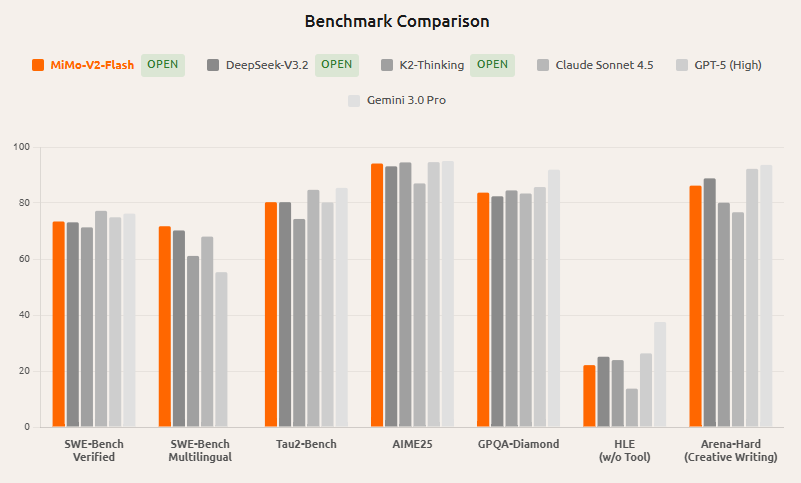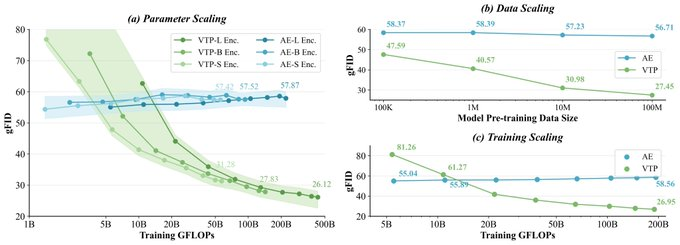
1. Abstract
VTP (Visual Tokenizer Pre-training) est un cadre open source de pré-entraînement de tokenizer visuel développé par l’équipe MiniMax (Hailuo), destiné aux modèles génératifs de nouvelle génération tels que les modèles de diffusion et le Transformateur de diffusion (DiT). Le projet a souligné que l’entraînement traditionnel « reconstruction uniquement » par tokenizer biaise l’espace latent vers des informations pixelisées de bas niveau, ce qui entraîne le problème de l’échelle pré-entraînement selon lequel « la reconstruction est plus précise mais pas nécessairement meilleure génération ». VTP optimisera conjointement l’apprentissage de la représentation et la reconstruction par compression, afin que le tokeniseur puisse se traduire plus sablement en amélioration de la qualité de la génération en aval lorsque l’échelle du modèle, les données et la puissance de calcul augmentent, et essayer de ne pas modifier les spécifications d’entraînement standard DiT.
2. Caractéristiques principales
- Optimisation conjointe de trois types d’objectifs : apprentissage par comparaison graphique et texte, apprentissage auto-supervisé et formation conjointe pour objectifs de reconstruction, en tenant compte de la représentation sémantique et du décodage.
- Scaling scalable du tokenizer : En soulignant que l’investissement en puissance de calcul dans la pré-formation du tokenizer peut apporter des bénéfices de génération en aval, plutôt que de simplement rechercher des erreurs de reconstruction moindres.
- Liaison d’évaluation orientée génération : Fournir un contrôle intégré de la compréhension (sonde zéro-shot/linéaire), de la reconstruction (rFID) et de la génération (FID basé sur LightningDiT).
- Poids open source et modèles multi-tailles : Hugging Face fournit des spécifications de modèles telles que Petit/Base/Large pour faciliter des compromis basés sur les ressources et les effets.
3. Installation
- Créer un environnement : conda crée un environnement Python 3.10 et l’active.
- Initialisation des sous-modules : L’entrepôt utilise des sous-modules pour gérer un code dépendant, qui doit être extrait récursivement.
- Installer des dépendances : Installer des dépendances Python selon les besoins.
- Exécuter le script d’évaluation : modifier le chemin selon la description du script et exécuter le script d’évaluation à zéro échantillon, détection, reconstruction linéaire et génération ; Générez un lien d’évaluation et utilisez des scripts liés à LightningDiT pour réaliser l’extraction de fonctionnalités, la formation et l’échantillonnage.
