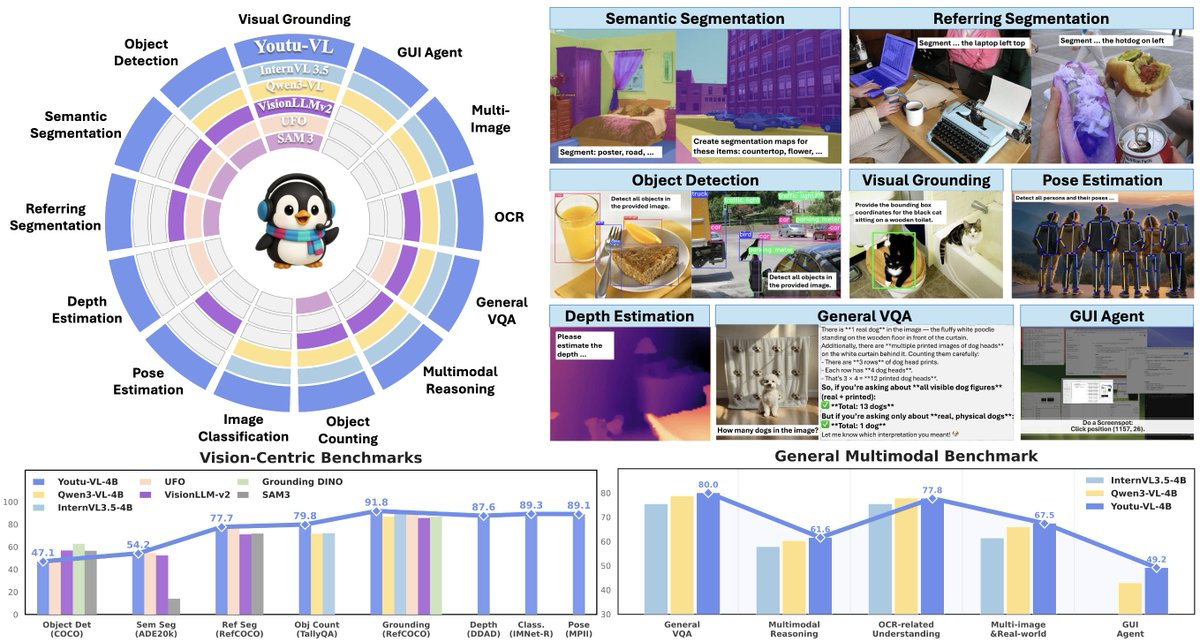
1. Résumé
Youtu-VL-4B-Instruct est un modèle de langage visuel compact (paramètres 4B) open source développé par Tencent Youtu, qui propose VLUAS (Vision-Language Unified Autoregressive Supervision), qui modifie « la vision d’entrée à cible prévisible » afin d’unifier la supervision autorégressive afin de conserver des informations visuelles très détaillées. L’objectif est de couvrir à la fois le dialogue multimodal général et les tâches de perception centrées sur la vision sans introduire de tête spécifique à chaque tâche, et de prendre en compte à la fois les besoins d’inférence finale, et rapide.
2. Caractéristiques principales
- Perception visuelle tout-en-un : prend en charge des tâches visuelles telles que la détection, la segmentation, l’estimation de la profondeur et l’estimation de la pose dans l’architecture VLM standard, réduisant ainsi la complexité de l’empilement de modules dédiés pour différentes tâches.
- OCR et analyse syntaxique des documents : renforcer la reconnaissance et la compréhension structurelle de documents complexes, adaptés à des scénarios tels que les tickets, les tables et l’extraction longue d’éléments de documents.
- Raisonnement multimodal : Optimiser pour les tâches de « raisonnement en graphes » telles que la géométrie, le comptage et les mathématiques multimodales, en mettant l’accent sur la cohérence des détails et des étapes.
- Compatible avec l’agent graphique graphique : La conception interactive des tâches pour « compréhension du monde + navigation d’interface » est plus adaptée au modèle de base visuelle en tant qu’agent d’interface.
- Efficacité et capacité à déployer : les paramètres 4B sont adaptés aux dispositifs en périphérie ou aux scénarios sensibles au coût ; Il fournit également GGUF et d’autres formulaires pour faciliter l’intégration locale des liens d’inférence.
