- Abstract
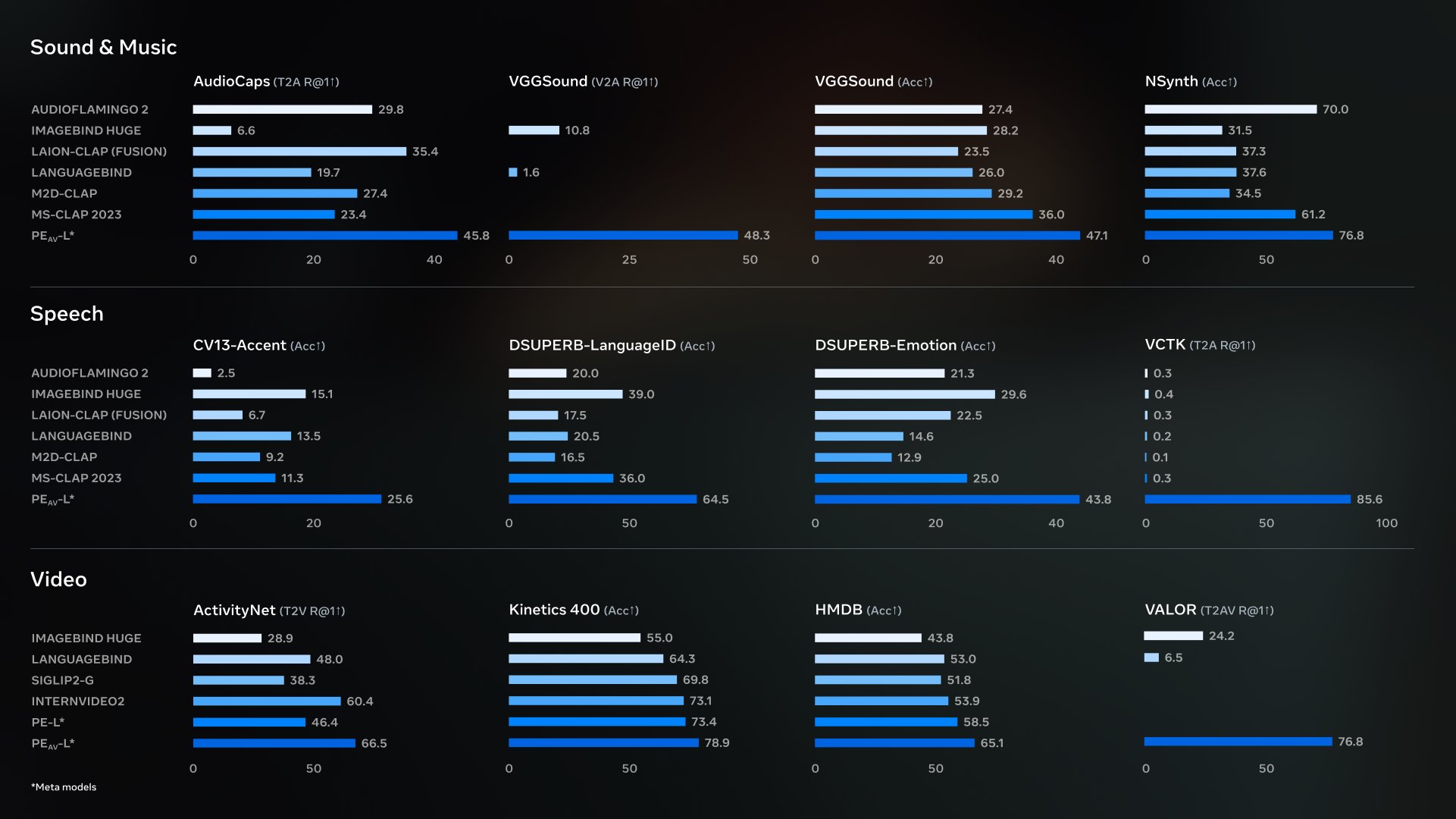
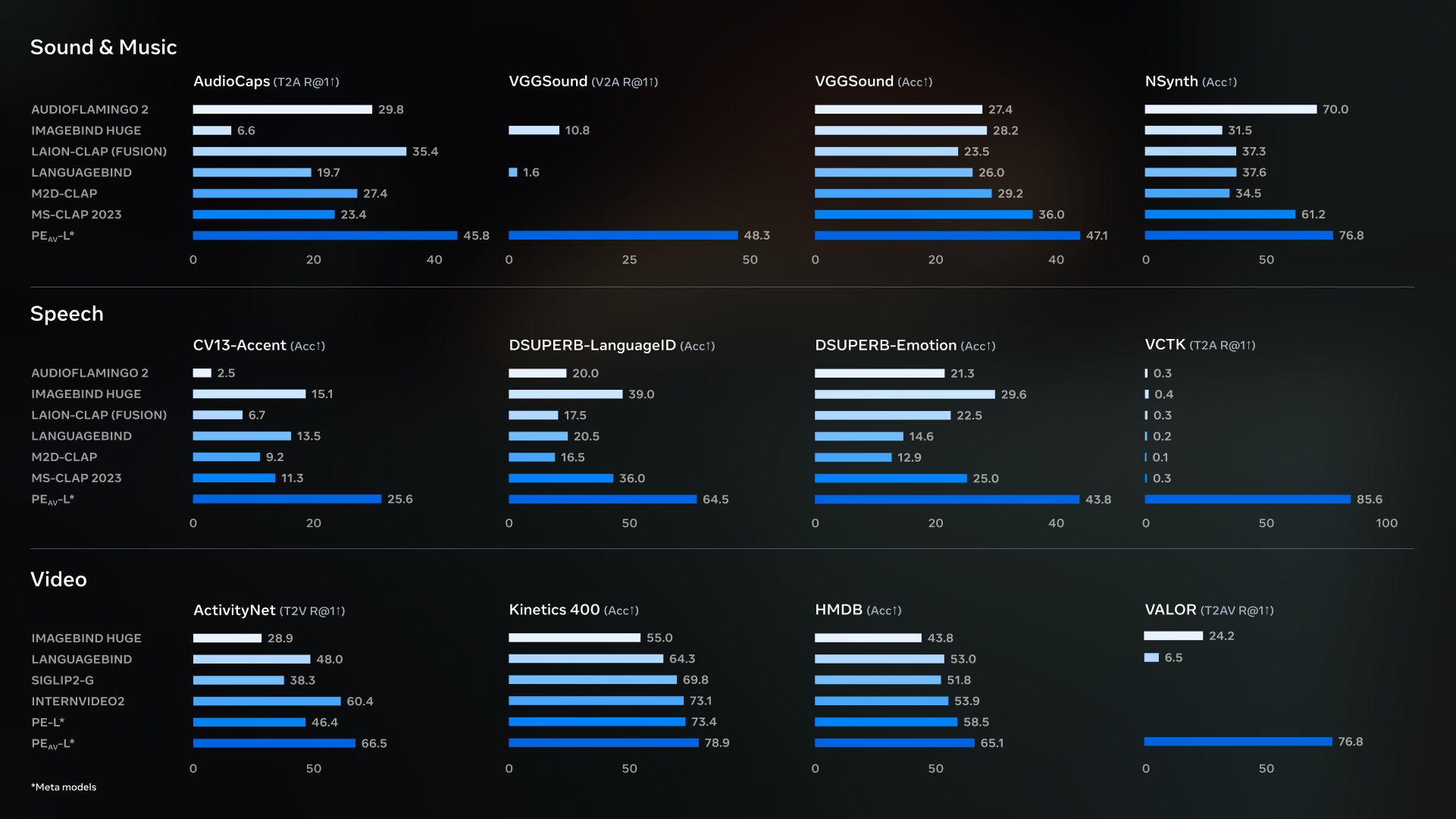
PE-AV(Perception Encoder Audiovisual)は、Metaのオープンソースのオーディオビジュアル共同エンコーダファミリーであり、Perception Encoderをベースにネイティブオーディオ機能を追加し、映像、音声、音声およびテキスト表現を統一された埋め込み空間に整合させます。 これはSAM Audioの主要コンポーネントを支えるために用いられ、複数のオーディオ/ビデオ検索および理解ベンチマークをリードしています。
- コア機能
- マルチモーダル統一埋め込み:音声、ビデオ、音声-ビデオ、テキストの特徴符号化と類似度計算を同時に行います。
- 音声および映像の検索とアライメント:「音声や画像をテキストで検索する」「画面で音を探す」などのクロスモーダル検索が可能です。
- マルチサイズ/マルチバージョンのウェイト:スモール/ベース/ラージのほか、「16フレーム」や「オールフレーム」などの構成があり、エフェクトと計算能力のトレードオフを容易にします。
- エンジニアリングの再利用性:perception_modelsエコシステムと同じ倉庫でリリースされ、PEシリーズや下流のマルチモーダルアプリケーションとの連携に便利です。
- インストール
- クローンコード:git https://github.com/facebookresearch/perception_models クローン
