1. 要旨
Youtu-VL-4B-Instructは、Tencent Youtuが提供するコンパクトな視覚言語モデル(4Bパラメータ)で、VLUAS(Vision-Language Unified Autoregressive Supervision)を提案しています。これは「視覚を入力から予測可能なターゲットへ」変換し、自己回帰監督を統一して細かな視覚情報を保持します。 目的は、汎用マルチモーダル対話と視覚中心の知覚タスクの両方を、タスク固有のヘッドを導入せずにカバーし、エンドサイドとファストサイドの両方の推論ニーズを考慮に入れることです。
2. コア機能
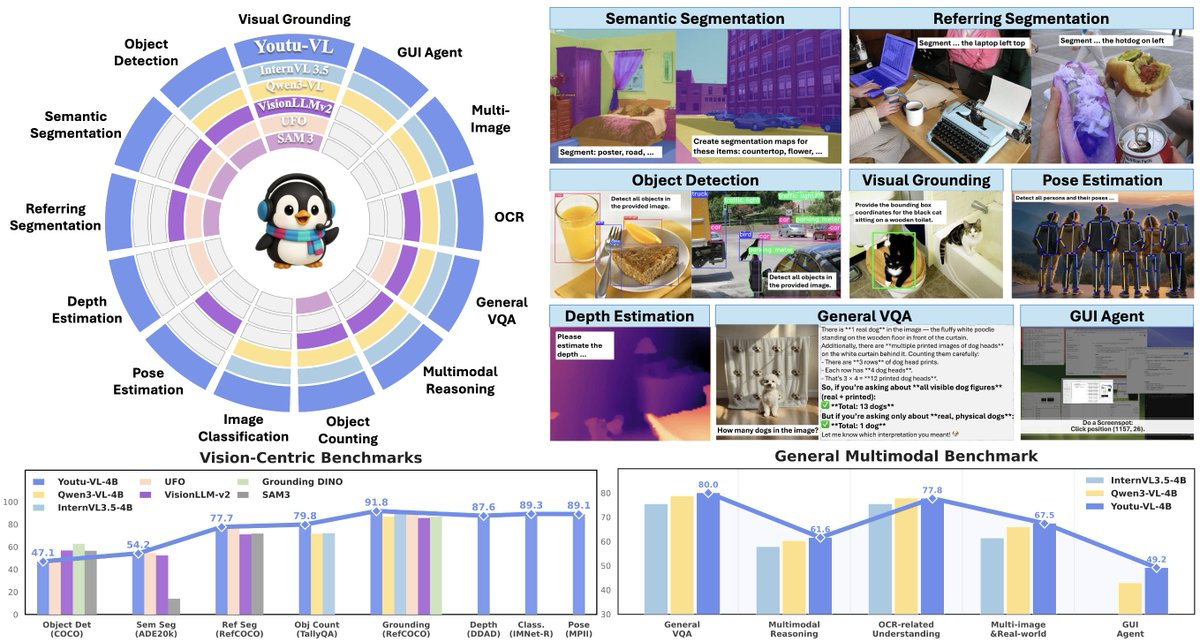
- オールインワン視覚知覚:標準VLMアーキテクチャ内での検出、セグメンテーション、奥行き推定、姿勢推定などの視覚タスクをサポートし、異なるタスクごとに専用モジュールを積み重ねる複雑さを軽減します。
- OCRと文書解析:チケット、テーブル、長い文書要素抽出などのシナリオに適した複雑な文書の認識と構造理解を強化します。
- マルチモーダル推論:幾何学、カウント、マルチモーダル数学などの「グラフ推論」タスクに最適化し、詳細やステップの一貫性を強調します。
- GUIエージェントフレンドリー:「ワールド理解+インターフェースナビゲーション」のインタラクティブタスクデザインは、インターフェースエージェントとしてのビジュアルベースモデルにより適しています。
- 効率性と展開性:4Bパラメータはエッジデバイスやコストに敏感なシナリオに適しています。 また、GGUFやその他の形式を提供し、局所推論リンクの統合を促進します。
3. 設置
- モデルフォームを選択する:クラウド/サーバー側はトランスフォーマーのエコロジカルモデルの使用を優先すべきです。 エンドサイドまたは局所推論はGGUF版を好みます。
- 環境と依存関係:公式リポジトリおよびモデルカードの要件に従ってトランスフォーマー、トーチ、画像処理の依存関係をインストールし、適切な注意加速の実装を可能にします。
- 呼び出し方法:会話推論には「image + instruction」のメッセージテンプレートを使用します。 局所推論では、llama.cppシステムを使ってGGUFをサーヴィタイズにロードできます。
4. 典型的なユースケース
- 一般的なビジュアルQ&A:画像内容の理解、詳細の位置取り、複雑なシーンの説明、複数ラウンドのQ&A。
- ドキュメントから構造への変換:OCR、テーブル理解、フィールド抽出による知識ベース構築および検索拡張生成(RAG)。
- 視覚知覚タスクの統一入口:検出/セグメンテーション/深度/姿勢の出力を同じモデル内で完了し、一般的な視覚ツールチェーンの構築に便利です。
