1. Résumé
QwenLong-L1.5 est un ensemble de recette post-entraînement « raisonnement à long contexte + gestion de la mémoire » que l’équipe Tongyi Zhiwen a rendu open source dans le dépôt Qwen-Doc. Il repose sur trois éléments : la synthèse complexe de données d’inférence pour de longs documents, l’apprentissage par renforcement des méthodes d’entraînement stable (AEPO, etc.) pour de longues séquences, et des cadres de gestion de la mémoire qui fonctionnent encore en dehors de la fenêtre de contexte physique, et le modèle correspondant QwenLong-L1.5-30B-A3B (basé sur Qwen3-30B-A3B-Thinking) a été publié.
2. Caractéristiques principales
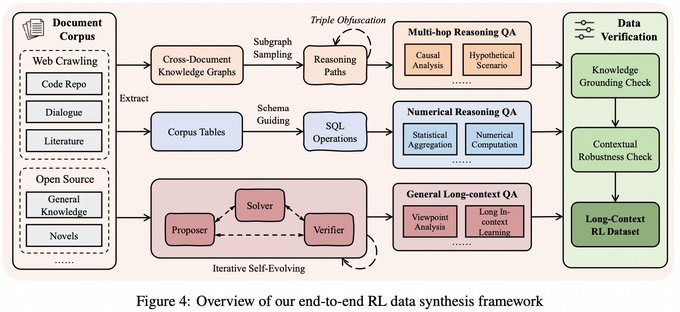
- Synthèse des données par inférence contextuelle longue : Par la méthode « décomposition atomique des faits + combinaison vérifiable », des échantillons de raisonnement de documents longs nécessitant une concaténation de preuves multi-sauts sont générés, et non seulement des tâches de récupération simples.
- Entraînement stable RL en longue séquence : Des stratégies telles que l’échantillonnage équilibré des tâches sont introduites, et AEPO (Optimisation Politique Contrôlée par Entropie Adaptative) est proposé pour réguler le processus d’entraînement avec des mécanismes liés à l’entropie afin d’atténuer les problèmes d’instabilité courants du RL à long contexte.
- Gestion de la mémoire et entrée ultra-longue : effectuer une seule inférence dans la fenêtre physique du modèle (fenêtre de 256K mentionnée dans l’exemple), et la combiner avec des mises à jour itératives de la mémoire pour étendre la plage de traitement à des millions ou même plus de flux d’entrée (la description de l’article couvre 1M-4M de tâches au niveau des jetons).
- Reproductible open source : Fournir des poids de modèles et des descriptions de dépendances de soutien pour permettre aux chercheurs de reproduire des expériences ou de réaliser un développement secondaire (la licence du modèle est Apache-2.0, le dépôt ou la carte modèle spécifique prévaut).
3. Installation
1. Créer un environnement (exemple) : conda create -n qwenlongl1_5 python==3.10 && conda activate qwenlongl1_5
2. Installer les dépendances : exécuter pip3 install -r requirements.txt dans le répertoire correspondant (sous réserve du fichier réel).
3. Installer la bibliothèque de formation RL : Installer le verl selon la recommandation du projet (par exemple cloner volcengine/verl et couper à la pip3 install -e . après v0.4).
- Dépendances côté inférence : Utilisez des Transformers pour charger des modèles et des tokenizateurs (vous pouvez aussi ajuster device_map, dtype, etc. selon votre cadre d’inférence).
4. Cas d’usage typiques
- Questions & Réponses sur un long document (DocQA) : Raisonnement en plusieurs sauts et attribution de réponses en croisière sur des documents techniques, des documents de conformité et des documents/rapports.
- Matériaux ultra-longs « lire et répondre » : Lorsque l’échelle d’entrée dépasse un seul contexte, le processus de l’agent mémoire est utilisé pour la lecture segmentée, la mise à jour de la mémoire et la réponse finale complète.
- Analyse des connaissances d’entreprise : extraction structurelle de points clés, détection de conflits et vérification de la cohérence des rapports annuels, documents d’appel d’offres et documents de demande.
- Recherche sur la reproduction et la pratique d’entraînement : utilisée pour explorer la stratégie d’échantillonnage, la conception de la récompense, la stabilité de l’entraînement et le système d’évaluation du RL à long contexte.