- 環境を作成し依存関係をインストール:リポジトリのrequirements.txt/setup.py 指示に従ってインストールします(依存関係はプラットフォームによって異なります)。
- 重みを取得する:例を実行すると、Hugging Faceから対応するチェックポイント(例えばpe-av-largeなど)を引き出します。
- 典型的なユースケース
- 音声・映像検索:ビデオライブラリから「サイレン付きのダイアログクリップ」を一文で見つける。
- 音の合図支援による理解:騒がしいシーンでの音源認識とシーン描写を向上させるために、画像を組み合わせること。
- 音声分離/編集の上流認識:SAM Audioのようなインタラクティブ分離のためのより強力な音声・映像アライメント表現を提供します。
- データ注釈と品質検査:「画像と音声の一貫性がない」サンプルをスクリーニングするために、クロスモーダルの類似性を用いましょう。
- 生態学と競合製品
- 生態学:PE-AVはMetaのperception_modelsである; モデルの重みは、再現性と統合を容易にするためにHugging Faceにコレクションとして公開されています。
- 競合する製品アイデア:オーディオエンコーダーやビデオエンコーダーのみと比べて、PE-AVは「音声・映像対応学習」の統一空間に焦点を当てています。 CLIP法と比べて、音声と音声・映像の共同特性評価に拡張されており、これは実際の映像作業により近いものです。
- 制限と注意点
- 計算能力とスループット:ビデオフレームレートの設定はビデオメモリと速度に大きな影響を与え、サービスに応じて小規模/ベース/大きいおよびフレーム戦略を選択する必要があります。