3. Installation
- Sélectionnez la forme du modèle : le côté cloud/serveur doit donner la priorité à l’utilisation du modèle écologique Transformers ; L’inférence finale ou locale préfère la version GGUF.
- Environnement et dépendances : Installer des transformateurs, des chalumeaux et des dépendances de traitement d’image selon les exigences du dépôt officiel et de la carte modèle, et permettre une mise en œuvre appropriée de l’accélération de l’attention.
- Méthode d’appel : utiliser le modèle de message « image + instruction » pour le raisonnement conversationnel ; En inférence locale, vous pouvez utiliser le système llama.cpp pour charger GGUF pour la servitisation.
4. Cas d’usage typiques
- Questions et réponses visuelles générales : compréhension du contenu des images, positionnement des détails, description complexe de scènes et plusieurs phases de questions-réponses.
- Document to Structure : OCR, compréhension de table, et extraction de champ pour la construction de bases de connaissances et la génération augmentée par récupération (RAG).
- Entrée unifiée pour les tâches de perception visuelle : compléter la sortie de détection/segmentation/profondeur/pose dans le même modèle, ce qui est pratique pour constituer une chaîne d’outils de vision générale.
- Automatisation de l’interface graphique : Identifier les éléments d’interface, comprendre la mise en page, et effectuer la navigation et les opérations en combinaison avec des instructions (recommandées pour une utilisation dans des environnements contrôlés et des limites d’autorisation).
5. Écologie et produits concurrents
- Écosystème : Il couvre simultanément les dépôts d’ingénierie Hugging Face, ModelScope et GitHub, facilitant l’entraînement à la reproductibilité, à l’accès par inférence et au déploiement côté appareil.
- Idées de comparaison de produits concurrents : Comparé au VLM à usage général avec des paramètres plus grands, le argument de vente de Youtu-VL est « l’unification des tâches de perception visuelle + déploiement de petits paramètres » ; Comparé aux modèles traditionnels spécifiques à la vision, l’avantage réside dans les « capacités de dialogue et de raisonnement + interface unifiée ». Les recommandations de sélection réelles sont validées A/B avec votre jeu de données, votre budget de latence et les exigences du format de sortie.
6. Limitations et précautions
- Un modèle unifié ne signifie pas un optimal de tâche complet : dans les exigences extrêmes de précision (comme la segmentation industrielle à haute précision), un modèle spécial peut encore être nécessaire.
- Les scénarios de documents et d’interface graphique sont sensibles à la distribution des données : différentes polices, résolutions, compression de capture d’écran et skins de thème auront un impact significatif sur l’effet, et des tests de régression dans le domaine sont nécessaires.
- L’inférence locale est fortement influencée par la mémoire vidéo et la quantification : GGUF/quantification peut réduire les coûts mais entraîner une perte de détails, il est donc recommandé de réaliser une évaluation de cohérence des échantillons clés de l’entreprise.
7. Adresse du projet
https://github.com/TencentCloudADP/youtu-vl
8. Questions fréquemment posées
Q : Quelles sont les valeurs fondamentales de VLUAS pour Youtu-VL-4B-Instruct ?
R : Intégrer l’information visuelle comme cible de prédiction dans la supervision autorégressive unifiée afin de réduire la perte de détails visuels causée par la « formation guidée par le texte », améliorant ainsi les capacités de perception et la compréhension fine telle que la détection et la segmentation.
Q : Youtu-VL-4B-Instruct peut-il effectuer une détection et une segmentation complètes sans une tâche dédiée ?
R : Son objectif de conception est de supporter directement plusieurs types de sorties de tâches visuelles avec une architecture standard, mais il est toujours recommandé d’utiliser vos métriques et échantillons pour vérifier la disponibilité de différentes tâches.
Q : Quelle version dois-je choisir pour le déploiement côté appareil ?
R : Préfère la version GGUF pour accéder au lien d’inférence local ; Si vous devez vous intégrer profondément à l’écosystème Python, choisissez la version Transformers et combinez-la avec des solutions de quantification/accélération.
Q : Comment puis-je améliorer la recherchabilité lorsqu’on l’utilise pour le document RAG ?
R : Il est recommandé d’organiser la sortie en « paragraphes/blocs de table/champs clés », de conserver les numéros de page et les indices de position, et de faire des vérifications de réduction du bruit, de chunkage et de cohérence structurelle avant le stockage.