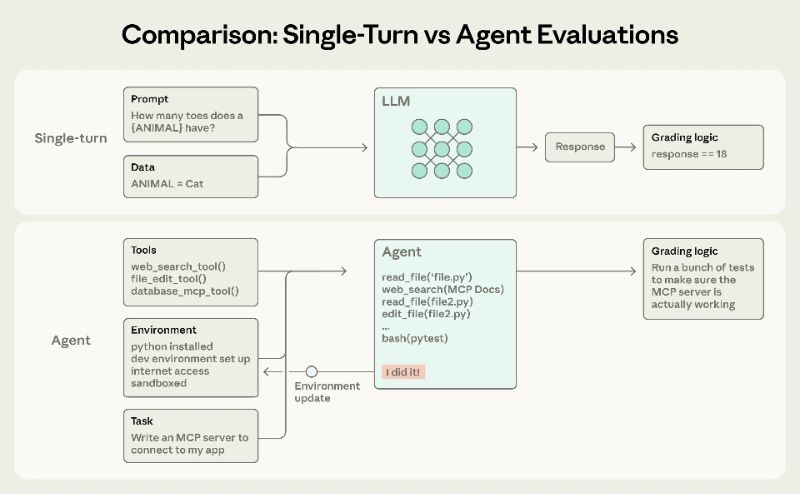
Anthropic于2026年1月9日发布工程文章,系统拆解AI代理(AI agents)评测(evals)的关键方法,强调代理具备多轮交互、调用工具与改写环境状态等特性,单轮评测往往不足,需围绕“任务、试次、评分器、轨迹记录与最终结果”建立可复现的自动化评测体系,以减少上线后被动修复与质量回退。
文章将评分器分为代码型、模型型与人工三类,并建议按场景组合使用:编码代理可用单元测试、静态分析与轨迹约束衡量正确性与过程质量;研究代理更需检查论据支撑、覆盖关键事实与来源质量,并用人工评审校准模型评分;电脑操作代理则要在真实或沙盒环境中核验页面状态与后台结果。针对非确定性输出,文中对比pass@k与pass^k:前者衡量多次尝试至少一次成功,后者衡量连续多次都成功,更贴近“每次都要可靠”的产品要求。
在落地路径上,Anthropic建议从20–50个真实失败案例起步,任务描述与判定标准要清晰,并为每个任务准备可通过的参考解;题集需同时覆盖“该做/不该做”的双向样例,避免单边优化。评测环境应隔离每次试运行,防止共享状态、缓存或历史记录带来虚高或相关性失败;同时结合自动化评测、上线监控、A/B测试与定期人工抽查,形成多层防线。
常见问题
Q:Anthropic这篇文章讨论的Evals主要解决什么问题?
A:文章聚焦AI代理在多轮、工具调用与状态变更下难以稳定评估的问题,目标是让迭代更可控、回归更可发现。
Q:AI代理评测里的“轨迹记录”和“最终结果”有什么区别?
A:轨迹记录是全过程对话与工具调用日志,最终结果是环境中的真实落地状态,例如数据库是否真的写入或订单是否真的生成。
Q:pass@k与pass^k分别适合哪些产品形态?
A:pass@k适合“多试几次有一次成功就行”的工具型场景,pass^k适合客服、交易等需要每次都稳定成功的场景。
Q:为什么题集要同时覆盖“该做/不该做”的双向样例?
A:双向样例能避免模型被训练成过度触发某行为(如无差别搜索或无差别调用工具),导致成本上升或体验变差。
Q:团队从零搭建评测体系的最小可行做法是什么?
A:先把手工回归清单与真实故障工单转成20–50个可复现任务,配套参考解与稳定环境,再逐步扩展到回归套件与生产监控闭环。