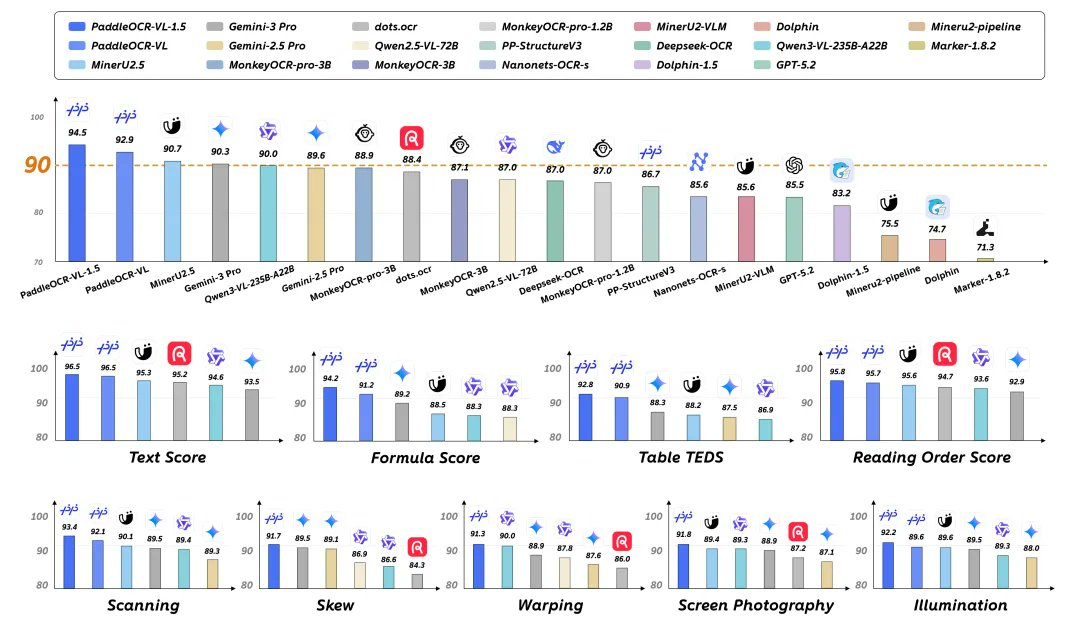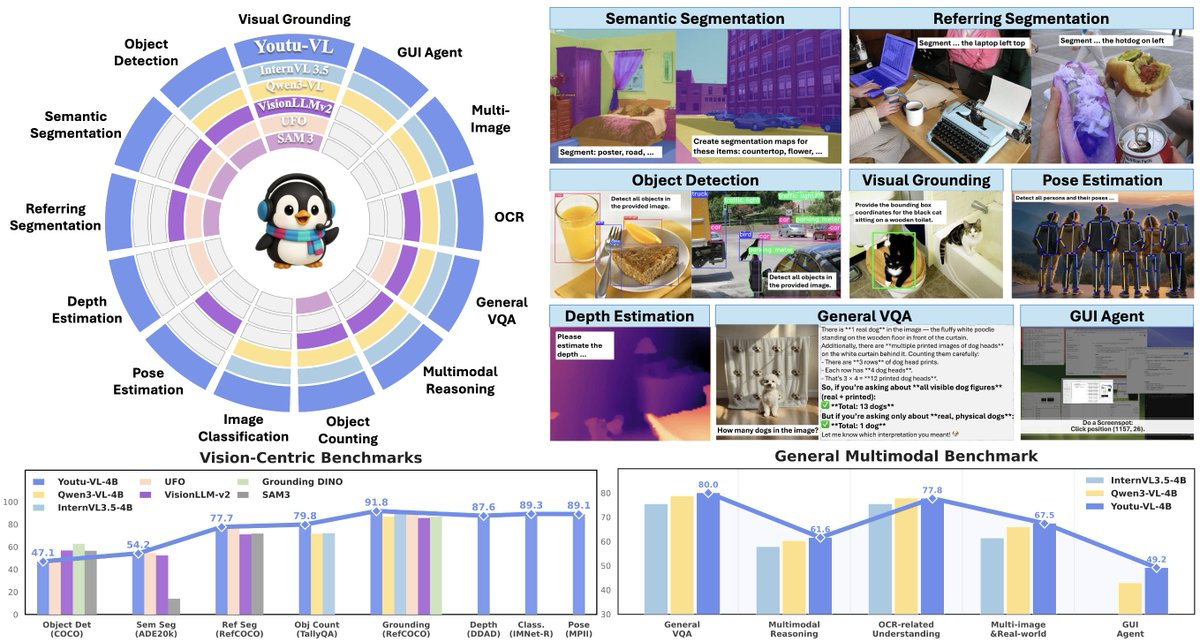
1. Zusammenfassung
Youtu-VL-4B-Instruct ist ein kompaktes visuelles Sprachmodell (4B-Parameter) als Open Source von Tencent Youtu, das VLUAS (Vision-Language Unified Autoregressive Supervision) vorschlägt, das "Vision von Eingabe zu vorhersehbarem Ziel" ändert, um autoregressive Überwachung zu vereinheitlichen und feingranuläre visuelle Informationen zu erhalten. Das Ziel ist es, sowohl allgemeine multimodale Dialogaufgaben als auch visionszentrierte Wahrnehmungsaufgaben abzudecken, ohne einen aufgabenspezifischen Kopf einzuführen, und sowohl Endseiten- als auch Schnellinferenzbedürfnisse zu berücksichtigen.
2. Kernmerkmale
- All-in-One visuelle Wahrnehmung: unterstützt Visionsaufgaben wie Erkennung, Segmentierung, Tiefenschätzung und Pose-Schätzung innerhalb der Standard-VLM-Architektur und reduziert so die Komplexität des Stapelns dedizizierter Module für verschiedene Aufgaben.
- OCR und Dokumentparsing: Stärkung der Erkennung und des strukturellen Verständnisses komplexer Dokumente, geeignet für Szenarien wie Tickets, Tabellen und die Extraktion von langen Dokumentelementen.
- Multimodales Schließen: Optimierung für "Graphen-Reasoning"-Aufgaben wie Geometrie, Zählen und multimodale Mathematik, wobei die Konsistenz von Details und Schritten betont wird.
