1. 초록
QwenLong-L1.5는 Tongyi Zhiwen 팀이 Qwen-Doc 저장소에 공개한 "긴 컨텍스트 추론 + 메모리 관리" 훈련 후 레시피 세트입니다. 이 프로젝트는 세 가지를 중심으로 합니다: 긴 문서에 대한 복잡한 추론 데이터 합성, 긴 시퀀스에 대한 강화 학습 안정 학습 방법(AEPO 등), 그리고 물리적 맥락 창 밖에서도 작동하는 메모리 관리 프레임워크, 그리고 Qwen3-30B-A3B-Thinking 기반의 QwenLong-L1.5-30B-A3B 모델이 공개되었습니다.
2. 핵심 특징
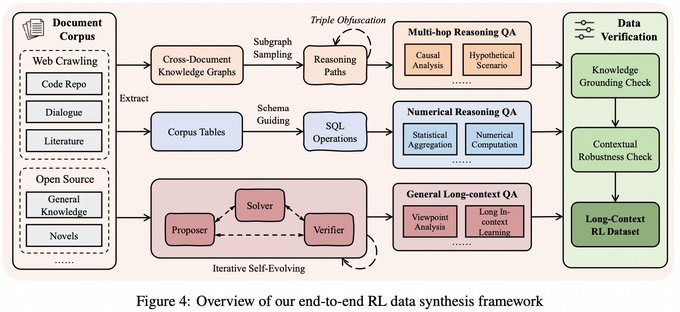
- 장기 문맥 추론 데이터 합성: "원자 사실 분해 + 검증 가능한 조합" 방법을 통해 단순한 검색 작업이 아닌 다중 홉 증거 연계가 필요한 긴 문서 추론 샘플을 생성합니다.
- 장기열 RL 안정 훈련: 작업 균형 샘플링과 같은 전략이 도입되며, AEPO(적응형 엔트로피 제어 정책 최적화)를 제안하여 엔트로피 관련 메커니즘으로 훈련 과정을 조절하여 장기 맥락 강화학습의 흔한 불안정성 문제를 완화합니다.
- 메모리 관리 및 초장기 입력: 모델의 물리적 창(예시에서 언급된 256K 창)에서 단일 추론을 수행하고, 이를 반복 메모리 업데이트와 결합하여 처리 범위를 수백만 개 또는 더 긴 입력 스트림으로 확장합니다(논문 설명은 1M-4M 토큰 수준 작업을 포함합니다).
- 오픈 소스 재현 가능: 연구자들이 실험을 재현하거나 2차 개발을 할 수 있도록 모델 가중치와 의존성 설명을 제공하세요(모델 라이선스는 Apache-2.0이며, 특정 저장소/모델 카드가 우선).
3. 설치
1. 환경 만들기(예시): conda create -n qwenlongl1_5 python==3.10 && conda activate qwenlongl1_5
2. 의존성 설치: 해당 디렉터리에서 pip3 install -r requirements.txt을 실행하세요(실제 파일에 따라 다름).
3. RL 교육 라이브러리 설치: 프로젝트 권고에 따라 verl을 설치하세요(예: v0.4 volcengine/verl 클론 후 pip3 install -e .으로 전환).
- 추론 측 의존성: Transformer를 사용해 모델과 토큰라이저를 불러오세요(추론 프레임워크에 따라 device_map, dtype 등도 조정할 수 있습니다).
4. 일반적인 사용 사례
- 긴 문서 Q&A(DocQA): 기술 문서, 준수 자료, 논문/보고서에 대한 다중 단락 간 다중 논거 및 답변 출처 표시.
- "읽고 답변" 초장기 자료: 입력 스케일이 단일 맥락을 초과할 때, 메모리 에이전트 프로세스가 분할 읽기, 메모리 업데이트 및 최종 종합 답변에 사용됩니다.
- 기업 지식 분석: 구조적 핵심 지점 추출, 갈등 감지, 연례 보고서, 입찰 문서, 수요 문서의 일관성 점검.
- 재생 및 훈련 실천 연구: 장기 맥락 강화학습의 표본 추출 전략, 보상 설계, 훈련 안정성 및 평가 시스템을 탐구하는 데 사용됨.
5. 생태와 경쟁 제품
- 동일한 저장소 생태계: Qwen-Doc에는 QwenLong-L1(이전의 장기 맥락 강화 탐색)과 SPELL(셀프 게임 RL 프레임워크)도 포함되어 있으며, 이는 "data-training-agent" 전체 링크에 대한 비교 실험에 적합합니다.
