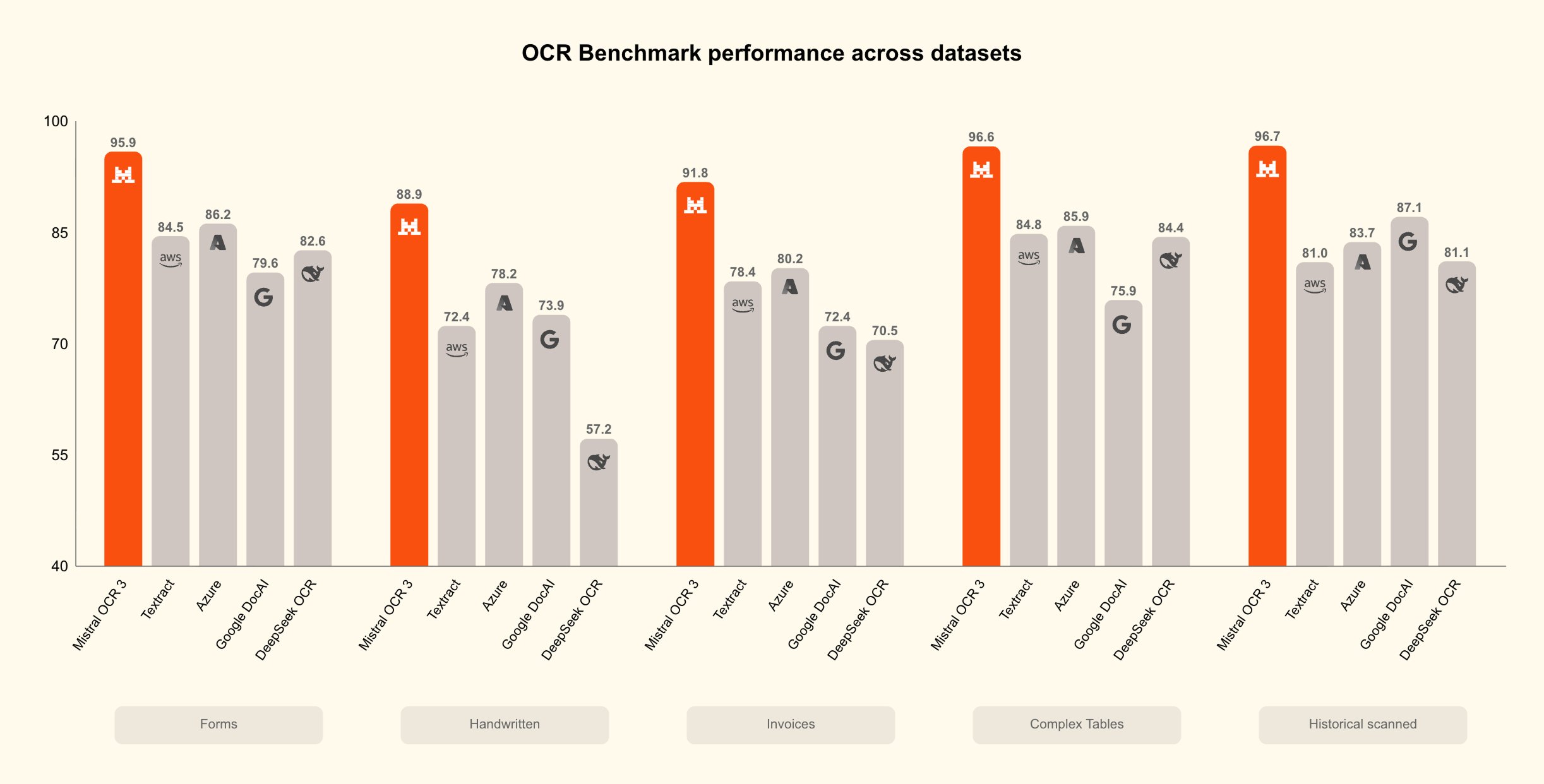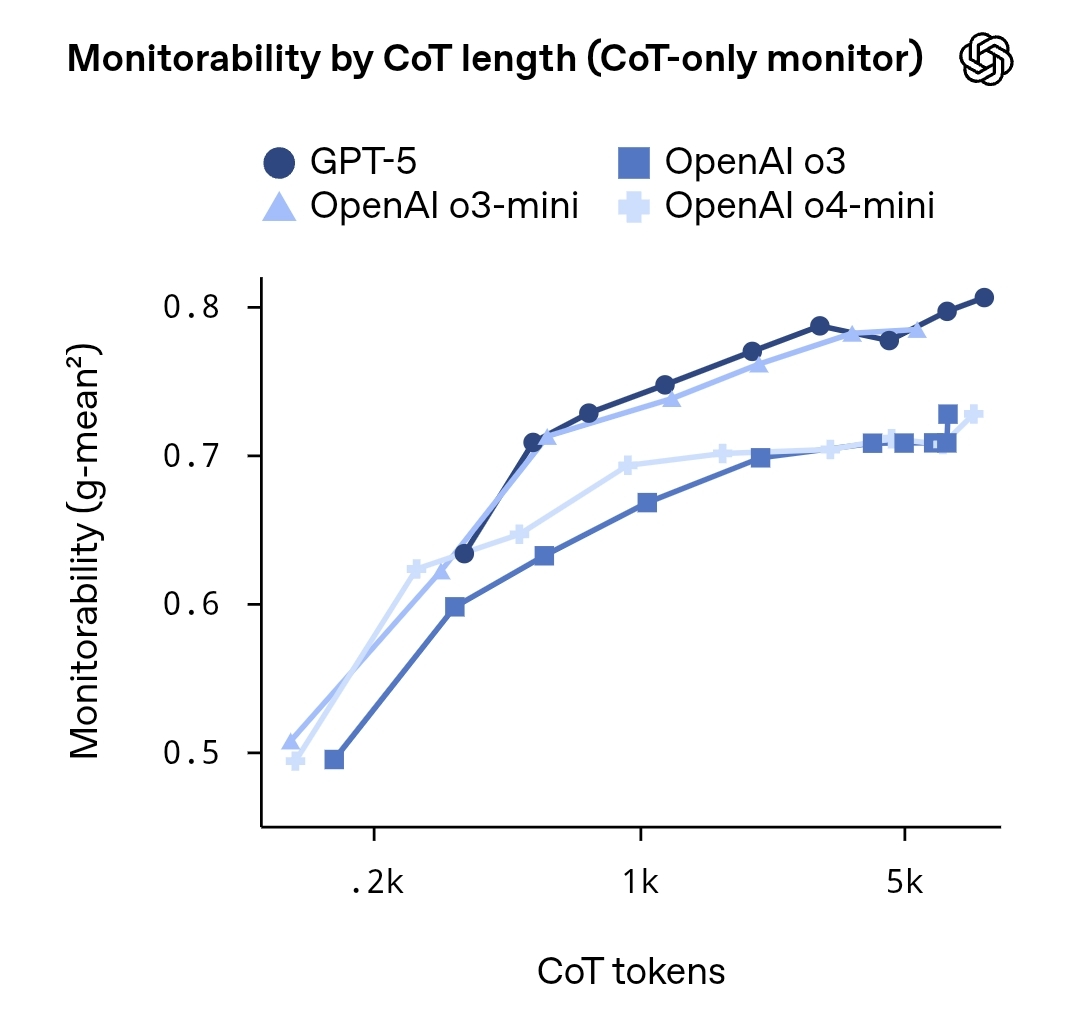
OpenAI는 "사고의 연쇄 모니터링 가능성 평가"라는 연구 보고서를 발표했으며, 이 보고서는 대형 언어 모델 내에서 "사고의 사슬"(CoT)의 모니터링 가능성과 보안 영향을 체계적으로 평가합니다. 보고서는 모델이 생성하는 추론 과정이 외부 프롬프트나 대리 모델을 통해 어느 정도 예측할 수 있지만, 완전하고 정확한 사고 경로는 여전히 매우 불확실하고 재현 불가능하다고 지적했습니다.
연구팀은 다양한 모델 크기와 과제 유형을 여러 실험에서 사용하여 "프록시 모델 모니터링"과 "암묵적 라벨링 추론 단계"를 통해 모델 사고 사슬의 투명성과 감사 가능성을 평가하는 방법을 분석했습니다. 결과는 상위 추론 대상은 부분적으로 모니터링할 수 있지만, 세부 사항에서 무작위성과 민감한 정보 유출 위험이 여전히 존재함을 보여줍니다. 보고서는 보안과 프라이버시 간의 균형을 유지할 것을 권고하며, 앞으로 특정 감독 메커니즘, 샌드박스 추론, 설명 주석 프레임워크를 통해 미션 크리티컬 시나리오에서 AI를 개선할 수 있습니다.
