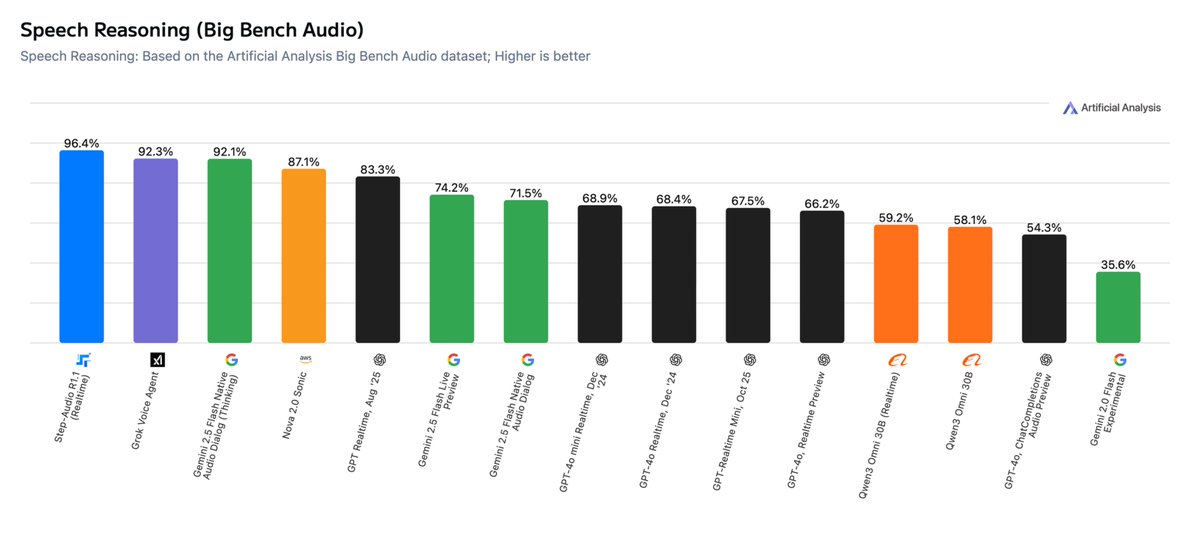
Step-Audio-R1.1 wurde angekündigt und belegte den ersten Platz in der Speech Reasoning-Liste von Artificial Analysis. Im BigBench Audio-Test erreichte es eine Genauigkeitsrate von etwa 96,4 %, während es in Echtzeit-Dialogszenen eine Erstbild-Audioausgabe von etwa 1,51 Sekunden erzielte. Das Projektteam betonte, dass das Modell ein Gleichgewicht zwischen tiefem Denken und Interaktionslatenz für Szenarien schafft, die näher an echten Sprachgesprächen liegen.
Laut der offiziellen Einführung führt R1.1 in der Inferenzphase eine "Skalierung der Rechenleistung während des Tests" ein und stärkt die End-to-End-Audioinferenz sowie skalierbare CoT zur Optimierung von Audioaufgaben. Die Modellgewichte sind offen und können direkt auf der Community-Plattform heruntergeladen werden. Gleichzeitig bietet es einen Online-Erlebnis-Eingang. Es sollte beachtet werden, dass der Unterschied zwischen der Listenbewertungsmethode und dem Gerätenetzwerk die tatsächliche Leistung beeinflussen kann und der spezifische Effekt weiterhin vom Anwendungsszenario und den Bereitstellungsbedingungen abhängt.
FAQs
F: Was ist Step-Audio-R1.1?
A: Step-Audio-R1.1 ist ein großes Audiomodell für Sprachdialoge, das tiefgründiges Denken und geringe Latenz betont.
F: Was sind die Errungenschaften von Step-Audio-R1.1?
A: Die veröffentlichten Ergebnisse umfassen BigBench Audio mit einer Genauigkeitsrate von etwa 96,4 % und einer TTFA von etwa 1,51 Sekunden, und es belegt den ersten Platz in der relevanten Liste.
F: Was sind die technischen Merkmale von Step-Audio-R1.1?
A: Das Modell verwendet skalierbare Rechenleistungsskalierung, End-to-End-Audioinferenz und skalierbares, audioorientiertes CoT.
F: Ist Step-Audio-R1.1 Open Source?
A: Gewichte und Ressourcen sind öffentlich verfügbar und auf den etablierten Community-Plattformen für den lokalen Einsatz verfügbar.
F: Wo kann ich Step-Audio-R1.1 ausprobieren?
A: Du kannst es über die Online-Demo-Seite erleben oder die Gewichte auf der Plattformseite herunterladen und selbst ausführen.



