一、摘要
QwenLong-L1.5 是通义智文团队在 Qwen-Doc 仓库中开源的一套“长上下文推理 + 记忆管理”后训练方案(post-training recipe)。它围绕三件事展开:面向长文档的复杂推理数据合成、面向长序列的强化学习稳定训练方法(AEPO 等)、以及在超出物理上下文窗口时仍可工作的记忆管理框架,并发布了对应模型 QwenLong-L1.5-30B-A3B(基于 Qwen3-30B-A3B-Thinking)。
二、核心特性
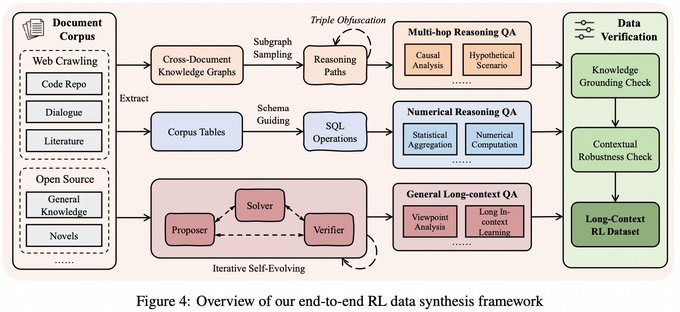
1、长上下文推理数据合成:通过“原子事实分解 + 可验证组合”的方式,生成需要多跳证据串联的长文档推理样本,而不止是简单检索式任务。
2、长序列 RL 稳定训练:引入任务均衡采样等策略,并提出 AEPO(Adaptive Entropy-Controlled Policy Optimization),用熵相关机制调控训练过程,缓解长上下文 RL 常见的不稳定问题。
3、记忆管理与超长输入:在模型物理窗口内做单次推理(示例中提到 256K 窗口),并结合迭代式记忆更新,把可处理范围扩展到百万级、甚至更长的输入流(论文描述覆盖 1M–4M token 级任务)。
4、开源可复现:提供模型权重与配套依赖说明,便于研究者复现实验或做二次开发(模型许可证为 Apache-2.0,具体以仓库/模型卡为准)。
三、安装
1、创建环境(示例):conda create -n qwenlongl1_5 python==3.10 && conda activate qwenlongl1_5
2、安装依赖:在对应目录执行 pip3 install -r requirements.txt(以实际文件为准)。
3、安装 RL 训练库:按项目推荐安装 verl(示例为克隆 volcengine/verl 并切到 v0.4 后 pip3 install -e .)。
4、推理侧依赖:使用 Transformers 加载模型与 tokenizer(也可按你的推理框架调整 device_map、dtype 等)。
四、典型用例
1、长文档问答(DocQA):对技术文档、合规材料、论文/报告做跨段落多跳推理与答案归因。
2、超长材料“读完再答”:输入规模超过单次上下文时,采用记忆代理式流程做分段阅读、记忆更新与最终综合回答。
3、企业知识分析:对年度报告、招投标文件、需求文档做结构化要点提取、冲突检测与一致性核对。
4、研究复现与训练实践:用于探索长上下文 RL 的采样策略、奖励设计、训练稳定性与评测体系。
五、生态与竞品
1、同仓库生态:Qwen-Doc 还包含 QwenLong-L1(更早的长上下文 RL 探索)与 SPELL(自博弈式 RL 框架)等方向,适合对“数据—训练—Agent”全链路做对照实验。
2、与 RAG/压缩方案的关系:RAG 更偏“检索命中率与上下文拼接”,而 QwenLong-L1.5 更强调“读长文本后的推理能力与记忆过程”;在工程上二者可结合(先检索,再做长推理/记忆总结)。
3、竞品参考:闭源长上下文模型与各类开源长上下文微调/稀疏注意力/压缩方法各有取舍;QwenLong-L1.5 的差异点在于把“长推理数据合成 + 长序列 RL 稳定训练 + 记忆代理”作为一套后训练配方整体给出。
六、局限与注意事项
1、算力与时延:长序列推理与 RL 训练都更吃显存/吞吐,尤其在 256K 级窗口或记忆代理循环下,成本会明显上升。
2、记忆并非“绝对正确”:记忆更新可能引入遗漏与偏差,关键场景建议保留证据追溯与人工复核机制。
3、训练复现门槛:RL 的奖励、采样与超参对结果敏感;不同集群/推理后端也可能影响稳定性。
4、评测外推风险:基准提升不等于所有真实文档任务都提升,落地前应做领域数据回归与安全评估。
七、项目地址
https://github.com/Tongyi-Zhiwen/Qwen-Doc/tree/main/QwenLong-L1.5
八、常见问题
Q: QwenLong-L1.5 的核心关键词“长上下文推理”具体解决什么问题?
A: 主要面向“跨章节、多证据、多跳推理”的长文档任务,目标是让模型不仅能检索到片段,还能在长范围内完成链式推理与一致性判断。
Q: QwenLong-L1.5 的 AEPO 是什么,和常见 PPO 有何关系?
A: AEPO 属于为长上下文训练稳定性设计的策略优化方法之一,通过熵相关机制调节探索与更新强度;它与 PPO 同属策略优化范式,但实现细节与稳定化手段不同(以论文与代码实现为准)。
Q: QwenLong-L1.5-30B-A3B 需要多长上下文窗口才能用?
A: 模型以“物理窗口 + 记忆机制”组合工作;示例材料提到在 256K 窗口内做单次推理,并可通过记忆代理扩展到更长输入。实际可用长度取决于推理框架、显存与配置。
Q: 我只想做推理,不做训练,如何最快上手 QwenLong-L1.5?
A: 直接用 Transformers 从模型仓库加载权重与 tokenizer,准备长文本与问题提示词即可;若要复现记忆代理流程,再参考项目配套脚本与论文描述。
Q: QwenLong-L1.5 和 RAG 应该二选一吗?
A: 不必。RAG 解决“找得到”,QwenLong-L1.5 强调“读得懂、推得远、记得住”;工程实践中常见组合是“检索缩小范围 + 长推理/记忆总结完成复杂问答”。