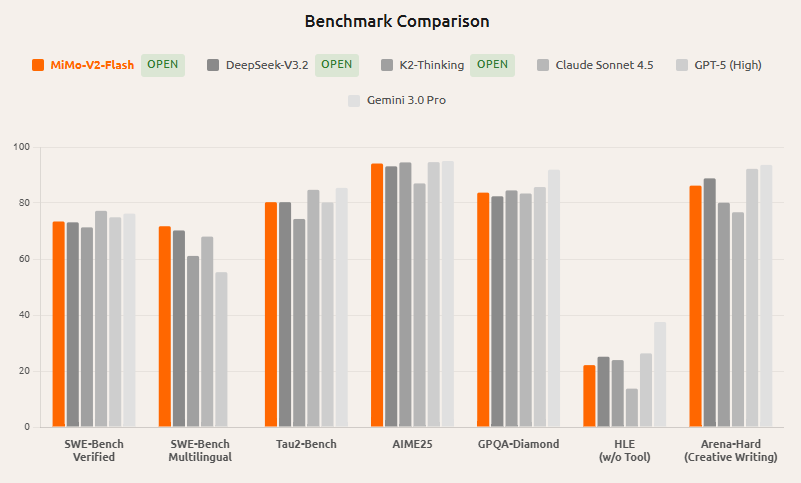
1. Abstract
VTP(Visual Tokenizer Pre-training)は、MiniMax(Hailuo)チームによって開発されたオープンソースのビジュアルトークナイザー事前学習フレームワークで、拡散モデルや拡散トランスフォーマー(DiT)などの次世代生成モデルを対象としています。 プロジェクトは、従来の「再構築のみ」トークナイザー訓練が潜在空間を低レベルのピクセル情報に偏らせ、その結果、事前学習のスケーリングに「再構築の方が正確だが必ずしもより良い生成とは限らない」という問題が生じると指摘しました。 VTPは表現学習と圧縮再構築を共同で最適化し、モデルのスケール、データ、計算能力が拡大した際にトークナイザーがより安定的に下流の生成品質向上に翻訳できるようにし、標準的なDiTトレーニング仕様を変更しないようにします。
2. コア機能
- 3種類の目標の共同最適化:グラフィックおよびテキスト比較学習、自己教師あり学習および再構築目標の共同トレーニング(意味表現と復号を考慮したもの)。
- スケーラブルなトークナイザーのスケーリング:トークナイザーの事前学習に計算能力を投資することで、単に再構成誤差を減らすだけでなく、下流の生成効果をもたらすことを強調します。
- 世代指向評価リンク:理解(ゼロショット/リニアプロービング)、再構築(rFID)、生成(LightningDiTに基づくFID)の統合制御を提供します。
- オープンソースの重みとマルチサイズモデル:Hugging Faceは、リソースや効果に基づくトレードオフを可能にするために、Small/Base/Largeなどのモデル仕様を提供しています。
3. インストール
- 環境を作成する:condaはPython 3.10環境を作成し、それを有効化します。
- サブモジュールの初期化:ウェアハウスはサブモジュールを使って依存コードの一部を管理し、再帰的に引き出します。
- 依存関係のインストール:要件に従ってPythonの依存関係をインストールします。
- 評価スクリプトを実行する:スクリプトの記述に従ってパスを変更し、ゼロサンプル、線形検出、再構成、生成評価スクリプトを実行します。 評価リンクを作成し、LightningDiT関連スクリプトを使って特徴抽出、トレーニング、サンプリングを完了します。
4. 典型的なユースケース
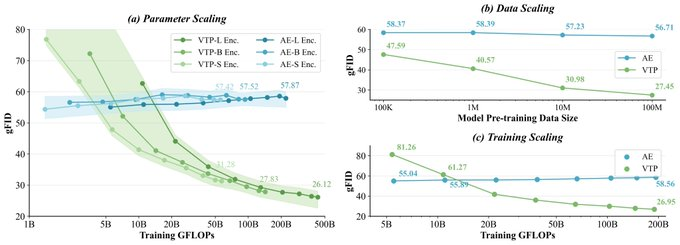
- DiT/拡散モデルのステージ1トークナイザー:「より強い潜在的」が生成品質と収束速度に与える影響を、生成構造を変えずに検証する。
- 視覚的表現抽出:検索、分類、クラスタリング、または下流のライトタスク(ゼロショットおよびリニアプロービング)に使用されます。
- 再構築と意味論的トレードオフの研究:従来のVAE/VQトークナイザーと比較して、表現学習を加えた後の潜在空間の意味論および生成学習可能性の変化を分析します。
- 実験曲線の再現:オープンソーススクリプトに基づき、パラメータ/データ/計算能力の次元をスケーリング比較してトークナイザーと生成性能の相関曲線を構築します。
