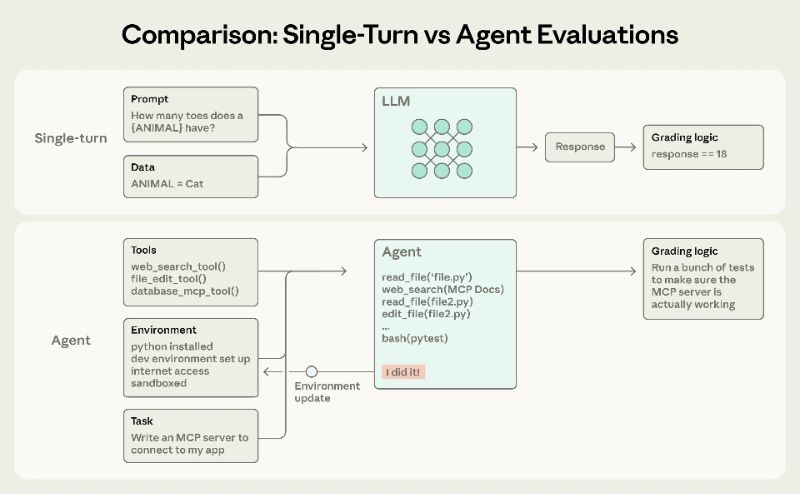
Anthropic은 2026년 1월 9일 AI 에이전트 평가(eval)의 핵심 방법을 체계적으로 해체하는 엔지니어링 기사를 발표했으며, 에이전트는 여러 차례의 상호작용, 도구를 호출하고 환경 상태를 재작성하는 특성을 가지고 있으며, 단일 평가 라운드로는 종종 충분하지 않다고 강조했습니다.
본 논문은 점수 측정기를 코드 기반, 모델 기반, 수동 세 가지 범주로 나누며, 시나리오에 따라 조합하여 사용할 수 있음을 제안합니다: 코딩 에이전트는 단위 테스트, 정적 분석, 궤적 제약 조건을 통해 정확성과 프로세스 품질을 측정할 수 있고; 연구 에이전트는 논증 지원의 질을 점검하고, 핵심 사실과 출처를 다루며, 수동 검토를 통해 모델 점수를 보정해야 합니다. 컴퓨터 운영 에이전트는 실제 또는 샌드박스 환경에서 페이지 상태와 배경 결과를 확인합니다. 비결정적 출력의 경우, 논문은 pass@k와 pass^k를 비교합니다: 전자는 최소 한 번은 다중 시도의 성공을 측정하고, 후자는 여러 번 연속된 시도의 성공률을 측정하는데, 이는 '매번 신뢰할 수 있다'는 곱 요구사항에 더 가깝습니다.
착륙 경로에서 Anthropic은 20에서 50건의 실제 실패 사례부터 시작하고, 명확한 작업 설명과 판단 기준을 작성하며, 각 작업에 대해 합리적인 참조 해법을 준비할 것을 권장합니다. 문제 세트는 '해야 할 것/하지 말아야 한다'는 양방향 예시를 동시에 포함해야 일방적 최적화를 피해야 합니다. 평가 환경은 공유 상태, 캐시 또는 기록으로 인한 과장되거나 상관관계 실패를 방지하기 위해 각 테스트 실행을 격리해야 합니다. 동시에 자동 평가, 온라인 모니터링, A/B 테스트, 정기적인 수동 현장 점검을 결합하여 다층적인 방어선을 형성합니다.
자주 묻는 질문
Q: 이 글에서 Anthropic의 평가가 논의하는 주요 문제는 무엇인가요?
답변: 이 글은 다중 라운드, 툴 호출, 상태 변화 하에서 AI 에이전트를 안정적으로 평가하는 어려움에 초점을 맞추고 있으며, 반복을 더 제어하고 회귀분석을 더 쉽게 발견할 수 있도록 하는 것을 목표로 합니다.
Q: AI 에이전트 평가에서 '궤적 기록'과 '최종 결과'의 차이는 무엇인가요?
A: 실적은 대화와 도구 호출 기록 전체 과정이며, 최종 결과는 데이터베이스가 실제로 작성되었는지, 명령이 실제로 생성되었는지 같은 실제 환경에서의 착지 상태입니다.
Q: 어떤 제품 형태가 pass@k and pass^k에 적합한가요?
A: pass@k는 "몇 번 더 시도해 성공한다"와 같은 도구 기반 시나리오에 적합하며, pass^k는 고객 서비스, 거래 및 매번 안정적인 성공이 필요한 기타 시나리오에 적합합니다.
Q: 왜 문제 세트가 양방향 '해야 할 일/하지 말아야 할 것' 예시를 동시에 다뤄야 하나요?
A: 양방향 예제는 모델이 무차별 탐색이나 도구 호출 같은 행동을 과도하게 유발하도록 학습되어 비용이 증가하거나 경험이 나빠지는 것을 방지합니다.
Q: 팀이 처음부터 평가 시스템을 구축할 수 있는 최소한의 실천 방법은 무엇인가요?
A: 먼저 수동 회귀 목록과 실제 결함 작업 지시서를 20-50개의 재현 가능한 작업으로 변환하고, 참조 솔루션과 안정적인 환경과 매칭한 후, 점차 회귀 키트와 생산 모니터링 폐쇄 루프로 확장합니다.