4. Cas d’usage typiques
- Tokeniseur de phase 1 du modèle DiT/diffusion : Vérifier l’influence d’un « latent plus fort » sur la qualité de génération et la vitesse de convergence sans modifier la structure du générateur.
- Extraction de représentation visuelle : utilisée pour la récupération, la classification, le clustering ou des tâches éclaircées en aval (cero-coup et sondage linéaire).
- Échange entre reconstruction et sémantique recherche : Comparé au tokeniseur VAE/VQ traditionnel, les changements sémantiques et d’apprentissage génératif de l’espace latent après l’ajout de l’apprentissage des représentations sont analysés.
- Reproduire la courbe expérimentale : Sur la base du script open source, la comparaison d’échelle des paramètres/données/dimensions de puissance de calcul est utilisée pour construire la courbe de corrélation entre la performance du tokeniseur et la génération.
5. Écologie et produits concurrents
- Écologie connexe : Le lien de formation et d’évaluation implique l’apprentissage comparatif, l’apprentissage par représentation autonome et les processus d’évaluation de génération de DiT, ce qui est pratique pour s’aligner avec les systèmes de représentation visuelle et de génération par diffusion traditionnels.
- Orientation des produits concurrents : LDM traditionnel utilisé couramment VAE, VQ-VAE/VQGAN, etc. reconstruit comme tokeniseurs ; Il existe également des voies améliorées pour améliorer l’espace latent par distillation ou régularité. La différence avec la VTP est qu’elle prend la « compréhension/caractérisation » comme moteur clé de la scalabilité générative et vérifie son gain en génération en aval par une évaluation systématique.
6. Limitations et précautions
- Seuil de ressources : La reproduction complète de l’entraînement et de l’évaluation de génération de tokenizers à grande échelle nécessite une puissance de calcul, des données et des pipelines d’ingénierie solides.
- Coût d’intégration d’ingénierie : Avant de remplacer le tokeniseur existant, il est nécessaire d’évaluer l’interface à variables latentes, le taux de compression, la vitesse de décodage et la stabilité de bout en bout.
- Les résultats dépendent de la formule d’entraînement : différentes distributions de données, stratégies d’échantillonnage et réglages du générateur influenceront les indicateurs finaux, et il est recommandé de procéder à une comparaison budgétaire stricte et à une inspection visuelle.
- Le projet est encore en évolution : certains modèles/scripts et instructions peuvent être ajustés avec des mises à jour de versions, et il est recommandé de se référer au contenu récent du dépôt et des pages de modèles.
7. Adresse du projet
https://github.com/MiniMax-AI/VTP
8. FAQ
Q : Quel est le problème central résolu par VTP (Visual Tokenizer Pre-training) ?
R : Résoudre le « problème de l’échelle pré-entraînement du tokenizer visuel », c’est-à-dire qu’il est difficile pour les tokenizers traditionnels, qui ne font que reconstruire l’entraînement, de convertir de manière stable plus de puissance de calcul en amélioration de la qualité de la génération de DiT/diffusion en aval.
Q : Pourquoi l’accent mis par la VTP sur l’apprentissage représentationnel est-il plus important pour la génération (Transformateur de diffusion/DiT) ?
R : L’idée est de générer un espace latent apprenable qui repose davantage sur la sémantique et la structure de haut niveau ; Seule la recherche d’une précision de reconstruction au niveau des pixels peut facilement rendre l’espace latent en information de bas niveau, entraînant une stagnation des revenus de production.
Q : Le VTP peut-il améliorer la qualité de production sans augmenter la puissance d’entraînement du générateur ?
R : L’objectif est de mettre l’incrément principal du côté pré-entraînement du tokenizer et d’essayer de garder les spécifications standard d’entraînement DiT comparables, afin de favoriser une meilleure génération avec une meilleure latence.
Q : Comment devrais-je choisir VTP-Petit/Base/Large sur le visage de câlin ?
R : En général, les tokenizateurs plus grands ont des capacités de représentation plus fortes mais des besoins en ressources plus élevés ; Vous pouvez utiliser Small/Base pour passer d’abord par le lien d’évaluation, puis évaluer les avantages de Large avec le même budget.
Q : Sur quoi dois-je me concentrer lorsque je remplace le tokeniseur VAE/VQ d’un LDM existant ?
R : Accent sur la compatibilité de la forme et de l’interface des variables latentes, le taux de compression et la vitesse de décodage, la stabilité de l’entraînement à la génération, ainsi que la comparaison de la vitesse FID/convergence et de la qualité subjective sous le même budget d’entraînement.