一、摘要
VTP(Visual Tokenizer Pre-training)是 MiniMax(Hailuo)团队开源的视觉 tokenizer 预训练框架,面向扩散模型与 Diffusion Transformer(DiT)等下一代生成模型。项目指出传统“仅重建”的 tokenizer 训练会让潜空间偏向低层像素信息,出现“重建更准但生成不一定更好”的预训练规模化问题。VTP 将表征学习与压缩-重建联合优化,使 tokenizer 在模型规模、数据与算力扩大时,更稳定地转化为下游生成质量提升,并尽量不改动标准 DiT 训练规格。
二、核心特性
1、联合优化三类目标:图文对比学习、自监督学习与重建目标共同训练,兼顾语义表征与可解码性。
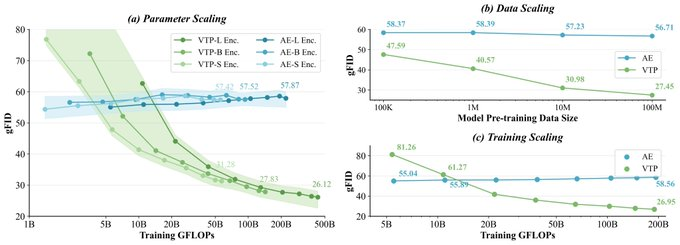
2、可扩展的 tokenizer scaling:强调把算力投入到 tokenizer 预训练即可带来下游生成收益,而非仅追求更低重建误差。
3、面向生成的评测链路:提供理解(零样本/线性探测)、重建(rFID)与生成(基于 LightningDiT 的 FID)一体化对照。
4、开源权重与多尺寸模型:在 Hugging Face 提供 Small/Base/Large 等模型规格,便于按资源与效果取舍。
三、安装
1、创建环境:conda 创建 Python 3.10 环境并激活。
2、初始化子模块:仓库使用子模块管理部分依赖代码,需递归拉取。
3、安装依赖:按 requirements 安装 Python 依赖。
4、运行评测脚本:按脚本说明修改路径后执行零样本、线性探测、重建与生成评测脚本;生成评测链路使用 LightningDiT 相关脚本完成特征抽取、训练与采样。
四、典型用例
1、DiT/扩散模型的 stage-1 tokenizer:在不改变生成器结构的前提下,验证“更强潜空间”对生成质量与收敛速度的影响。
2、视觉表征抽取:用于检索、分类、聚类或下游轻量任务(零样本与线性探测)。
3、研究重建-语义权衡:对比传统 VAE/VQ tokenizer,分析加入表征学习后潜空间的语义性与生成可学习性变化。
4、复现实验曲线:基于开源脚本做参数/数据/算力维度的 scaling 对照,构建 tokenizer 与生成性能的关联曲线。
五、生态与竞品
1、相关生态:训练与评测链路涉及对比学习、自监督表征学习与 DiT 生成评测流程,便于与主流视觉表征与扩散生成体系对齐。
2、竞品方向:传统 LDM 常用重建式 VAE、VQ-VAE/VQGAN 等作为 tokenizer;也存在通过蒸馏或正则增强潜空间的改进路线。VTP 的差异点在于把“理解/表征能力”作为生成可扩展性的关键驱动,并用系统性评测验证其对下游生成的增益。
六、局限与注意事项
1、资源门槛:完整复现大规模 tokenizer 预训练与生成评测需要较强算力、数据与工程管线。
2、工程集成成本:替换现有 tokenizer 前需评估潜变量接口、压缩率、解码速度与端到端稳定性。
3、结果依赖训练配方:不同数据分布、采样策略与生成器设置会影响最终指标,建议做严格同预算对照与可视化检查。
4、项目仍在演进:部分模型/脚本与说明可能随版本更新而调整,建议以仓库与模型页最新内容为准。
七、项目地址
https://github.com/MiniMax-AI/VTP
八、常见问题
Q: VTP(Visual Tokenizer Pre-training)解决的核心问题是什么?
A: 解决“visual tokenizer 预训练规模化问题”,即传统仅重建训练的 tokenizer 难把更多算力稳定转化为下游 DiT/扩散生成质量提升。
Q: VTP 为什么强调表征学习对生成(Diffusion Transformer/DiT)更重要?
A: 其观点是生成更依赖高层语义与结构的可学习潜空间;仅追求像素级重建精度容易让潜空间偏低层信息,导致生成收益停滞。
Q: VTP 是否能在不增加生成器训练算力的情况下提升生成质量?
A: 目标是将主要增量放在 tokenizer 预训练侧,并尽量保持标准 DiT 训练规格可比,从而用更好的潜空间带来更好的生成。
Q: Hugging Face 上的 VTP-Small/Base/Large 应该怎么选?
A: 一般越大的 tokenizer 表征能力更强但资源需求更高;可先用 Small/Base 走通评测链路,再在同预算对照下评估 Large 的收益。
Q: 替换现有 LDM 的 VAE/VQ tokenizer 时最该关注什么?
A: 关注潜变量形状与接口兼容、压缩率与解码速度、生成训练稳定性,以及在同训练预算下的 FID/收敛速度与主观质量对比。