, TerminalBench).
- Long context: 256K context window, suitable for code repository-level input and long dialog task decomposition.
3. Installation
- Environment: Python≥ 3.10, Torch≥2.6, Transformers≥4.57.6, Accelerate≥ 1.10.0.
2. Dependent installation: pip install -U transformers==4.57.6 accelerate==1.10.0
3. Loading method: Use Transformers to load and turn on the trust_remote_code=True (it is recommended to review the custom code before going to production).
- Hardware tips: The official example mentions at least 2 80GB memory GPUs (such as A100/H100 80GB) for operation.
4. Typical use cases
- Code proxy: multi-file changes, single test fixes, PR generation and iteration.
- Tool call Agent: function/tool orchestration, workflow automation, retrieval + execution closed loop.
- Long context coding: large warehouse reading, long log/long error positioning, cross-module tracking.
- General reasoning: Do daily Q&A and reasoning tasks under the premise of keeping costs controllable.
5. Ecology and competing products
- Ecology: Provide Transformers to get started quickly; It also gives an example of the adaptation of SGLang side and the deployment of single-machine multi-card (TP/EP).
- Competing product references: The official comparison table includes Kimi-Linear-48B-A3B, Qwen3-Next-80B-A3B-Instruct, and the closed-source Gemini 2.5 Flash-Lite, which is also MoE; LongCat-Flash-Lite focuses on the combined route of "lower activation compute + embedding scaling + system optimization".
6. Limitations and precautions
- Video memory and bandwidth pressure: The proportion of embedding parameters is high, which may consume more video memory and memory bandwidth; The income will be inconsistent under different hardware.
2. trust_remote_code Risk: The production environment requires code audit and fixed version.
- Evaluation reproducibility: some comparison items come from public reports; The actual effect should be based on your data, prompts, and proxy framework retesting.
- Long context cost: Although the 256K can fit more information, the retrieval, truncation and prompting engineering still determines the final stability and cost.
7. Project address
https://huggingface.co/meituan-longcat/LongCat-Flash-Lite
8. Frequently asked questions
Q: What problem does LongCat-Flash-Lite's "N-gram Embedding" solve?
A: The goal is to use a larger N-gram embedding table to improve the expression and hit efficiency in a highly sparse MoE scenario, so as to obtain a better effect-cost compromise under similar activation calculations.
Q: Why does LongCat-Flash-Lite need to be trust_remote_code enabled?
A: Because the model contains custom loading/inference logic; The version should be locked and the relevant code should be reviewed before going to production.
Q: Is LongCat-Flash-Lite suitable for local single cards?
A: The official quick start recommendation is at least 2×80GB GPU; Single cards require more aggressive quantization/parallelism and engineering transformation, and do not guarantee effectiveness and stability.
Q: How does 256K long context work more reliably in code repositories?
A: Combining retrieval and chunking (RAG/file-level indexing) is generally more stable and cost-effective than "stuffing full context".
Q: What are the key points for SGLang to deploy LongCat-Flash-Lite?
A: The focus is on matching the TP/EP combination with the corresponding kernel/dependency version in parallel. It is recommended to start from the official starting parameter template.