- データドメインシフト:特定の言語、特定の音声タイプ、または強いノイズ条件下では、クロスモーダルアラインメントが低下する可能性があるため、小規模な検証が推奨されます。
- 著作権とプライバシー:人との公開ビデオ/音声会話を処理する際は、データコンプライアンスおよび承認要件を遵守しなければなりません。
- プロジェクトアドレス
https://github.com/facebookresearch/perception_models
- FAQ
(PE-AVオープンソースモデル) どのような入力モダリティがサポートされていますか?
回答は
音声、ビデオ、音声、ビデオ、テキストをサポートし、類似度計算に使用できる埋め込み表現を出力します。
質問(PE-AVのインストール)重りはどこからダウンロードされ、手動で設置する必要がありますか?
答えは通常
、Hugging Faceによって自動的に引き出され、対応するチェックポイントを引きます。 オフライン環境では、リポジトリの指示に従って手動でパスをダウンロードし設定する必要があります。
質問(PE-AVとSAMオーディオ)この二つの関係は何ですか?
回答
:PE-AVはSAM Audioの複数のコアコンポーネントを駆動する知覚/エンコーディングエンジンであり、強化された視聴覚・映像の整合性を提供します。
質問(PE-AVチェックポイント)PE-AV-小/ベース/大か、それとも16フレームを選ぶべきか?
答えが大きい
ほど効果は強くなりますが、計算能力も高くなります。 16フレームはよりリソースを節約し、すべてのフレームが映像情報をより良く利用するため、サービス速度やコスト制約に基づく比較実験を行うことが推奨されます。