1. Abstract
VTP (Visual Tokenizer Pre-training) is an open-source visual tokenizer pre-training framework developed by the MiniMax (Hailuo) team, which is aimed at next-generation generative models such as diffusion models and Diffusion Transformer (DiT). The project pointed out that the traditional "rebuild-only" tokenizer training will bias the latent space towards low-level pixel information, resulting in the problem of pre-training scaling that "reconstruction is more accurate but not necessarily better generation". VTP will jointly optimize representation learning and compression-reconstruction, so that the tokenizer can more stably translate into downstream generation quality improvement when the model scale, data, and computing power expand, and try not to change the standard DiT training specifications.
2. Core features
- Joint optimization of three types of objectives: graphic and text comparison learning, self-supervised learning and reconstruction goal joint training, taking into account semantic representation and decoding.
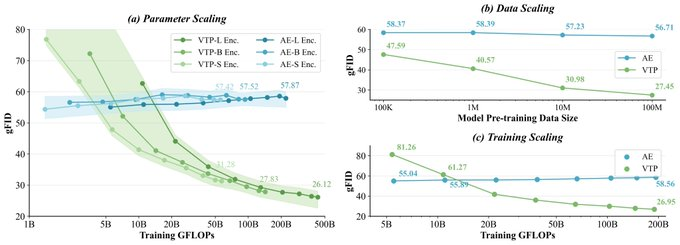
- Scalable tokenizer scaling: Emphasizing that investing computing power in tokenizer pre-training can bring downstream generation benefits, rather than just pursuing lower reconstruction errors.
- Generation-oriented evaluation link: Provide an integrated control of understanding (zero-shot/linear probing), reconstruction (rFID) and generation (FID based on LightningDiT).
- Open source weights and multi-size models: Hugging Face provides model specifications such as Small/Base/Large to facilitate trade-offs based on resources and effects.
3. Installation
- Create an environment: conda creates a Python 3.10 environment and activates it.
- Initialize submodules: The warehouse uses submodules to manage some dependent code, which needs to be pulled recursively.
- Install dependencies: Install Python dependencies according to requirements.
- Run the evaluation script: modify the path according to the script description and execute the zero-sample, linear detection, reconstruction and generation evaluation script; Generate an evaluation link and use LightningDiT-related scripts to complete feature extraction, training, and sampling.
4. Typical use cases
- Stage-1 tokenizer of DiT/diffusion model: Verify the influence of "stronger latent" on generation quality and convergence speed without changing the generator structure.
- Visual representation extraction: used for retrieval, classification, clustering or downstream light tasks (zero-shot and linear probing).
- Research reconstruction-semantic trade-off: Compared with the traditional VAE/VQ tokenizer, the semantics and generative learnability changes of the latent space after adding representation learning are analyzed.
- Reproduce the experimental curve: Based on the open source script, the scaling comparison of parameters/data/computing power dimensions is used to construct the correlation curve between tokenizer and generation performance.
5. Ecology and competing products
- Related ecology: The training and evaluation link involves comparative learning, self-supervised representation learning, and DiT generation evaluation processes, which is convenient for aligning with mainstream visual representation and diffusion generation systems.
- Direction of competing products: traditional LDM commonly used reconstructed VAE, VQ-VAE/VQGAN, etc. as tokenizers; There are also improved routes to enhance latent space through distillation or regularity. The difference of VTP is that it takes "understanding/characterization" as the key driver of generative scalability and verifies its gain to downstream generation with systematic evaluation.
6. Limitations and Precautions
- Resource threshold: Complete reproduction of large-scale tokenizer pre-training and generation evaluation requires strong computing power, data, and engineering pipelines.
- Engineering integration cost: Before replacing the existing tokenizer, it is necessary to evaluate the latent variable interface, compression ratio, decoding speed, and end-to-end stability.
- Results depend on training formula: different data distributions, sampling strategies and generator settings will affect the final indicators, and it is recommended to do strict budget comparison and visual inspection.
- The project is still evolving: Some models/scripts and instructions may be adjusted with version updates, and it is recommended to refer to the latest content of the repository and model pages.
7. Project address
https://github.com/MiniMax-AI/VTP
8. FAQs
Q: What is the core problem solved by VTP (Visual Tokenizer Pre-training)?
A: Solve the "visual tokenizer pre-training scale problem", that is, it is difficult for traditional tokenizers that only rebuild training to stably convert more computing power into downstream DiT/diffusion generation quality improvement.
Q: Why is VTP emphasizing representational learning more important for generation (Diffusion Transformer/DiT)?
A: The idea is to generate a learnable latent space that relies more on high-level semantics and structure; Only pursuing pixel-level reconstruction accuracy can easily make the latent space low-level information, resulting in stagnation of generation revenue.
Q: Can VTP improve the generation quality without increasing the generator's training power?
A: The goal is to put the main increment on the tokenizer pre-training side and try to keep the standard DiT training specifications comparable, so as to lead to better generation with better latency.
Q: How should I choose VTP-Small/Base/Large on Hugging Face?
A: Generally, larger tokenizers have stronger representation capabilities but higher resource requirements; You can use Small/Base to go through the evaluation link first, and then evaluate the benefits of Large under the same budget.
Q: What should I focus on when replacing the VAE/VQ tokenizer of an existing LDM?
A: Focus on latent variable shape and interface compatibility, compression rate and decoding speed, generation training stability, and FID/convergence speed and subjective quality comparison under the same training budget.