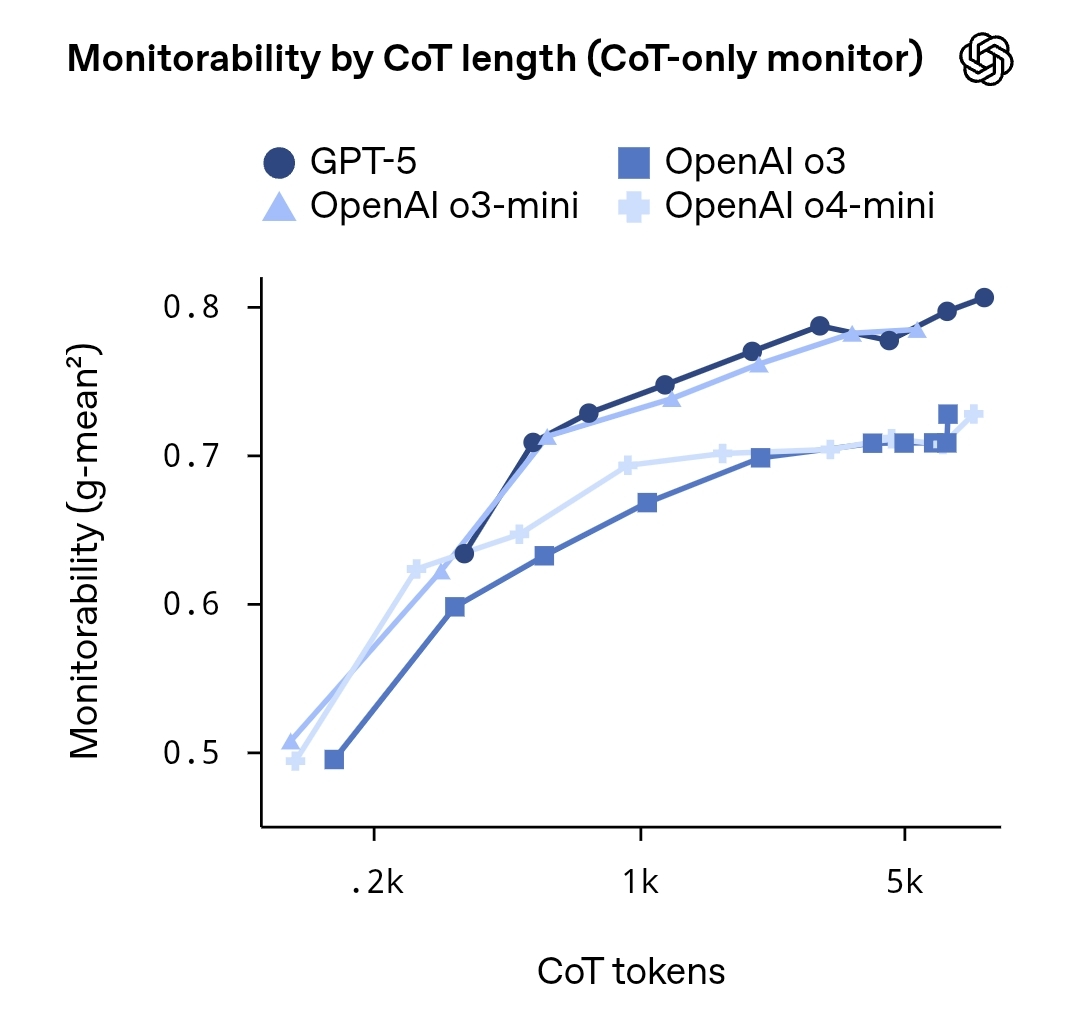
OpenAI发布研究报告《Evaluating Chain-of-Thought Monitorability》,系统评估大型语言模型内部“思维链”(Chain-of-Thought, CoT)的可监测性及安全影响。报告指出,尽管模型生成的推理过程可通过外部提示或代理模型在一定程度上预测,但其完整、精确的思维轨迹仍具有高度不确定性与不可复现性。
研究团队在多组实验中使用不同模型规模与任务类型,分析如何通过“代理模型监控”“隐式标记推理步骤”等方式,评估模型思维链的透明度与可审计性。结果显示,较高层次的推理目标可部分监测,但细节内容仍存在随机性与敏感信息泄露风险。报告建议在安全与隐私之间保持平衡,未来可通过特定监督机制、沙箱式推理与解释性标注框架,提升AI在关键任务场景下的可控性。
OpenAI在文末强调,该研究旨在为AI治理、风险审计与科研安全提供技术参考,不意味着当前公开模型具备或暴露内部“完整思维链”。后续研究将聚焦如何在不影响模型性能的前提下,提高推理透明度与过程验证能力。
常见问题
Q:这项研究的主题是什么?
A:研究主要探讨大型语言模型内部“思维链”是否可以被监测、解释或部分预测,以及这种可见性带来的安全影响。
Q:什么是“思维链”(Chain-of-Thought)?
A:指模型在生成答案前的中间推理步骤或逻辑过程,通常在输出中不可见,但影响最终结果。
Q:研究发现了哪些主要结论?
A:思维链可被部分预测,但无法完全复现,且存在随机性、隐私与滥用风险。
Q:为什么要研究思维链的可监测性?
A:为了提升AI系统的安全性与可审计性,使研究者能在关键任务中更好地理解模型的推理行为。
Q:研究是否意味着OpenAI公开了内部推理机制?
A:没有。报告仅为学术评估与安全治理参考,未披露任何可访问模型内部推理的接口或功能。