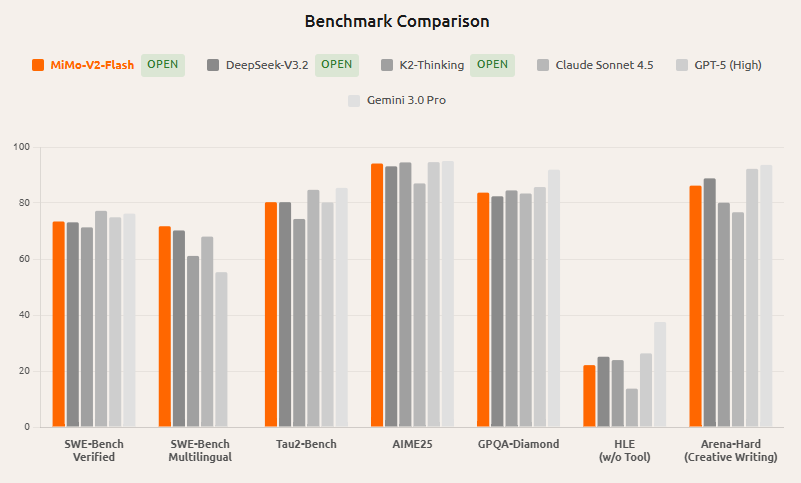
1. 추상
VTP(Visual Tokenizer Pre-training)는 MiniMax(Hailuo) 팀이 개발한 오픈 소스 시각 토큰나이저 사전 학습 프레임워크로, 확산 모델과 확산 변환기(DiT)와 같은 차세대 생성 모델을 대상으로 합니다. 프로젝트는 전통적인 '재구성 전용' 토큰라이저 훈련이 잠재 공간을 저수준 픽셀 정보 쪽으로 편향시켜, '재구성이 더 정확하지만 반드시 더 나은 생성은 아니다'라는 사전 학습 스케일링 문제를 초래한다고 지적했습니다. VTP는 표현 학습과 압축-재구성을 공동으로 최적화하여, 토큰라이저가 모델 규모, 데이터, 컴퓨팅 파워가 확장될 때 하위 생성 품질 향상으로 보다 안정적으로 전환할 수 있도록 하며, 표준 DiT 훈련 명세를 변경하지 않도록 할 것입니다.
2. 핵심 특징
- 세 가지 유형의 목표(그래픽 및 텍스트 비교 학습, 자기 지도 학습 및 재구성 목표 공동 훈련)의 공동 최적화, 의미 표현과 해독 고려.
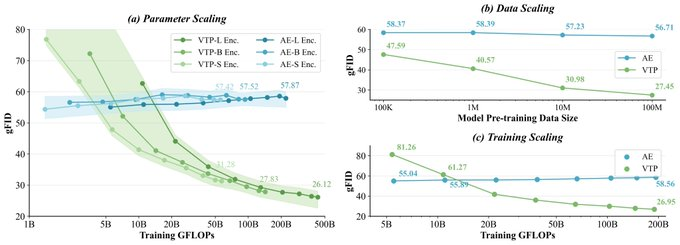
- 확장 가능한 토큰화 확장: 토큰화 사전 학습에 컴퓨팅 파워를 투자하면 단순히 재구성 오류를 줄이는 것보다 하위 생성 이점이 있음을 강조합니다.
- 세대 지향 평가 링크: 이해(제로 샷/선형 탐침), 재구성(rFID), 생성(라이트닝DiT 기반 FID)의 통합 제어 기능을 제공합니다.
- 오픈 소스 가중치와 다중 크기 모델: Hugging Face는 자원과 효과에 따른 상충을 용이하게 하기 위해 Small/Base/Large와 같은 모델 사양을 제공합니다.
3. 설치
- 환경 생성: conda는 Python 3.10 환경을 생성하고 활성화합니다.
- 서브모듈 초기화: 웨어하우스는 서브모듈을 사용하여 일부 의존 코드를 관리하며, 이 코드는 재귀적으로 끌어와야 합니다.
- 의존성 설치: 요구사항에 따라 파이썬 의존성을 설치하세요.
- 평가 스크립트 실행: 스크립트 설명에 따라 경로를 수정하고 제로 샘플, 선형 검출, 재구성 및 생성 평가 스크립트를 실행; 평가 링크를 생성하고 LightningDiT 관련 스크립트를 사용해 특징 추출, 학습, 샘플링을 완료하세요.
4. 일반적인 사용 사례
- DiT/확산 모델의 1단계 토큰라이저: 생성기 구조를 변경하지 않고 '강한 잠재'가 생성 품질과 수렴 속도에 미치는 영향을 검증합니다.
