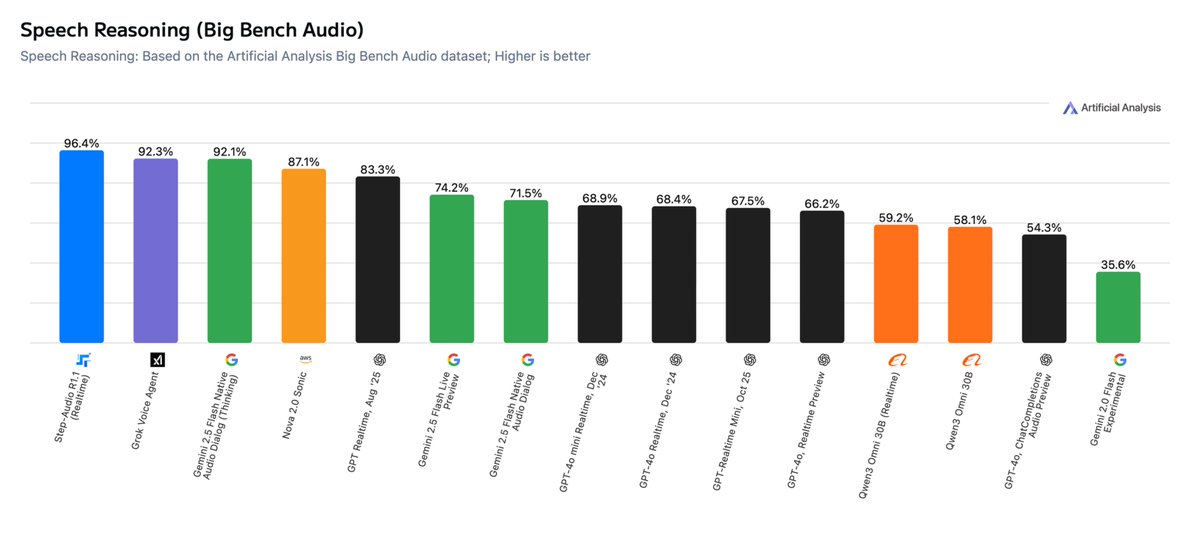
Step-Audio-R1.1 was announced and ranked first in Artificial Analysis's Speech Reasoning list. It achieved an accuracy rate of about 96.4% in the BigBench Audio test, while achieving a first-frame audio output of about 1.51 seconds in real-time dialogue scenes. The project team emphasized that the model strikes a balance between deep reasoning and interaction latency for scenarios that are closer to real voice conversations.
According to the official introduction, R1.1 introduces "scaling of computing power during testing" in the inference stage, and strengthens end-to-end audio inference and scalable CoT for audio task optimization. The model weights are open and can be downloaded directly on the community platform. At the same time, it provides an online experience entrance. It should be noted that the difference between the list evaluation method and the device network may affect the actual performance, and the specific effect still depends on the application scenario and deployment conditions.
FAQs
Q: What is Step-Audio-R1.1?
A: Step-Audio-R1.1 is a large audio model for voice dialogue, emphasizing deep reasoning and low latency.
Q: What are the achievements of Step-Audio-R1.1?
A: The published results include BigBench Audio with an accuracy rate of about 96.4% and a TTFA of about 1.51 seconds, and it ranks first in the relevant list.
Q: What are the technical features of Step-Audio-R1.1?
A: The model uses scale-on-test computing power scaling, end-to-end audio inference, and scalable audio-oriented CoT.
Q: Is Step-Audio-R1.1 open source?
A: Weights and resources are publicly available and available on mainstream community platforms for local deployment.
Q: Where can I try Step-Audio-R1.1?
A: You can experience it through the online demo page, or you can download the weights on the platform page and run it yourself.



