
Qwen画像層式オープンソース解釈:「ネイティブレイヤー」モデルで、グラフを編集可能なRGBAレイヤーに分解します
1. 要旨 Qwen-Image-Layeredは、Qwenチームによるオープンソースの画像「レイヤリング」モデルで、通常のRGB画像を物理的に分離した複数のRGBAレイヤーを出力します。 一般的な「同じ平面マップ上での編集」とは異なり、メインボディと構造を独立したレイヤーに分解し、ヘビーシェーディ...
Admin •
301
1. 要旨 Qwen-Image-Layeredは、Qwenチームによるオープンソースの画像「レイヤリング」モデルで、通常のRGB画像を物理的に分離した複数のRGBAレイヤーを出力します。 一般的な「同じ平面マップ上での編集」とは異なり、メインボディと構造を独立したレイヤーに分解し、ヘビーシェーディ...
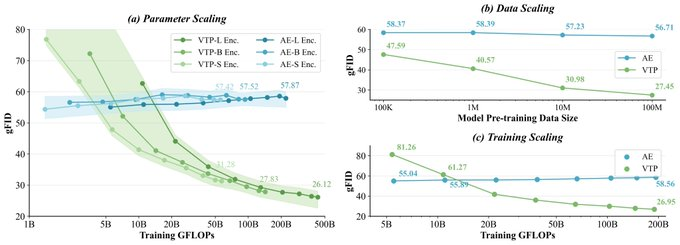
1. Abstract VTP(Visual Tokenizer Pre-training)は、MiniMax(Hailuo)チームによって開発されたオープンソースのビジュアルトークナイザー事前学習フレームワークで、拡散モデルや拡散トランスフォーマー(DiT)などの次世代生成モデルを対象としています...
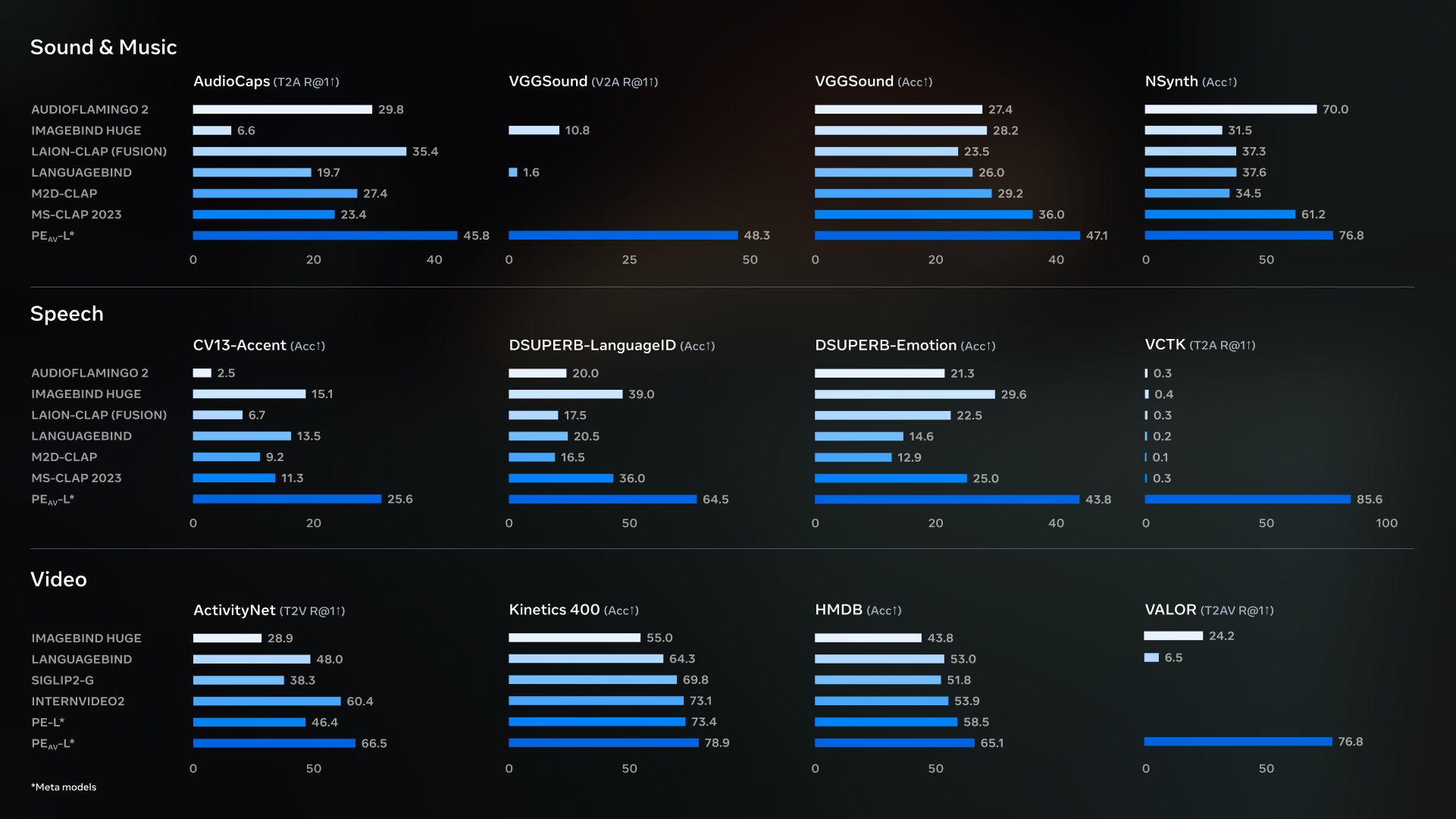