- GUI-Agentenfreundlich: Das interaktive Aufgabendesign für "Weltverständnis + Schnittstellennavigation" eignet sich besser für das visuelle Basismodell als Schnittstellenagent.
- Effizienz und Einsatzbereitschaft: 4B-Parameter sind förderlich für Randgeräte oder kostenempfindliche Szenarien; Es bietet außerdem GGUF und andere Formulare zur Erleichterung der Integration lokaler Inferenzverbindungen.
3. Installation
- Wählen Sie die Modellform aus: Die Cloud-/Serverseite sollte der Nutzung des Transformers-ökologischen Modells Priorität einräumen; Endseitige oder lokale Inferenz bevorzugt die GGUF-Version.
- Umgebung und Abhängigkeiten: Installieren Sie Transformatoren, Brenner und Bildverarbeitungsabhängigkeiten entsprechend den Anforderungen des offiziellen Repositorys und der Modellkarte und ermöglichen Sie eine angemessene Implementierung der Aufmerksamkeitsbeschleunigung.
- Anrufmethode: Verwendung der Nachrichtenvorlage "Bild + Instruktion" für das konversationelle Denken; In der lokalen Inferenz kann man das llama.cpp-System verwenden, um GGUF für die Servitisierung zu laden.
4. Typische Anwendungsfälle
- Allgemeine visuelle Frage-und-Antwort-Frage: Verständnis von Bildinhalten, Detailpositionierung, komplexe Szenenbeschreibung und mehrere Fragerunden.
- Dokument-zu-Struktur: OCR, Tabellenverständnis und Feldextraktion für den Aufbau von Wissensbasen und zur Generierung von Retrieval-Augmented (RAG).
