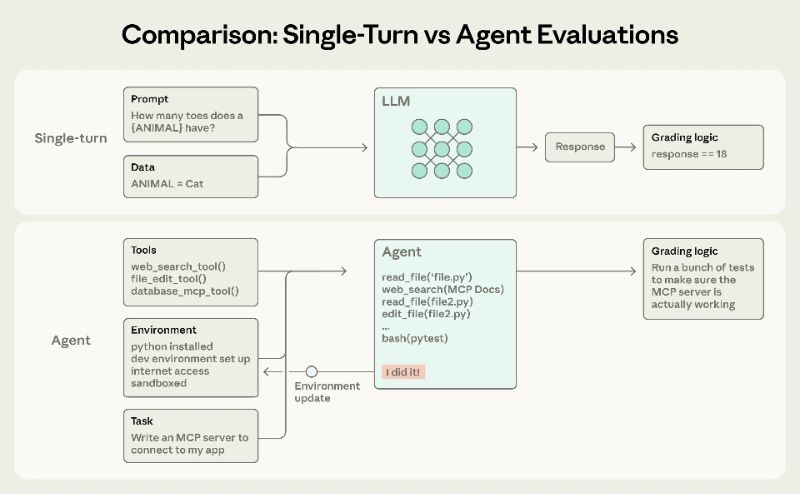
Anthropic a publié un article d’ingénierie le 9 janvier 2026, démontant systématiquement les principales méthodes d’évaluation des agents IA (évaluations), soulignant que les agents possèdent les caractéristiques de plusieurs tours d’interaction, appelant des outils et réécrivant l’état de l’environnement, et qu’un seul cycle d’évaluation est souvent insuffisant.
Cet article divise le scorer en trois catégories : basé sur le code, basé sur le modèle et manuel, et suggère qu’il peut être utilisé en combinaison selon les scénarios : les agents de codage peuvent être utilisés pour mesurer la correction et la qualité des processus en utilisant des contraintes de tests unitaires, d’analyse statique et de trajectoire ; Les agents de recherche doivent vérifier la qualité du soutien argumentaire, couvrir les faits et sources clés, et utiliser la revue manuelle pour calibrer la notation des modèles. L’agent informatique vérifie le statut de la page et les résultats de fond dans un environnement réel ou en bac à sable. Pour les résultats non déterministes, l’article compare pass@k et pass^k : le premier mesure le succès de plusieurs tentatives au moins une fois, et le second mesure le succès de plusieurs tentatives consécutives, ce qui se rapproche davantage de l’exigence du produit de « fiable à chaque fois ».
Sur la trajectoire d’atterrissage, Anthropic recommande de commencer par 20 à 50 cas réels de défaillance, des descriptions claires des tâches et des critères de jugement, et de préparer des solutions de référence passables pour chaque tâche. L’ensemble de questions doit couvrir les exemples à double sens de « devrait être fait/pas fait » en même temps afin d’éviter une optimisation unilatérale. L’environnement d’évaluation doit isoler chaque exécution de test afin d’éviter les défaillances gonflées ou corrélatives causées par un état partagé, un cache ou un historique. En même temps, il combine évaluation automatisée, surveillance en ligne, tests A/B et contrôles manuels réguliers pour former une ligne de défense à plusieurs niveaux.
FAQ
Q : Quel est le principal problème abordé par les évaluations d’Anthropic dans cet article ?
R : L’article se concentre sur la difficulté d’évaluer de manière stable les agents IA lors de plusieurs tours, des appels d’outils et des changements d’état, dans le but de rendre les itérations plus contrôlables et les régressions plus faciles à découvrir.
Q : Quelle est la différence entre « enregistrement de trajectoire » et « résultat final » dans l’évaluation des agents IA ?
R : Le bilan est tout le processus de conversation et de journaux d’appels d’outils, et le résultat final est l’état réel d’atterrissage dans l’environnement, comme si la base de données est réellement écrite ou si la commande est réellement générée.
Q : Pour quelles formes de produits pass@k et pass^k conviennent-elles ?
R : pass@k convient aux scénarios basés sur des outils tels que « essayez encore quelques fois et obtenez un succès », et pass^k convient au service client, aux transactions et à d’autres scénarios nécessitant un succès stable à chaque fois.
Q : Pourquoi l’ensemble de questions devrait-il couvrir en même temps les exemples à double sens des « à faire / à ne pas faire » ?
R : Les exemples bidirectionnels empêchent le modèle d’être entraîné à sur-déclencher un comportement (comme une recherche indiscriminée ou un appel indiscriminé d’un outil), ce qui entraîne des coûts plus élevés ou une expérience moins bonne.
Q : Quelle est la pratique minimale réalisable pour l’équipe afin de construire un système d’évaluation à partir de zéro ?
R : D’abord, la liste de régression manuelle et l’ordre de travail réel des défauts sont convertis en 20 à 50 tâches reproductibles, appariées avec des solutions de référence et des environnements stables, puis progressivement étendues au kit de régression et à la surveillance de la production en boucle fermée.