5. 生態学と競合製品
- 関連生態学:トレーニングと評価の連携は比較学習、自己教師あり表現学習、DiT生成評価プロセスを含み、主流の視覚表現および拡散生成システムと整合させるのに役立ちます。
- 競合製品の方向性:従来のLDMは一般的に再構築されたVAE、VQ-VAE/VQGANなどをトークナイザーとして使用します。 蒸留や規則性を通じて潜空間を強化する改良されたルートもあります。 VTPの違いは、「理解/特性付け」を生成スケーラビリティの主要な推進力とし、体系的な評価によって下流生成への利益を検証する点にあります。
6. 制限と注意点
- リソース閾値:大規模なトークナイザーの事前学習および生成評価の完全な再現には、強力な計算能力、データ、エンジニアリングパイプラインが必要です。
- エンジニアリング統合コスト:既存のトークナイザーを交換する前に、潜在変数インターフェース、圧縮比、復号速度、エンドツーエンドの安定性を評価する必要があります。
- 結果は訓練式に依存します。異なるデータ分布、サンプリング戦略、ジェネレーター設定が最終指標に影響を与え、厳格な予算比較と目視検査を行うことが推奨されます。
- プロジェクトはまだ進化中であり、一部のモデル/スクリプトや指示はバージョン更新時に調整される可能性があるため、リポジトリやモデルページの最新内容を参照することを推奨します。
7. プロジェクトアドレス
https://github.com/MiniMax-AI/VTP
8. よくある質問
Q: VTP(Visual Tokenizer Pre-training)が解決する核心的な問題は何ですか?
A: 「ビジュアルトークナイザーの事前学習スケール問題」を解決します。つまり、従来のトークナイザーがトレーニングを再構築するだけで、より多くの計算能力を下流のDiTや拡散生成の品質向上に安定的に変換するのは難しいということです。
Q: なぜVTPは生成において表現学習を重視しているのでしょうか(拡散トランス/DiT)?
A: この考え方は、高度な意味論や構造により依存する学習可能な潜在空間を生成することです。 ピクセルレベルの再構成精度を追求しなければ、潜在空間を低レベルの情報にしやすくなり、発電収益の停滞を招く可能性があります。
Q: VTPは発電機のトレーニング出力を上げずに発電品質を向上させることができますか?
A: 主なインクリメントをトークナイザーの事前学習側に置き、標準的なDiTトレーニング仕様を比較対象に保つことで、より良い生成とより良いレイテンシを実現することが目標です。
Q: ハグフェイスでVTP-スモール/ベース/ラージはどう選べばいいですか?
A: 一般的に、大型トークナイザーは表現能力が強くなりますが、リソースの必要量は高くなります。 まずはSmall/Baseで評価リンクを通し、その後同じ予算内でLlargeの利点を評価できます。
Q: 既存のLDMのVAE/VQトークナイザーを置き換える際、何に注力すべきでしょうか?
A: 潜在可変形状と界面の互換性、圧縮率と復号速度、生成訓練の安定性、FID/収束速度、そして同じ訓練予算内での主観的な品質比較に焦点を当てます。