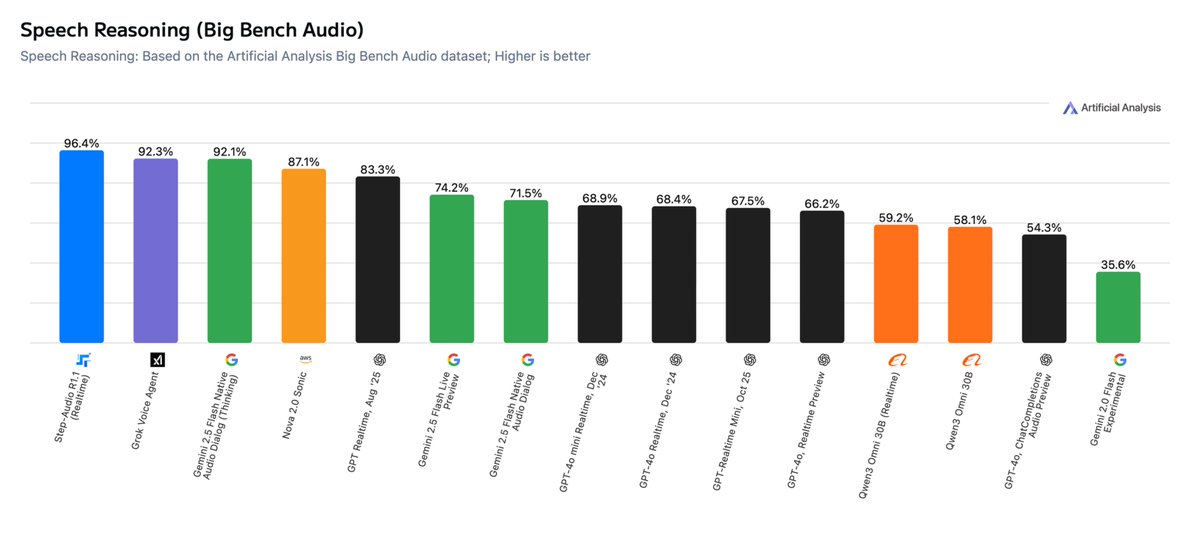
Step-Audio-R1.1が発表され、Artificial Analysisの音声推論リストで1位にランクされました。 BigBench Audioテストでは約96.4%の精度を達成し、リアルタイムの会話シーンでは約1.51秒の初フレーム音声出力を達成しました。 プロジェクトチームは、このモデルが実際の音声会話に近いシナリオにおいて、深い推論とインタラクションレイテンシのバランスを取っていることを強調しました。
公式導入によると、R1.1は推論段階で「テスト中の計算能力のスケーリング」を導入し、オーディオタスク最適化のためのエンドツーエンドオーディオ推論とスケーラブルなCoTを強化しています。 モデルの重みはオープンで、コミュニティプラットフォームから直接ダウンロードできます。 同時に、オンライン体験の入場も提供しています。 リスト評価方法とデバイスネットワークの違いは実際の性能に影響を与える可能性があり、具体的な効果はアプリケーションシナリオや展開条件によって異なります。
よくある質問
Q: Step-Audio-R1.1とは何ですか?
A: Step-Audio-R1.1は、深い推論と低遅延を重視した大規模な音声ダイアログモデルです。
Q: Step-Audio-R1.1の成果は何ですか?
A: 公開されている結果には、BigBench Audioの約96.4%の精度と約1.51秒のTTFAが含まれており、関連リストで1位にランクされています。
Q: Step-Audio-R1.1の技術的特徴は何ですか?
A: このモデルは、スケールオンテストの計算能力スケーリング、エンドツーエンドのオーディオ推論、そしてスケーラブルなオーディオ指向のCoTを使用しています。
Q: Step-Audio-R1.1はオープンソースですか?
A: 重りやリソースは一般公開されており、地域のコミュニティプラットフォームでもローカル展開が可能です。
Q: Step-Audio-R1.1はどこで試せますか?
A: オンラインデモページで体験することもできますし、プラットフォームのページでウェイトをダウンロードして自分でプレイすることもできます。



