1. 초록
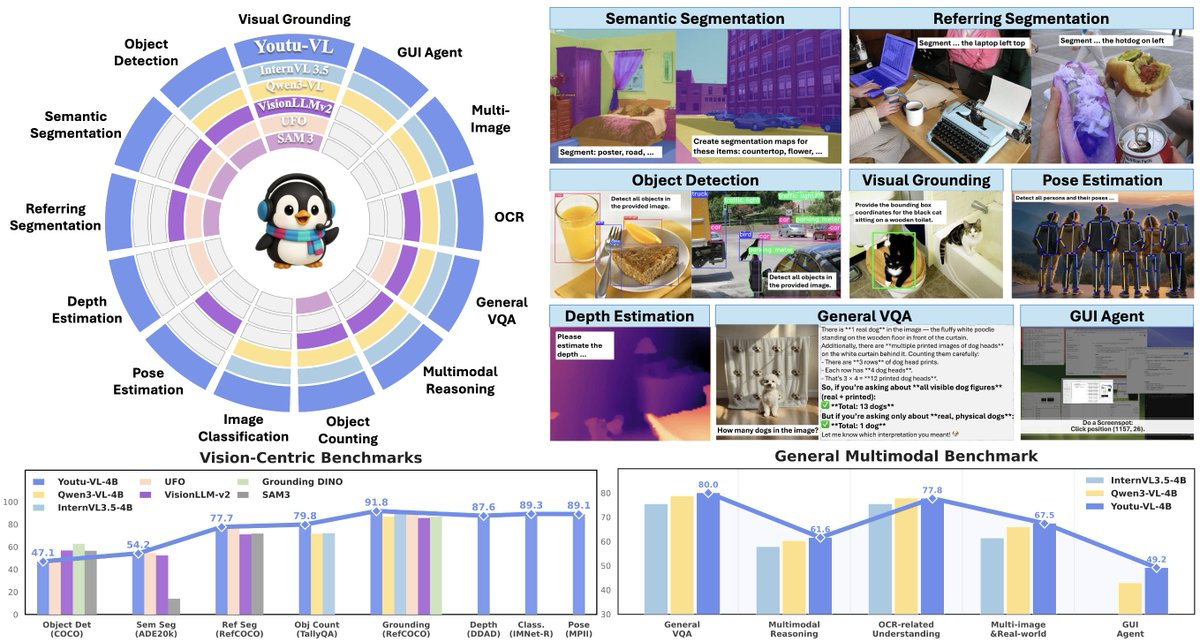
Youtu-VL-4B-Instruct는 Tencent Youtu가 제공하는 4B 매개변수 규모의 소형 시각 언어 모델로, VLUAS(Vision-Language Unified Autoregressive Supervision)를 제안합니다. 이 모델은 "입력에서 예측 가능한 목표물로 시각을 전환"하여 자기회귀 감독을 통합하여 세밀한 시각 정보를 유지합니다. 목표는 작업 특화 머리를 도입하지 않고 범용 다중 모드 대화와 비전 중심 지각 과제를 모두 포함하고, 최종 측과 빠른 추론 요구를 모두 고려하는 것입니다.
2. 핵심 특징
- 올인원 시각 인식: 표준 VLM 아키텍처 내에서 감지, 분할, 깊이 추정, 자세 추정과 같은 시각 작업을 지원하여, 다양한 작업에 대한 전용 모듈 중첩의 복잡성을 줄입니다.
- OCR 및 문서 파싱: 티켓, 테이블, 긴 문서 요소 추출과 같은 시나리오에 적합한 복잡한 문서의 인식 및 구조적 이해를 강화합니다.
- 다중 모달 추론: 기하학, 카운팅, 멀티모달 수학과 같은 '그래프 추론' 작업에 최적화하며, 세부 사항과 단계의 일관성을 강조합니다.
- GUI 에이전트 친화적: "세계 이해 + 인터페이스 내비게이션"을 위한 인터랙티브 작업 설계는 시각적 기반 모델의 인터페이스 에이전트에 더 적합합니다.
- 효율성 및 배포 가능성: 4B 매개변수는 엣지 장치나 비용 민감 시나리오에 적합하며; 또한 지역 추론 링크 통합을 용이하게 하기 위해 GGUF 및 기타 형태를 제공합니다.
3. 설치
- 모델 형태 선택: 클라우드/서버 측은 트랜스포머 생태 모델 사용에 우선권을 부여해야 합니다; 끝 측 또는 국소 추론은 GGUF 버전을 선호합니다.
