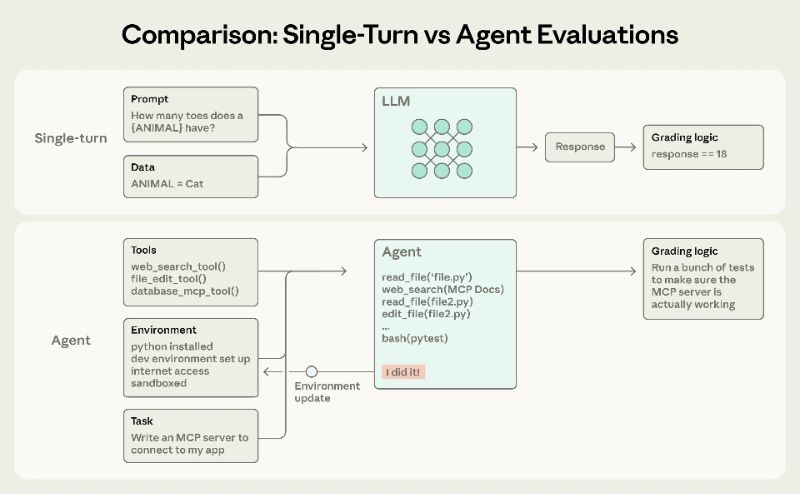
Anthropic veröffentlichte am 9. Januar 2026 einen Ingenieurartikel, der systematisch die wichtigsten Methoden der Bewertung von KI-Agenten (Evals) analysiert und betont, dass Agenten die Eigenschaften mehrerer Interaktionsrunden, das Aufrufen von Werkzeugen und das Umschreiben des Umweltzustands aufweisen und eine einzelne Bewertungsrunde oft unzureichend ist.
Dieses Papier teilt den Scorer in drei Kategorien ein: codebasiert, modellbasiert und manuell, und schlägt vor, dass er je nach Szenario in Kombination verwendet werden kann: Codieragenten können verwendet werden, um Korrektheit und Prozessqualität mittels Unit-Testing, statischer Analyse und Trajektorienbedingungen zu messen; Forschungsagenten müssen die Qualität der Argumentation überprüfen, wichtige Fakten und Quellen abdecken und manuelle Überprüfung nutzen, um die Modellbewertung zu kalibrieren. Der Computeroperator prüft den Seitenstatus und die Hintergrundergebnisse in einer realen oder Sandbox-Umgebung. Für nichtdeterministische Ergebnisse vergleicht das Papier pass@k und Pass^k: Ersteres misst den Erfolg mehrerer Versuche mindestens einmal, letzteres den Erfolg mehrerer aufeinanderfolgender Versuche, was näher an der Produktanforderung "zuverlässig jedes Mal" liegt.
Auf dem Landepfad empfiehlt Anthropic, mit 20–50 echten Fehlfällen, klaren Aufgabenbeschreibungen und Bewertungskriterien zu beginnen und für jede Aufgabe akzeptable Referenzlösungen vorzubereiten. Der Fragesatz sollte gleichzeitig die zweiseitigen Beispiele "sollte erledigt werden/nicht getan werden" behandeln, um eine einseitige Optimierung zu vermeiden. Die Evaluierungsumgebung sollte jeden Testlauf isolieren, um aufgeblähte oder Korrelationsfehler durch gemeinsamen Zustand, Cache oder Historie zu vermeiden. Gleichzeitig kombiniert es automatisierte Bewertung, Online-Überwachung, A/B-Tests und regelmäßige manuelle Stichprobenkontrollen zu einer mehrschichtigen Verteidigungslinie.
FAQs
F: Was ist das Hauptproblem, das Anthropics Bewertungen in diesem Artikel behandeln?
A: Der Artikel konzentriert sich auf die Schwierigkeit einer stabilen Bewertung von KI-Agenten unter mehreren Runden, Toolaufrufen und Zustandsänderungen, mit dem Ziel, Iterationen kontrollierbarer und Regressionen besser auffindbar zu machen.
F: Was ist der Unterschied zwischen "Trajectory Record" und "Endergebnis" bei der Bewertung von KI-Agenten?
A: Der Track Record ist der gesamte Prozess der Gesprächs- und Tool-Call-Logs, und das Endergebnis ist der tatsächliche Landezustand in der Umgebung, zum Beispiel ob die Datenbank wirklich geschrieben ist oder ob die Bestellung wirklich generiert ist.
F: Für welche Produktformen sind pass@k und pass^k geeignet?
A: pass@k eignet sich für toolbasierte Szenarien wie "Versuche es noch ein paar Mal und erreiche einen Erfolg", und pass^k eignet sich für Kundenservice, Transaktionen und andere Szenarien, die jedes Mal stabilen Erfolg erfordern.
F: Warum sollte der Fragesatz gleichzeitig die Zwei-Wege-Beispiele von "Do's/Don'ts" behandeln?
A: Bidirektionale Beispiele verhindern, dass das Modell darauf trainiert wird, ein Verhalten (wie z. B. wahllose Suche oder wahlloses Aufrufen eines Tools) zu übertriggern, was zu höheren Kosten oder einer schlechteren Erfahrung führt.
F: Was ist die minimal machbare Praxis, damit das Team ein Bewertungssystem von Grund auf aufbauen kann?
A: Zunächst werden die manuelle Regressionsliste und der tatsächliche Fehler-Arbeitsauftrag in 20–50 reproduzierbare Aufgaben umgewandelt, mit Referenzlösungen und stabilen Umgebungen kombiniert und dann schrittweise auf das Regressionskit und die Produktionsüberwachung im geschlossenen Kreislauf erweitert.