1. Zusammenfassung
QwenLong-L1.5 ist ein Set von "Long Context Reasoning + Memory Management"-Rezepten nach dem Training, das das Tongyi Zhiwen-Team im Qwen-Doc-Repository als Open Source veröffentlicht hat. Es dreht sich um drei Dinge: die Synthese komplexer Inferenzdaten für lange Dokumente, Reinforcement Learning Stable Training Methods (AEPO usw.) für lange Sequenzen sowie Speichermanagement-Frameworks, die weiterhin außerhalb des physischen Kontextfensters funktionieren; das entsprechende Modell QwenLong-L1.5-30B-A3B (basierend auf Qwen3-30B-A3B-Thinking) wurde veröffentlicht.
2. Kernmerkmale
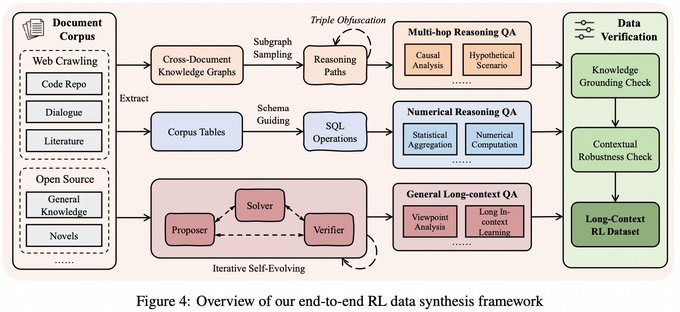
- Langkontext-Inferenzdaten-Synthese: Durch die Methode der "atomaren Faktenzerlegung + verifizierbarer Kombination" werden Proben für lange Dokument-Argumentationen, die eine Mehrfach-Evidenz-Verkettung erfordern, erzeugt, nicht nur einfache Abrufaufgaben.
- Langsequenz-RL-stabiles Training: Strategien wie aufgabenbalancierte Stichproben werden eingeführt, und AEPO (Adaptive Entropy-Controlled Policy Optimization) wird vorgeschlagen, um den Trainingsprozess mit entropiebezogenen Mechanismen zu regulieren, um die häufigen Instabilitätsprobleme von Long-Context RL zu lindern.
- Speicherverwaltung und ultralange Eingaben: Eine einzelne Inferenz im physischen Fenster des Modells (im Beispiel erwähntes 256K-Fenster) durchführen und sie mit iterativen Speicherupdates kombinieren, um den Verarbeitungsbereich auf Millionen oder sogar längere Eingabeströme zu erweitern (die Artikelbeschreibung behandelt Aufgaben auf Token-Ebene von 1M-4M).
- Open-Source-Reproduzierbare: Bereitstellung von Modellgewichten und unterstützenden Abhängigkeitsbeschreibungen, um Forschern zu ermöglichen, Experimente zu reproduzieren oder Sekundärentwicklungen durchzuführen (die Modelllizenz ist Apache-2.0, die jeweilige Repository-/Modellkarte hat Vorrang).
3. Installation
1. Erstelle eine Umgebung (Beispiel): conda create -n qwenlongl1_5 python==3.10 && conda activate qwenlongl1_5
2. Installationsabhängigkeiten: Führen Sie pip3 install -r requirements.txt im entsprechenden Verzeichnis aus (vorbehaltlich der tatsächlichen Datei).
3. Installiere die RL-Trainingsbibliothek: Installiere die verl gemäß der Empfehlung des Projekts (zum Beispiel Klonen volcengine/verl und das Schneiden auf die pip3 install -e . nach v0.4).
- Inferenz-Seitenabhängigkeiten: Nutze Transformers, um Modelle und Tokenizer zu laden (du kannst auch device_map, dtype usw. entsprechend deinem Inferenz-Framework anpassen).
4. Typische Anwendungsfälle
- Lange Dokumenten-Q&A (DocQA): Querabsatzübergreifende Multi-Hop-Argumentation und Antwortzuweisung zu technischen Dokumenten, Compliance-Materialien und Papieren/Berichten.
- "Lesen und beantworten"-ultralange Materialien: Wenn die Eingabeskala einen einzelnen Kontext überschreitet, wird der Speicheragentenprozess für segmentierte Lesen, Speicheraktualisierung und endgültige umfassende Antwort verwendet.
- Unternehmenswissensanalyse: Strukturelle Schlüsselpunkt-Extraktion, Konflikterkennung und Konsistenzprüfung in Jahresberichten, Ausschreibungsunterlagen und Nachfragedokumenten.
- Forschungsreproduktion und Trainingspraxis: Verwendet zur Untersuchung der Stichprobenstrategie, des Belohnungsdesigns, der Trainingsstabilität und des Bewertungssystems des Langkontext-RL.