OpenAI는 기사 말미에 이 연구가 AI 거버넌스, 위험 감사 및 과학 연구 보안에 대한 기술적 참고 자료를 제공하는 것을 목표로 하며, 현재의 공개 모델이 내부적으로 "완전한 사고 연쇄"를 갖고 있거나 노출한다는 의미는 아니라고 강조했습니다. 이후 연구는 모델 성능에 영향을 주지 않으면서 추론 투명성과 프로세스 검증을 개선하는 방법에 초점을 맞출 것입니다.
FAQsQ: 이 연구의 주제는 무엇인가요?
A: 이 연구는 주로 대형 언어 모델 내의 '사고의 연쇄'가 모니터링, 해석 또는 부분적으로 예측될 수 있는지, 그리고 이러한 가시성의 보안적 함의를 탐구합니다.
Q: '사고의 연쇄(Chain-of-Thought)'란 무엇인가요?
답변: 답변을 생성하기 전 모델의 중간 추론 단계나 논리적 과정을 의미하며, 이는 보통 출력에 보이지 않지만 최종 결과에 영향을 미칩니다.
질문: 연구에서 도출된 주요 결론은 무엇인가요?
A: 사고의 연쇄는 부분적으로 예측할 수 있지만 완전히 재현할 수는 없으며, 무작위성, 개인정보 보호, 남용 위험이 있습니다.
Q: 왜 사고의 사슬의 모니터링 가능성을 연구하는가?
답변: AI 시스템의 보안성과 감사 가능성을 향상시키기 위해 연구자들은 중요한 작업에서 모델의 추론 행동을 더 잘 이해할 수 있습니다.
Q: 이 연구가 OpenAI가 내부 추론 메커니즘을 공개했다는 의미인가요?
A: 아니요. 이 보고서는 학술 평가 및 보안 거버넌스 참고용으로만 작성되며, 모델 내부 추론에 접근할 수 있는 인터페이스나 기능은 공개하지 않습니다.