- GUI自動化:インターフェース要素の特定、レイアウトの理解、ナビゲーションおよび操作を指示と組み合わせて実行します(制御環境および権限境界内での使用が推奨)。
5. 生態系と競合製品
- エコシステム:Hugging Face、ModelScope、GitHubのエンジニアリングリポジトリを同時にカバーし、再現性、推論アクセス、デバイス側でのデプロイを容易に訓練できます。
- 競合製品の比較アイデア:より大きなパラメータを持つ汎用VLMと比較して、Youtu-VLの売りは「視覚知覚タスクの統一+小さなパラメータ展開」です。 従来のビジョン特化モデルと比べて、その利点は「対話と推論能力+統一インターフェース」にあります。 実際の選択推奨は、データセット、レイテンシーバリュー、出力フォーマットの要件とA/Bで検証されます。
6. 制限事項と注意事項
- 統一モデルはタスク最適を意味しません:高精度な産業セグメンテーションなどの極端な精度要求では、特別なモデルが必要になることがあります。
- ドキュメントおよびGUIのシナリオはデータ配布に敏感であり、フォント、解像度、スクリーンショット圧縮、テーマスキンの違いが効果に大きく影響し、ドメイン内回帰テストが必要です。
- 局所推論はビデオメモリと量子化に大きく影響します:GGUF/量子化はコストを削減できますが、詳細の損失を招く可能性があるため、主要なビジネスサンプルの整合性評価を行うことが推奨されます。
7. プロジェクトアドレス
https://github.com/TencentCloudADP/youtu-vl
8. よくある質問
Q: Youtu-VL-4B-InstructにおけるVLUASのコアバリューは何ですか?
A: 視覚情報を予測対象として統合的自己回帰監督に組み込むことで、「テキスト主導トレーニング」による視覚的詳細の損失を減らし、知覚能力や検出・セグメンテーションなどの細かな理解を強化します。
Q: Youtu-VL-4B-Ininstructionは専用タスクなしで検出とセグメンテーションを完了できますか?
A: 設計目標は標準アーキテクチャで複数の視覚的タスク出力を直接サポートすることですが、異なるタスクの利用可能性を検証するために指標やサンプルを使用することが推奨されます。
Q: デバイスサイド展開にはどのバージョンを選ぶべきですか?
A: ローカル推論リンクにアクセスするにはGGUFバージョンを好みます。 Pythonエコシステムと深く統合したいなら、Transformers版を選び、量子化や加速ソリューションと組み合わせてください。
Q: ドキュメントRAGで使用する際、検索性をどのように向上させることができますか?
A: 出力を「段落/テーブルブロック/キーフィールド」に整理し、ページ番号や位置の手がかりを保持し、保存前にノイズ除去、チャンク化、構造の整合性チェックを行うことが推奨されます。