5. Ökologie und konkurrierende Produkte
- Dasselbe Repository-Ökosystem: Qwen-Doc umfasst auch QwenLong-L1 (frühere Langkontext-RL-Exploration) und SPELL (Self-Game RL-Framework), das sich für vergleichende Experimente mit der "Data-Training-Agent"-Vollverbindung eignet.
- Beziehung zum RAG/Kompressionsschema: RAG ist eher "Abruf-Trefferrate und Kontext-Splicing", während QwenLong-L1.5 "Schlussfähigkeit und Gedächtnisprozess nach dem Lesen von langen Texten" betont; Beides kann in der Technik kombiniert werden (zuerst Abruf, dann lange Argumentations-/Gedächtniszusammenfassung).
- Wettbewerbsproduktreferenz: Closed-Source-Langkontextmodelle und verschiedene Open-Source-Methoden zur Feinabstimmung/Sparse Attention/Kompression haben ihre eigenen Kompromisse; Der Unterschied von QwenLong-L1.5 besteht darin, dass "Long Inference Data Synthese + Long Sequence RL stable Training + Speicheragent" als Satz von Post-Training-Formeln angegeben ist.
6. Einschränkungen und Vorsichtsmaßnahmen
- Rechenleistung und Latenz: Lange Sequenzinferenz und RL-Training bieten mehr Speicher/Durchsatz, besonders in 256K-Fenstern oder Speicherproxy-Schleifen, die Kosten steigen erheblich.
- Das Gedächtnis ist nicht "absolut korrekt": Gedächtnisaktualisierung kann Auslassungen und Abweichungen verursachen, und es wird empfohlen, in wichtigen Szenarien Rückverfolgbarkeit und manuelle Überprüfungsmechanismen zu bewahren.
- Trainingsreproduktionsschwelle: RLs Belohnungen, Stichproben und Superparameter sind ergebnissensitiv. Verschiedene Cluster/Inferenz-Backends können ebenfalls die Stabilität beeinflussen.
- Extrapolationsrisiken bewerten: Benchmark-Verbesserung bedeutet nicht, dass alle realen Dokumentaufgaben verbessert werden, und die Regression und Sicherheitsbewertung von Domänendaten sollten vor der Implementierung erfolgen.
7. Projektadresse
https://github.com/Tongyi-Zhiwen/Qwen-Doc/tree/main/QwenLong-L1.5
8. Häufig gestellte Fragen
F: Welches Problem löst QwenLong-L1.5?
A: Vor allem für lange Dokumentaufgaben wie "Cross-Chapter, Multi-Evidence, Multi-Hop Reasoning" ist das Ziel, das Modell nicht nur Fragmente abzurufen, sondern auch Kettenschlussfolgerungen und Konsistenzurteile über einen langen Zeitraum, abzuschließen.
F: Was ist die AEPO von QwenLong-L1.5 und wie hängt sie mit gängigen PPOs zusammen?
A: AEPO ist eine der Strategienoptimierungsmethoden, die für die Stabilität des Langkontexttrainings entwickelt wurden, welche die Erkundungs- und Aktualisierungsintensität durch entropiebezogene Mechanismen reguliert. Sie gehört zum gleichen Strategieoptimierungsparadigma wie PPO, aber die Implementierungsdetails und Stabilisierungsmethoden unterscheiden sich (vorbehaltlich der Implementierung von Papier und Code).
F: Wie lange benötigt das QwenLong-L1.5-30B-A3B für das Kontextfenster?
A: Das Modell funktioniert in einer Kombination aus "physikalischem Fenster + Speicher"-Mechanismus; Das Beispielmaterial erwähnt eine einzelne Inferenz in einem 256K-Fenster und kann mit einem Speicher-Proxy auf längere Eingaben erweitert werden. Die tatsächliche verfügbare Länge hängt vom Inferenzrahmen, Speicher und Konfiguration ab.
F: Ich möchte einfach nur argumentieren, nicht trainieren, wie kann ich am schnellsten mit QwenLong-L1.5 anfangen?
A: Verwenden Sie Transformers direkt, um Gewichte und Tokenizer aus dem Modelllager zu laden, und bereiten Sie lange Text- und Fragestellungen vor. Um den Speicherproxy-Prozess zu reproduzieren, verweisen Sie auf das Projekt, das Skript- und Papierbeschreibung unterstützt.
F: Sollte ich mich zwischen QwenLong-L1.5 und RAG entscheiden?
A: Nicht unbedingt. RAG löst das Problem des "Findens", und QwenLong-L1.5 betont "Lesen und Verstehen, weit gehen und erinnern"; Eine gängige Kombination in der Ingenieurpraxis ist "Retrieval-Narrowing + Long Reasoning/Memory Summarization, um komplexe Fragen und Antworten zu lösen".