オープンソース音声ソリューションの比較:Fun-CosyVoice3と一般的なTTS、Fun-ASR-nanoと主流のASRの比較
1. 要約 アリババ通義ボイスチーム(FunAudioLLM)は、音声合成用のFun-CosyVoice3-0.5B-2512(TTS)と音声認識用のFun-ASR-Nano-2512(ASR)という2種類のオーディオモデルをオープンソース化しています。 前者は多言語のゼロショット音声クローンと低遅...
Admin •
619
1. 要約 アリババ通義ボイスチーム(FunAudioLLM)は、音声合成用のFun-CosyVoice3-0.5B-2512(TTS)と音声認識用のFun-ASR-Nano-2512(ASR)という2種類のオーディオモデルをオープンソース化しています。 前者は多言語のゼロショット音声クローンと低遅...

1. 抽象 GLM-TTSは、産業用音声生成のためのオープンソースTTSシステムであり、音声サンプルの音色クローン作成をわずか3秒で行い、感情表現を制御可能です。 そのアーキテクチャは2段階の生成プロセスを採用し、文字誤り率(CER)とセンチメントの面でオープンソースとしてトップレベルのレベルを実現...

1. 抽象 的 Open-AutoGLMはZhipu AI向けのオープンソースの携帯電話エージェントフレームワークであり、コアモデルはAutoGLM-Phone-9Bです。 携帯電話の画面内容を理解し、実際のユーザーの操作をシミュレートして「インターフェースの理解、指示の理解、携帯電話のクリック」を...
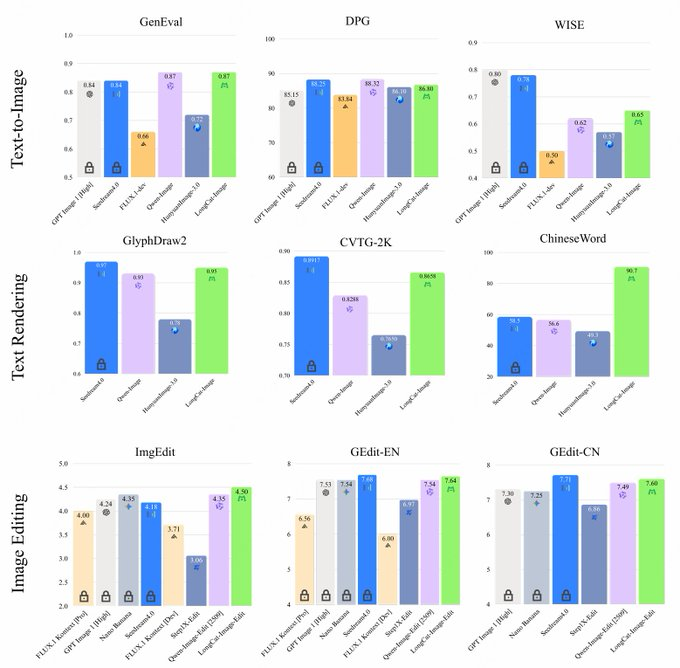
1. Abstract LongCat-Imageは、MeituanのLongCatチームによる中国語と英語のオープンソースのバイリンガル画像生成・編集モデルで、パラメータは約6B、ハイブリッドDiTアーキテクチャを採用しています。これは多くの公開ベンチマークで20Bレベルのオープンソースモデルと同...
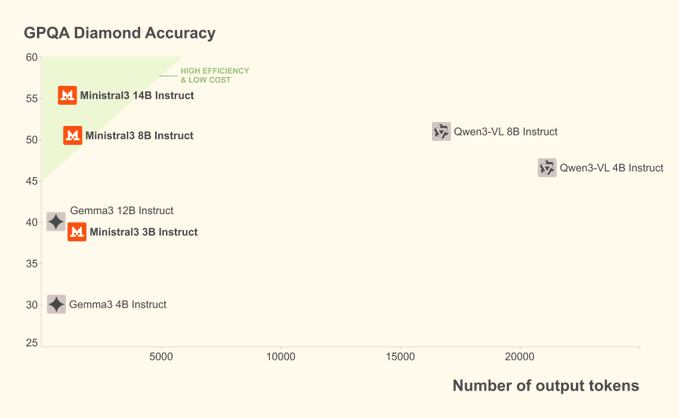
1. Abstract Mistral 3は、Mistral AIが導入した新世代のオープンソースモデルファミリーで、スパースエキスパートアーキテクチャのMistral Large 3や、ローカルおよびエッジシナリオ向けのMinistral 3シリーズ(3B/8B/14B)を含みます。 すべてのウェ...
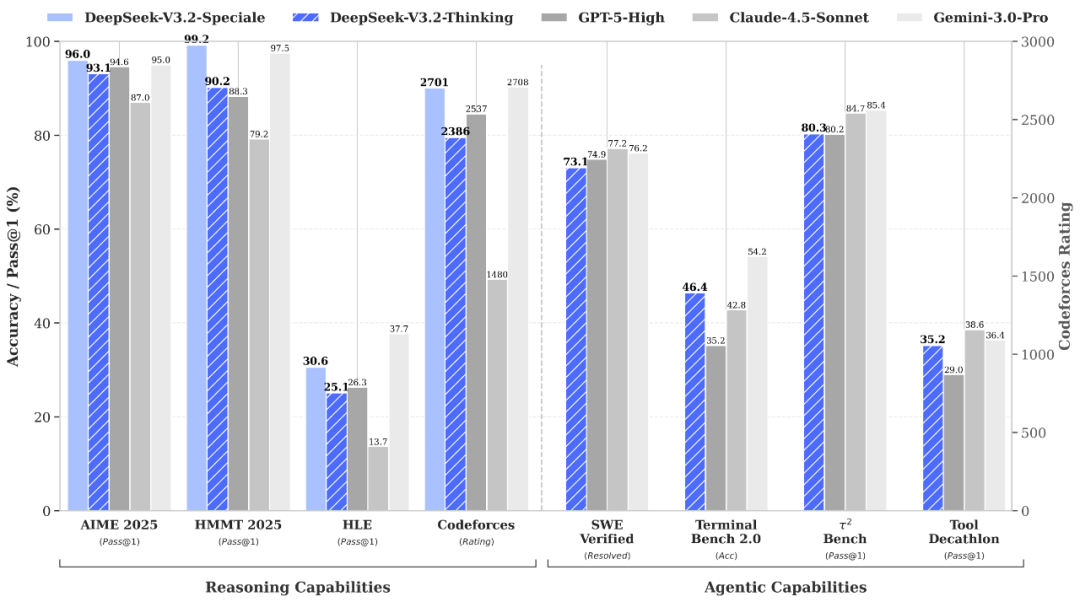
1. Abstract DeepSeek-V3.2は、V3.2-Expを基にした公式リリース版で、推論効率と出力長の最適化、DSAのスパースアテンションメカニズムを用いて長期コンテキスト性能の向上に重点を置いています。 DeepSeek-V3.2-Specialeは、極限の数学的推論、プログラミング...