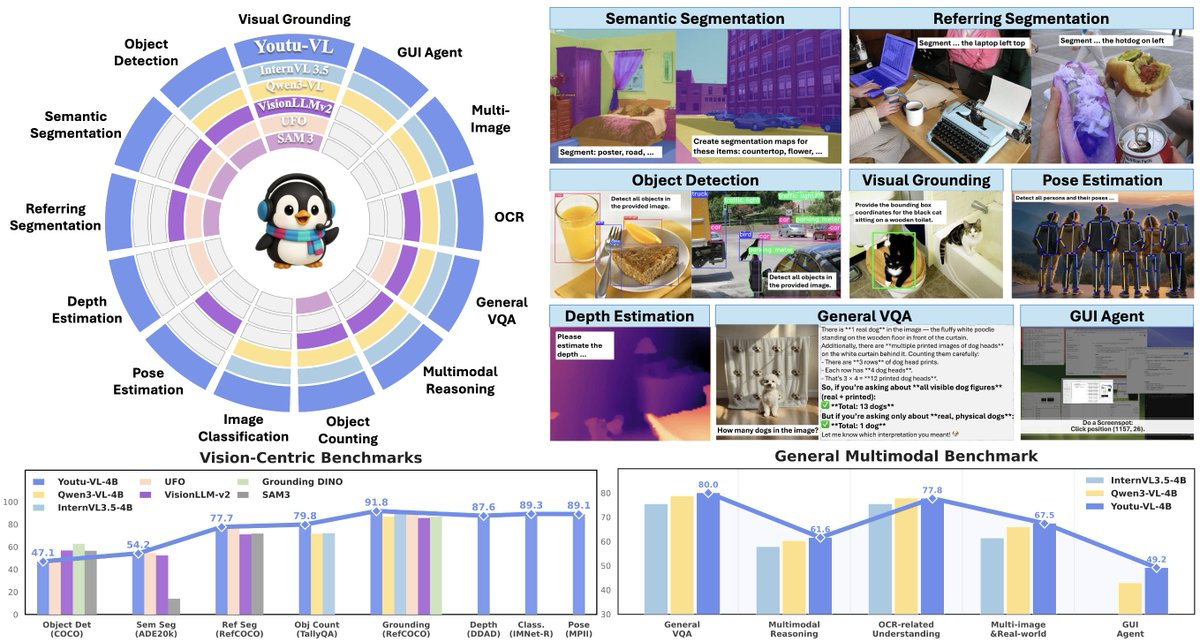
一、摘要
Youtu-VL-4B-Instruct 是腾讯优图开源的紧凑型视觉语言模型(4B 参数),核心提出 VLUAS(Vision-Language Unified Autoregressive Supervision),将“视觉从输入变为可预测目标”,以统一自回归监督保留细粒度视觉信息。其目标是在不引入任务专用头的情况下,同时覆盖通用多模态对话与以视觉为中心的感知任务,并兼顾端侧与快速推理需求。
二、核心特性
1、All-in-One 视觉感知:在标准 VLM 架构内支持检测、分割、深度估计、姿态估计等视觉任务,减少为不同任务堆叠专用模块的复杂度。
2、OCR 与文档解析:强化对复杂文档的识别与结构理解能力,适用于票据、表格、长文档要素抽取等场景。
3、多模态推理:面向几何、计数与多模态数学等“看图推理”任务做优化,强调细节与步骤一致性。
4、GUI Agent 友好:面向“世界理解+界面导航”的交互型任务设计,更适合作为界面代理的视觉底座模型。
5、效率与可部署性:4B 参数利于边缘设备或成本敏感场景;同时提供 GGUF 等形态,便于本地推理链路集成。
三、安装
1、选择模型形态:云端/服务器侧优先使用 Transformers 生态模型;端侧或本地推理优先选择 GGUF 版本。
2、环境与依赖:按官方仓库与模型卡要求安装 transformers、torch、图像处理依赖,并启用合适的注意力加速实现。
3、调用方式:以“图像+指令”的消息模板进行对话式推理;在本地推理中可使用 llama.cpp 体系加载 GGUF 进行服务化。
四、典型用例
1、通用视觉问答:图片内容理解、细节定位、复杂场景描述与多轮问答。
2、文档到结构化:复杂版面 OCR、表格理解与字段抽取,用于知识库构建与检索增强生成(RAG)。
3、视觉感知任务统一入口:在同一模型内完成检测/分割/深度/姿态等输出,便于搭建通用视觉工具链。
4、GUI 自动化:识别界面元素、理解布局并结合指令执行导航与操作(建议在受控环境与权限边界内使用)。
五、生态与竞品
1、生态:同时覆盖 Hugging Face、ModelScope 与 GitHub 工程仓库,便于训练复现、推理接入与端侧部署。
2、竞品对比思路:与更大参数的通用 VLM 相比,Youtu-VL 的卖点在“视觉感知任务统一化+小参数部署”;与传统视觉专用模型相比,优势在“对话与推理能力+统一接口”。实际选型建议以你的数据集、延迟预算与输出格式要求做 A/B 验证。
六、局限与注意事项
1、统一模型并不等于全任务最优:在极致精度需求(如高精度工业分割)仍可能需要专用模型兜底。
2、文档与 GUI 场景对数据分布敏感:不同字体、分辨率、截图压缩与主题皮肤会显著影响效果,需做域内回归测试。
3、本地推理受显存与量化影响大:GGUF/量化可降成本但可能带来细节损失,建议对关键业务样本做一致性评估。
七、项目地址
https://github.com/TencentCloudADP/youtu-vl
八、常见问题
Q:Youtu-VL-4B-Instruct 的 VLUAS 核心价值是什么?
A:把视觉信息作为预测目标纳入统一自回归监督,减少“文本主导训练”导致的视觉细节丢失,从而增强检测、分割等感知能力与细粒度理解。
Q:Youtu-VL-4B-Instruct 能否不加任务专用头完成检测与分割?
A:其设计目标是以标准架构直接支持多类视觉任务输出,但不同任务的可用性仍建议用你的指标与样本做验证。
Q:做端侧部署应该选哪个版本?
A:优先选择 GGUF 版本以接入本地推理链路;若需要与 Python 生态深度集成,则选择 Transformers 版本并结合量化/加速方案。
Q:用于文档 RAG 时如何提升可检索性?
A:建议把输出组织为“段落/表格块/关键字段”,保留页码与位置线索,并在入库前做去噪、分块与结构一致性校验。