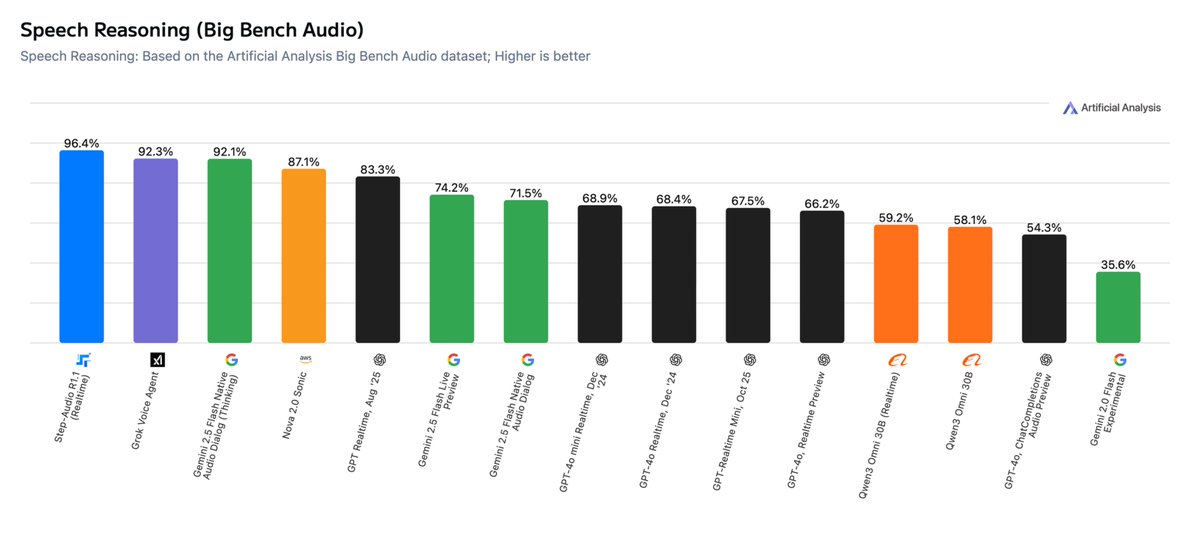
Step-Audio-R1.1 a été annoncé et classé premier dans la liste Speech Reasoning d’Artificial Analysis. Il a atteint un taux de précision d’environ 96,4 % lors du test audio BigBench, tout en obtenant une sortie audio d’environ 1,51 seconde sur la première image dans les scènes de dialogue en temps réel. L’équipe projet a souligné que le modèle trouve un équilibre entre raisonnement profond et latence d’interaction pour des scénarios proches de conversations vocales réelles.
Selon l’introduction officielle, R1.1 introduit « une mise à l’échelle de la puissance de calcul lors des tests » à l’étape d’inférence, et renforce l’inférence audio de bout en bout ainsi que la CoT évolutive pour l’optimisation des tâches audio. Les poids des modèles sont ouverts et peuvent être téléchargés directement sur la plateforme communautaire. En même temps, il offre une entrée d’expérience en ligne. Il convient de noter que la différence entre la méthode d’évaluation par liste et le réseau de dispositifs peut affecter la performance réelle, et l’effet spécifique dépend toujours du scénario d’application et des conditions de déploiement.
FAQ
Q : Qu’est-ce que Step-Audio-R1.1 ?
R : Step-Audio-R1.1 est un modèle audio volumineux pour le dialogue vocal, mettant l’accent sur un raisonnement profond et une faible latence.
Q : Quels sont les accomplissements de Step-Audio-R1.1 ?
R : Les résultats publiés incluent BigBench Audio avec un taux de précision d’environ 96,4 % et un TTFA d’environ 1,51 seconde, et il se classe premier dans la liste concernée.
Q : Quelles sont les caractéristiques techniques de Step-Audio-R1.1 ?
R : Le modèle utilise la mise à l’échelle de la puissance de calcul à l’échelle en test, l’inférence audio de bout en bout et un CoT orienté audio évolutif.
Q : Step-Audio-R1.1 est-il open source ?
R : Les poids et ressources sont accessibles au public et disponibles sur les plateformes communautaires principales pour le déploiement local.
Q : Où puis-je essayer Step-Audio-R1.1 ?
R : Vous pouvez le découvrir via la page de démonstration en ligne, ou télécharger les poids sur la page plateforme et le faire vous-même.