- 시각적 표현 추출: 검색, 분류, 클러스터링 또는 하위 조명 작업(제로 샷 및 선형 탐지)에 사용됩니다.
- 재구성-의미적 상충 연구: 전통적인 VAE/VQ 토큰라이저와 비교하여, 표현 학습을 추가한 잠재 공간의 의미론과 생성 학습 가능성 변화를 분석한다.
- 실험 곡선 재현: 오픈 소스 스크립트를 기반으로 매개변수/데이터/컴퓨팅 파워 차원의 스케일링 비교를 사용하여 토큰라이저와 생성 성능 간의 상관 곡선을 구성합니다.
5. 생태학과 경쟁 제품
- 관련 생태학: 훈련 및 평가 연계는 비교 학습, 자기 지도 표상 학습, DiT 생성 평가 과정을 포함하며, 이는 주류 시각 표현 및 확산 생성 시스템과 일치하는 데 편리합니다.
- 경쟁 제품의 방향성: 전통적인 LDM은 일반적으로 재구성된 VAE, VQ-VAE/VQGAN 등을 토큰 화자로 사용합니다; 증류나 규칙성을 통해 잠재 공간을 강화하는 개선된 경로도 있습니다. VTP의 차이점은 생성적 확장성의 핵심 동인으로 '이해/특성화'를 삼아 체계적인 평가를 통해 하위 생성에 대한 이점을 검증한다는 점입니다.
6. 제한 및 주의사항
- 자원 임계치: 대규모 토큰라이저의 사전 학습 및 생성 평가를 완전히 재생산하려면 강력한 컴퓨팅 파워, 데이터, 그리고 엔지니어링 파이프라인이 필요합니다.
- 엔지니어링 통합 비용: 기존 토큰라이저를 교체하기 전에 잠재 변수 인터페이스, 압축비, 디코딩 속도, 종단 간 안정성을 평가해야 합니다.
- 결과는 학습 공식에 따라 다릅니다: 데이터 분포, 표본 추출 전략, 생성기 설정에 따라 최종 지표가 영향을 미치므로, 엄격한 예산 비교와 시각적 검사가 권장됩니다.
- 프로젝트는 아직 진화 중입니다: 일부 모델/스크립트 및 지침은 버전 업데이트에 따라 조정될 수 있으므로, 저장소와 모델 페이지의 최신 내용을 참고하시기 바랍니다.
7. 프로젝트 주소
https://github.com/MiniMax-AI/VTP
8. 자주 묻는
질문: VTP(Visual Tokenizer Pre-training)가 해결한 핵심 문제는 무엇인가요?
A: "시각적 토큰라이저 사전 학습 스케일 문제"를 해결하세요. 즉, 전통적인 토큰라이저가 훈련만 재구축하는 방식으로는 더 많은 컴퓨팅 파워를 다운스트림 DiT/확산 생성 품질 향상으로 안정적으로 전환하기 어렵다는 점입니다.
Q: 왜 VTP가 생성에 표현 학습을 더 중요하게 여기나요(확산 트랜스포머/DiT)?
A: 아이디어는 고수준 의미론과 구조에 더 의존하는 학습 가능한 잠재 공간을 생성하는 것입니다; 픽셀 수준의 재구성 정확도만을 추구하면 잠재 공간을 저수준 정보로 쉽게 만들어 발전 수익이 정체될 수 있습니다.
Q: VTP가 발전기의 훈련 전력을 늘리지 않고 발전 품질을 향상시킬 수 있나요?
A: 목표는 주요 증가분을 토큰나이저 사전 학습 쪽에 두고, 표준 DiT 훈련 명세를 비교 가능하게 유지하여 더 나은 생성과 더 나은 지연 시간을 제공하는 것입니다.
Q: 포옹하는 얼굴에서 VTP-스몰/베이스/라지는 어떻게 선택해야 하나요?
A: 일반적으로 대형 토큰라이저는 더 강한 표현 능력을 가지지만 자원 요구량이 더 높습니다; Small/Base를 사용해 먼저 평가 링크를 거쳐보고, 같은 예산으로 Large의 이점을 평가할 수 있습니다.
Q: 기존 LDM의 VAE/VQ 토큰라이저를 교체할 때 무엇에 집중해야 하나요?
A: 잠재 가변 형태와 인터페이스 호환성, 압축률과 디코딩 속도, 생성 훈련 안정성, FID/수렴 속도 및 동일한 훈련 예산 내에서 주관적 품질 비교에 집중합니다.