1. Abstract
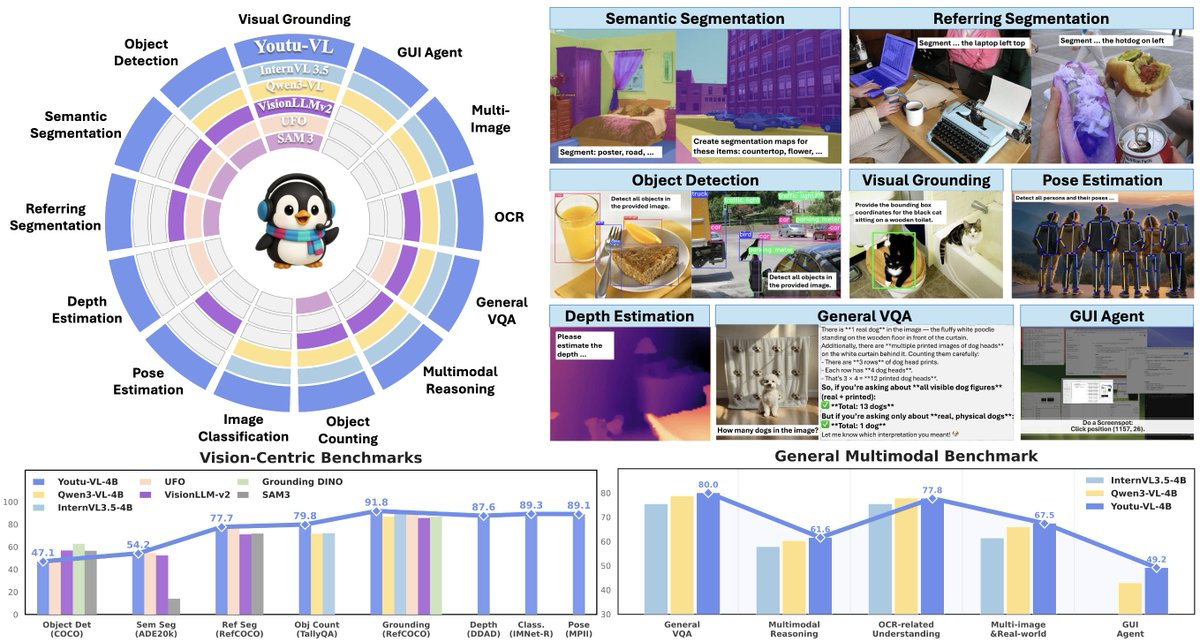
Youtu-VL-4B-Instruct is a compact visual language model (4B parameters) open source by Tencent Youtu, which proposes VLUAS (Vision-Language Unified Autoregressive Supervision), which changes "vision from input to predictable target" to unify autoregressive supervision to retain fine-grained visual information. The goal is to cover both general-purpose multimodal dialogue and vision-centric perception tasks without introducing a task-specific head, and to take into account both end-side and fast inference needs.
2. Core features
- All-in-One visual perception: supports vision tasks such as detection, segmentation, depth estimation, and pose estimation within the standard VLM architecture, reducing the complexity of stacking dedicated modules for different tasks.
- OCR and document parsing: Strengthen the recognition and structural understanding of complex documents, suitable for scenarios such as tickets, tables, and long document element extraction.
- Multimodal reasoning: Optimize for "graph reasoning" tasks such as geometry, counting and multimodal mathematics, emphasizing the consistency of details and steps.
- GUI Agent friendly: The interactive task design for "world understanding + interface navigation" is more suitable for the visual base model as an interface agent.
- Efficiency and Deployability: 4B parameters are conducive to edge devices or cost-sensitive scenarios; It also provides GGUF and other forms to facilitate local inference link integration.
3. Installation
- Select the model form: the cloud/server side should give priority to the use of the Transformers ecological model; End-side or local inference prefers the GGUF version.
- Environment and dependencies: Install transformers, torch, and image processing dependencies according to the requirements of the official repository and model card, and enable appropriate attention acceleration implementation.
- Calling method: use the message template of "image + instruction" for conversational reasoning; In local inference, you can use the llama.cpp system to load GGUF for servitization.
4. Typical use cases
- General visual Q&A: image content understanding, detail positioning, complex scene description and multiple rounds of Q&A.
- Document to Structure: OCR, table understanding, and field extraction for knowledge base construction and retrieval-augmented generation (RAG).
- Unified entrance for visual perception tasks: complete the output of detection/segmentation/depth/pose in the same model, which is convenient for building a general vision tool chain.
- GUI automation: Identify interface elements, understand layout, and perform navigation and operations in combination with instructions (recommended for use within controlled environments and permission boundaries).
5. Ecology and competing products
- Ecosystem: It covers Hugging Face, ModelScope, and GitHub engineering repositories at the same time, making it easy to train reproducibility, inference access, and device-side deployment.
- Comparison ideas of competing products: Compared with general-purpose VLM with larger parameters, Youtu-VL's selling point is "unification of visual perception tasks + small parameter deployment"; Compared with traditional vision-specific models, the advantage lies in "dialogue and reasoning capabilities + unified interface". Actual selection recommendations are A/B validated with your dataset, latency budget, and output format requirements.
6. Limitations and precautions
- Unified model does not mean full task optimum: In the extreme accuracy requirements (such as high-precision industrial segmentation), a special model may still be required.
- Document and GUI scenarios are sensitive to data distribution: different fonts, resolutions, screenshot compression, and theme skins will significantly affect the effect, and in-domain regression testing is required.
- Local inference is greatly affected by video memory and quantization: GGUF/quantization can reduce costs but may bring detail loss, so it is recommended to conduct a consistency assessment of key business samples.
7. Project address
https://github.com/TencentCloudADP/youtu-vl
8. Frequently asked questions
Q: What are the core values of VLUAS for Youtu-VL-4B-Instruct?
A: Incorporate visual information as a prediction target into unified autoregressive supervision to reduce the loss of visual details caused by "text-led training", thereby enhancing perception capabilities and fine-grained understanding such as detection and segmentation.
Q: Can Youtu-VL-4B-Instruct complete detection and segmentation without a dedicated task?
A: Its design goal is to directly support multiple types of visual task output with a standard architecture, but it is still recommended to use your metrics and samples to verify the availability of different tasks.
Q: Which version should I choose for device-side deployment?
A: Prefer the GGUF version to access the local inference link; If you need to deeply integrate with the Python ecosystem, choose the Transformers version and combine it with quantization/acceleration solutions.
Q: How can I improve searchability when used for document RAG?
A: It is recommended to organize the output into "paragraphs/table blocks/key fields", keep page numbers and position clues, and do denoising, chunking and structural consistency checks before storage.