- Einheitlicher Eingang für visuelle Wahrnehmungsaufgaben: Erledigen Sie die Ergebnisse von Erkennung/Segmentierung/Tiefe/Pose im selben Modell, was praktisch ist, um eine allgemeine Vision-Werkzeugkette aufzubauen.
- GUI-Automatisierung: Interface-Elemente identifizieren, Layout verstehen und Navigation sowie Operationen in Kombination mit Anweisungen durchführen (empfohlen für die Nutzung in kontrollierten Umgebungen und Berechtigungsgrenzen).
5. Ökologie und konkurrierende Produkte
- Ökosystem: Es deckt gleichzeitig Hugging Face, ModelScope und GitHub-Engineering-Repositories ab, was es einfach macht, Reproduzierbarkeit, Inferenzzugriff und geräteseitigen Deployment zu trainieren.
- Vergleichsideen konkurrierender Produkte: Im Vergleich zu universellen VLM mit größeren Parametern ist das Verkaufsargument von Youtu-VL die "Vereinheitlichung visueller Wahrnehmungsaufgaben + kleine Parameterverteilung"; Im Vergleich zu traditionellen, visionsspezifischen Modellen liegt der Vorteil in "Dialog- und Schlussfähigkeiten + einheitliche Benutzeroberfläche". Die tatsächlichen Auswahlempfehlungen werden A/B mit deinem Datensatz, deinem Latenzbudget und den Anforderungen an das Ausgabeformat validiert.
6. Einschränkungen und Vorsichtsmaßnahmen
- Ein einheitliches Modell bedeutet nicht das vollständige Auftragsoptimum: Bei extremen Genauigkeitsanforderungen (wie hochpräziser industrieller Segmentierung) kann dennoch ein spezielles Modell erforderlich sein.
- Dokument- und GUI-Szenarien sind empfindlich gegenüber der Datenverteilung: Unterschiedliche Schriftarten, Auflösungen, Screenshot-Kompression und Theme-Skins beeinflussen den Effekt erheblich, und In-domain-Regressionstests sind erforderlich.
- Lokale Inferenz wird stark durch Videospeicher und Quantisierung beeinflusst: GGUF/Quantisierung kann Kosten senken, aber Detailverluste verursachen, daher wird empfohlen, eine Konsistenzbewertung wichtiger Geschäftsproben durchzuführen.
7. Projektadresse
https://github.com/TencentCloudADP/youtu-vl
8. Häufig gestellte Fragen
F: Was sind die Kernwerte von VLUAS für Youtu-VL-4B-Instruct?
A: Integrieren Sie visuelle Informationen als Vorhersageziel in die einheitliche autoregressive Überwachung, um den Verlust visueller Details durch "textgeleitetes Training" zu verringern und so die Wahrnehmungsfähigkeiten und ein feines Verständnis wie Erkennung und Segmentierung zu verbessern.
F: Kann Youtu-VL-4B-Instruct die Erkennung und Segmentierung komplett ohne eine eigene Aufgabe durchführen?
A: Das Designziel ist es, mehrere Arten visueller Aufgabenausgaben direkt mit einer Standardarchitektur zu unterstützen, aber es wird dennoch empfohlen, Ihre Metriken und Beispiele zu verwenden, um die Verfügbarkeit verschiedener Aufgaben zu überprüfen.
F: Welche Version sollte ich für die geräteseitige Bereitstellung wählen?
A: Bevorzugen Sie die GGUF-Version, um auf die lokale Inferenzverbindung zuzugreifen; Wenn du dich tief in das Python-Ökosystem integrieren musst, wähle die Transformers-Version und kombiniere sie mit Quantisierungs- und Beschleunigungslösungen.
F: Wie kann ich die Durchsuchbarkeit verbessern, wenn ich sie für Dokument-RAG nutze?
A: Es wird empfohlen, die Ausgabe in "Absätze/Tabellenblöcke/Schlüsselfelder" zu organisieren, Seitenzahlen und Positionshinweise zu speichern und vor der Speicherung Denoising-, Chunking- und strukturelle Konsistenzprüfungen durchzuführen.