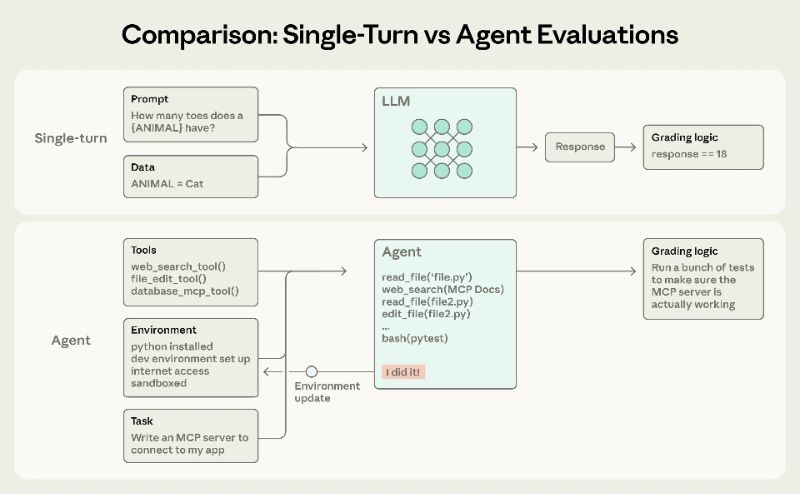
Anthropic released an engineering article on January 9, 2026, systematically dismantling the key methods of AI agents evaluation (evals), emphasizing that agents have the characteristics of multiple rounds of interaction, calling tools and rewriting the state of the environment, and a single round of evaluation is often insufficient.
This paper divides the scorer into three categories: code-based, model-based, and manual, and suggests that it can be used in combination according to scenarios: coding agents can be used to measure correctness and process quality using unit testing, static analysis, and trajectory constraints; Research agents need to check the quality of argument support, cover key facts and sources, and use manual review to calibrate model scoring. The computer operation agent checks the page status and background results in a real or sandboxed environment. For non-deterministic outputs, the paper compares pass@k and pass^k: the former measures the success of multiple attempts at least once, and the latter measures the success of multiple consecutive attempts, which is closer to the product requirement of "reliable every time".
On the landing path, Anthropic recommends starting with 20–50 real failure cases, clear task descriptions and judgment criteria, and preparing passable reference solutions for each task. The question set should cover the two-way examples of "should be done/not done" at the same time to avoid unilateral optimization. The evaluation environment should isolate each test run to prevent inflated or correlation failures caused by shared state, cache, or history. At the same time, it combines automated evaluation, online monitoring, A/B testing and regular manual spot checks to form a multi-layered line of defense.
FAQs
Q: What is the main problem that Anthropic's Evals discuss in this article?
A: The article focuses on the difficulty of stable evaluation of AI agents under multiple rounds, tool calls, and state changes, with the goal of making iterations more controllable and regressions more discoverable.
Q: What is the difference between "trajectory record" and "final result" in AI agent evaluation?
A: The track record is the whole process of conversation and tool call logs, and the final result is the real landing state in the environment, such as whether the database is really written or whether the order is really generated.
Q: Which product forms are pass@k and pass^k suitable for?
A: pass@k is suitable for tool-based scenarios such as "try a few more times and have one success", and pass^k is suitable for customer service, transactions and other scenarios that require stable success every time.
Q: Why should the question set cover the two-way examples of "do's/don'ts" at the same time?
A: Bidirectional examples prevent the model from being trained to over-trigger a behavior (such as indiscriminate search or indiscriminate calling a tool), resulting in higher costs or a worse experience.
Q: What is the minimum feasible practice for the team to build an evaluation system from scratch?
A: First, the manual regression list and the real fault work order are converted into 20-50 reproducible tasks, matched with reference solutions and stable environments, and then gradually expanded to the regression kit and production monitoring closed loop.