5. Écologie et produits concurrents
- Même écosystème de dépôt : Qwen-Doc inclut également QwenLong-L1 (exploration RL à long contexte antérieure) et SPELL (framework RL auto-jeu), adapté aux expériences comparatives sur le lien complet « data-training-agent ».
- Relation avec le schéma RAG/compression : RAG est davantage un « taux de réussite de récupération et staling de contexte », tandis que QwenLong-L1.5 met l’accent sur « la capacité de raisonnement et le processus de mémoire après avoir lu un long texte » ; Les deux peuvent être combinés en ingénierie (d’abord la récupération, puis le raisonnement long / résumé de la mémoire).
- Référence de produit concurrentielle : les modèles à long contexte fermés et diverses méthodes open source de fine-tunning/attention parcimonie/compression ont leurs propres compromis ; La différence de QwenLong-L1.5 est que « synthèse de données à longue inférence + entraînement stable RL en longue séquence + agent mémoire » est donné comme un ensemble de formules post-entraînement.
6. Limitations et précautions
- Puissance de calcul et latence : L’inférence en longues séquences et l’entraînement RL nécessitent plus de mémoire/débit, surtout dans les fenêtres de niveau 256K ou les boucles proxy mémoire, le coût augmentera considérablement.
- La mémoire n’est pas « absolument correcte » : la mise à jour de la mémoire peut introduire des omissions et des écarts, et il est recommandé de conserver la traçabilité des preuves et les mécanismes de revue manuelle dans les scénarios clés.
- Seuil de reproduction d’entraînement : Les récompenses, l’échantillonnage et les superparamètres du RL sont sensibles aux résultats. Différents clusters/backends d’inférence peuvent aussi affecter la stabilité.
- Évaluer les risques d’extrapolation : L’amélioration des benchmarks ne signifie pas que toutes les tâches réelles des documents sont améliorées, et que la régression des données de domaine et l’évaluation de la sécurité doivent être effectuées avant la mise en œuvre.
7. Adresse du projet
https://github.com/Tongyi-Zhiwen/Qwen-Doc/tree/main/QwenLong-L1.5
8. Questions fréquemment posées
Q : Quel problème résout QwenLong-L1.5 ?
R : Principalement pour les tâches de long document de « raisonnement inter-chapitres, multi-preuves, multi-sauts », l’objectif est de permettre au modèle non seulement de récupérer des fragments, mais aussi de compléter le raisonnement en chaîne et le jugement de cohérence sur une longue période.
Q : Qu’est-ce que l’AEPO de QwenLong-L1.5 et quel est son rapport avec les PPO courants ?
R : L’AEPO est l’une des méthodes d’optimisation stratégique conçues pour la stabilité de l’entraînement à long contexte, qui régule l’exploration et l’intensité de mise à jour via des mécanismes liés à l’entropie. Il appartient au même paradigme d’optimisation stratégique que PPO, mais les détails d’implémentation et les méthodes de stabilisation sont différents (sous réserve de l’implémentation du papier et du code).
Q : Combien de temps le QwenLong-L1.5-30B-A3B a-t-il besoin pour utiliser la fenêtre de contexte ?
R : Le modèle fonctionne selon une combinaison de « fenêtre physique + mécanisme mémoire » ; Le matériel d’exemple mentionne la réalisation d’une seule inférence dans une fenêtre de 256K et peut être étendu à des entrées plus longues avec un proxy mémoire. La longueur réelle disponible dépend du cadre d’inférence, de la mémoire et de la configuration.
Q : Je veux juste faire du raisonnement, pas de l’entraînement, comment puis-je commencer le QwenLong-L1.5 le plus rapidement possible ?
R : Utilisez directement Transformers pour charger les poids et les tokenizateurs depuis l’entrepôt de modèles, et préparez de longs textes et des questions de questions. Pour reproduire le processus de proxy mémoire, référez-vous à la description du script et de l’article de support du projet.
Q : Dois-je choisir entre QwenLong-L1.5 et RAG ?
R : Pas forcément. RAG résout le problème de la « recherche », et QwenLong-L1.5 met l’accent sur « la lecture et la compréhension, l’exploration et la mémoire » ; Une combinaison courante en pratique technique est « rétrécissement par récupération + long raisonnement/résumé mémoire pour résoudre des questions et réponses complexes ».