- Abstract PE-AV(Perception Encoder Audiovisual)は、Metaのオープンソースのオーディオビジュアル共同エンコーダファミリーであり、Perception Encoderをベースにネイティブオーディオ機能を追加し、映像、音声、音声およびテキスト表現を統一さ...

1. 抽象 HY World 1.5(WorldPlay)は、騰訊のHunyuanチームによって開発されたオープンソースのリアルタイム世界モデルフレームワークで、ストリーミング生成をサポートする動画拡散モデルを核としています。 このシステムはテキストや画像入力に基づいてリアルタイムでインタラクティブ...
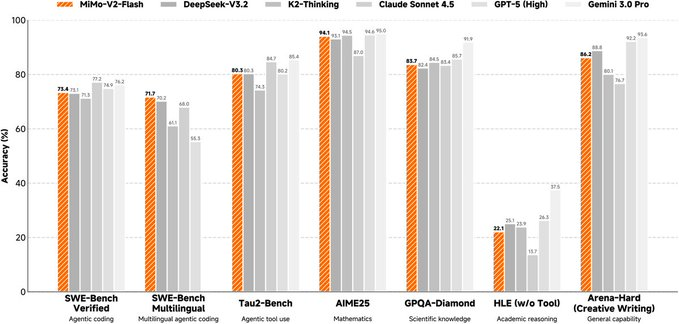
1. Abstract MiMo-V2-Flashは、Xiaomi MiMoチームによるオープンソースのハイブリッドエキスパート(MoE)大規模言語モデルで、推論中の総パラメータは約309B、活性化パラメータは約15Bで、推論、プログラミング、エージェントワークフローのバランスを低コストで行うことに...
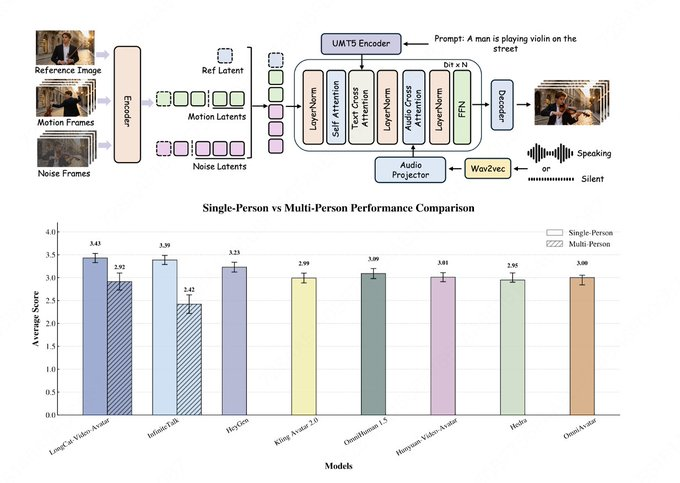
1. Abstract LongCat-Video-Avatarは、LongCat-Videoアーキテクチャに基づく音声駆動型アバター(仮想人間)ビデオ生成モデルで、「長時間のシーケンス、強い一貫性、リアルかつ動的な」シナリオに適しています。 ネイティブに音声テキストからビデオ(AT2V)、音声テキ...