- RAG/압축 방식과의 관계: RAG는 "검색 성공률과 문맥 스플라이싱"에 더 중점을 두는 반면, QwenLong-L1.5는 "긴 텍스트 읽기 후 추론 능력과 기억 과정"을 강조합니다; 이 두 가지를 공학에서는 결합할 수 있습니다(먼저 검색, 그 다음에 긴 추론/기억 요약).
- 경쟁 제품 참조: 폐쇄 소스 장기 문맥 모델과 다양한 오픈소스 장문 문맥 미세 조정/희소 주의/압축 방법은 각각 단점이 있습니다; QwenLong-L1.5의 차이점은 "긴 추론 데이터 합성 + 긴 시퀀스 RL 안정 훈련 + 메모리 에이전트"가 훈련 후 공식의 집합으로 제시된다는 점입니다.
6. 제한 및 주의사항
- 연산 능력과 지연 시간: 긴 시퀀스 추론과 강화학습 훈련은 특히 256K 레벨 윈도우나 메모리 프록시 루프에서 메모리/처리량이 더 많아 비용이 크게 증가합니다.
- 기억은 '절대적으로 정확하다'고 할 수 없습니다: 기억 업데이트는 누락과 편차를 초래할 수 있으므로, 주요 상황에서는 증거 추적성과 수동 검토 메커니즘을 유지하는 것이 권장됩니다.
- 훈련 재현 임계값: 강화학습의 보상, 표본추출, 슈퍼파라미터는 결과에 민감합니다. 클러스터나 추론 백엔드에 따라 안정성도 영향을 줄 수 있습니다.
- 외삽 위험 평가: 벤치마크 개선이 모든 실제 문서 작업이 개선된다는 의미는 아니며, 도메인 데이터 회귀 및 보안 평가는 구현 전에 이루어져야 합니다.
7. 프로젝트 주소
https://github.com/Tongyi-Zhiwen/Qwen-Doc/tree/main/QwenLong-L1.5
8. 자주 묻는 질문
Q: QwenLong-L1.5가 해결하는 문제는 무엇인가요?
답변: 주로 "장을 넘나들고, 증거 다수, 여러 홉 추론"과 같은 장기 문서 작업을 위해, 모델이 단편을 검색하는 것뿐만 아니라 장거리에서 완전한 연쇄 추론과 일관성 판단을 가능하게 하는 것이 목표입니다.
Q: QwenLong-L1.5의 AEPO는 무엇이며, 일반적인 PPO와 어떻게 연관되나요?
A: AEPO는 장기 맥락 훈련 안정성을 위해 설계된 전략 최적화 방법 중 하나로, 엔트로피 관련 메커니즘을 통해 탐색 및 갱신 강도를 조절합니다. 이 프로토콜은 PPO와 동일한 전략 최적화 패러다임에 속하지만, 구현 세부사항과 안정화 방법은 다르며(논문과 코드 구현에 따라 다름).
Q: QwenLong-L1.5-30B-A3B가 컨텍스트 윈도우를 얼마나 오래 사용해야 하나요?
A: 이 모델은 "물리적 창 + 메모리 메커니즘"의 조합으로 작동합니다; 예시 자료에서는 256K 윈도우에서 단일 추론을 수행하며, 메모리 프록시를 통해 더 긴 입력으로 확장할 수 있다고 언급합니다. 실제 사용 가능한 길이는 추론 프레임워크, 메모리, 구성에 따라 달라집니다.
Q: 저는 훈련이 아니라 추론을 하고 싶은데, QwenLong-L1.5를 가장 빨리 시작할 수 있는 방법은 무엇인가요?
A: Transformers를 직접 사용해 모델 웨어하우스에서 가중치와 토큰라이저를 불러오고, 긴 텍스트와 질문 프롬프트를 준비하세요. 메모리 프록시 프로세스를 재현하려면 프로젝트 지원 스크립트와 종이 설명을 참조하세요.
Q: QwenLong-L1.5와 RAG 중 하나를 선택해야 할까요?
A: 꼭 그렇지는 않습니다. RAG는 '찾기' 문제를 해결하며, QwenLong-L1.5는 '읽고 이해하며, 멀리 밀고, 기억하기'를 강조합니다; 공학 실무에서 흔히 조합하는 것은 "복잡한 질문과 답변을 완성하기 위한 긴 추론/기억 요약" 같은 것입니다.