- 환경 및 의존성: 공식 저장소 및 모델 카드의 요구사항에 따라 트랜스포머, 토치, 이미지 처리 의존성을 설치하고, 적절한 주의 가속 구현을 가능하게 합니다.
- 호출 방법: 대화 추론을 위해 "image + instruction" 메시지 템플릿을 사용; 국소 추론에서는 llama.cpp 시스템을 사용해 GGUF를 로딩하여 서비타이제이션을 수행할 수 있습니다.
4. 일반적인 사용 사례
- 일반 시각적 질의응답: 이미지 내용 이해, 세부 위치 파악, 복잡한 장면 설명 및 여러 라운드의 질의응답.
- 문서에서 구조로: 지식 기반 구축 및 검색 증강 생성(RAG)을 위한 OCR, 표 이해, 필드 추출.
- 시각 지각 작업의 통합 진입: 동일한 모델에서 탐지/분할/깊이/자세 출력을 완료하여 일반적인 시각 도구 체인을 구축하는 데 편리합니다.
- GUI 자동화: 인터페이스 요소를 식별하고, 레이아웃을 이해하며, 통제된 환경 및 권한 경계 내에서 권장되는 지침과 함께 내비게이션 및 작업을 수행합니다.
5. 생태와 경쟁 제품
- 생태계: Hugging Face, ModelScope, GitHub 엔지니어링 저장소를 동시에 포함하여 재현성, 추론 접근, 장치 측 배포를 쉽게 학습할 수 있습니다.
- 경쟁 제품 비교 아이디어: 더 큰 매개변수를 가진 범용 VLM과 비교할 때, 유투-VL의 판매 포인트는 "시각 인식 작업 통합 + 작은 매개변수 배포"입니다; 전통적인 비전 특화 모델과 비교할 때, 장점은 "대화와 추론 능력 + 통합 인터페이스"에 있습니다. 실제 선택 권고는 데이터셋, 지연 예산, 출력 형식 요구사항에 따라 A/B 검증됩니다.
6. 제한 및 주의사항
- 통합 모델이 전체 작업 최적을 의미하지는 않습니다: 극단적인 정확도 요구사항(예: 고정밀 산업 세분화)에서는 특수 모델이 필요할 수 있습니다.
- 문서 및 GUI 시나리오는 데이터 분포에 민감하며, 서로 다른 글꼴, 해상도, 스크린샷 압축, 테마 스킨이 효과에 큰 영향을 미치며, 도메인 내 회귀 테스트가 필요합니다.
- 국소 추론은 비디오 메모리와 양자화에 크게 영향을 받는다: GGUF/양자화는 비용을 줄일 수 있지만 세부 정보 손실을 초래할 수 있으므로, 주요 비즈니스 샘플에 대한 일관성 평가를 수행하는 것이 권장된다.
7. 프로젝트 주소
https://github.com/TencentCloudADP/youtu-vl
8. 자주 묻는 질문
Q: 유투-VL-4B-인스트럭처에서 VLUAS의 핵심 가치는 무엇인가요?
답변: 통합 자기회귀 감독에 시각 정보를 예측 대상으로 통합하여 "텍스트 주도 학습"으로 인한 시각적 세부 정보 손실을 줄여 지각 능력과 탐지 및 세분화 같은 세밀한 이해를 향상시킵니다.
Q: 유투-VL-4B-인디스트리트가 전용 작업 없이 탐지 및 분할을 완료할 수 있나요?
A: 설계 목표는 표준 아키텍처로 다양한 유형의 시각적 작업 출력을 직접 지원하는 것이지만, 여전히 다양한 작업의 가용성을 검증하기 위해 지표와 샘플을 사용하는 것이 권장됩니다.
Q: 장치 측 배포를 위해 어떤 버전을 선택해야 하나요?
A: 로컬 추론 링크에 접근하려면 GGUF 버전을 선호합니다; 파이썬 생태계와 깊이 통합하고 싶다면 Transformers 버전을 선택하고 양자화/가속 솔루션과 결합하세요.
Q: 문서 RAG에 사용할 때 검색 기능을 어떻게 개선할 수 있나요?
A: 출력물을 "단락/표 블록/키 필드"로 정리하고, 페이지 번호와 위치 단서를 유지하며, 저장 전에 노이즈 제거, 청킹, 구조적 일관성 검사를 하는 것이 권장됩니다.