오픈 소스 음성 솔루션 비교: Fun-CosyVoice3 대 일반 TTS, Fun-ASR-nano 대 메인스트림 ASR
1. 요약 : 알리바바 통이 음성 팀(FunAudioLLM)은 두 가지 유형의 오디오 모델을 오픈 소스로 제공했습니다: 음성 합성용 Fun-CosyVoice3-0.5B-2512 (TTS)와 음성 인식용 Fun-ASR-Nano-2512 (ASR). 전자는 다국어 제로 샷...
Admin •
619
1. 요약 : 알리바바 통이 음성 팀(FunAudioLLM)은 두 가지 유형의 오디오 모델을 오픈 소스로 제공했습니다: 음성 합성용 Fun-CosyVoice3-0.5B-2512 (TTS)와 음성 인식용 Fun-ASR-Nano-2512 (ASR). 전자는 다국어 제로 샷...

1. 추상 GLM-TTS는 산업용 음성 생성을 위한 오픈소스 TTS 시스템으로, 음성 샘플의 음색 복제를 단 3초 만에 지원하고 감정 표현을 제어할 수 있습니다. 아키텍처는 2단계 생성 과정을 채택하며, 문자 오류율(CER)과 감성 측면에서 오픈 소스 중 선도적인 수준...

1. 추상 적 Open-AutoGLM은 Zhipu AI용 오픈소스 모바일 폰 에이전트 프레임워크이며, 핵심 모델은 AutoGLM-Phone-9B입니다. 휴대폰 화면의 내용을 이해하고 실제 사용자 조작을 시뮬레이션하여 "인터페이스 이해, 지시사항 이해, 휴대폰 클릭"을 ...
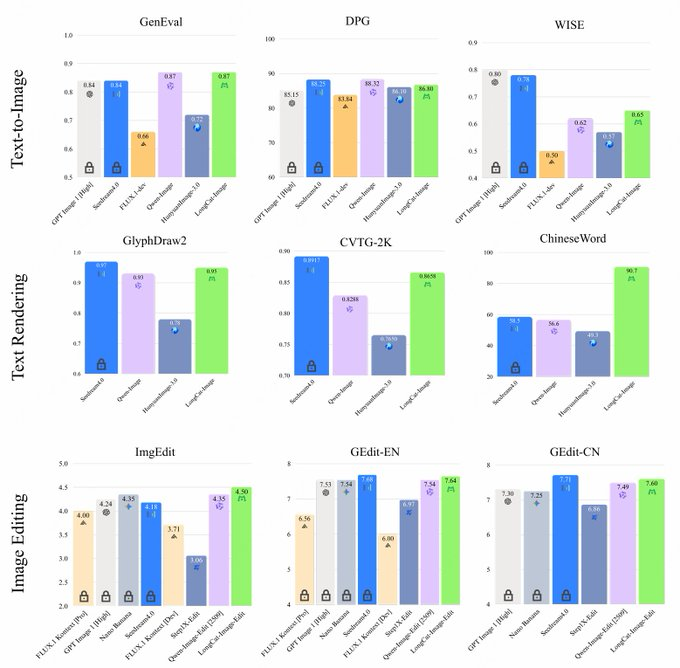
1. Abstract LongCat-Image는 Meituan의 LongCat 팀이 개발한 중국어와 영어 오픈소스 이중언어 이미지 생성 및 편집 모델로, 약 6B 매개변수를 가진 하이브리드 DiT 아키텍처를 사용하며, 많은 공개 벤치마크에서 20B 수준의 오픈 소스 모...
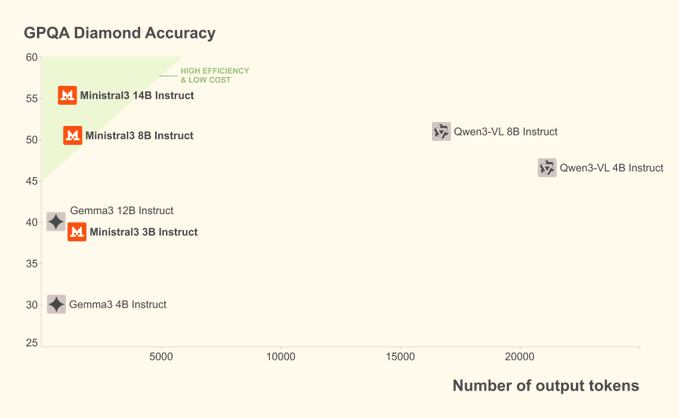
1. Abstract Mistral 3는 Mistral AI가 출시한 새로운 세대의 오픈 소스 모델 계열로, 드문 전문가 아키텍처를 가진 Mistral Large 3와 로컬 및 엣지 시나리오용 Ministral 3 시리즈(3B/8B/14B)를 포함합니다. 모든 가중치는...
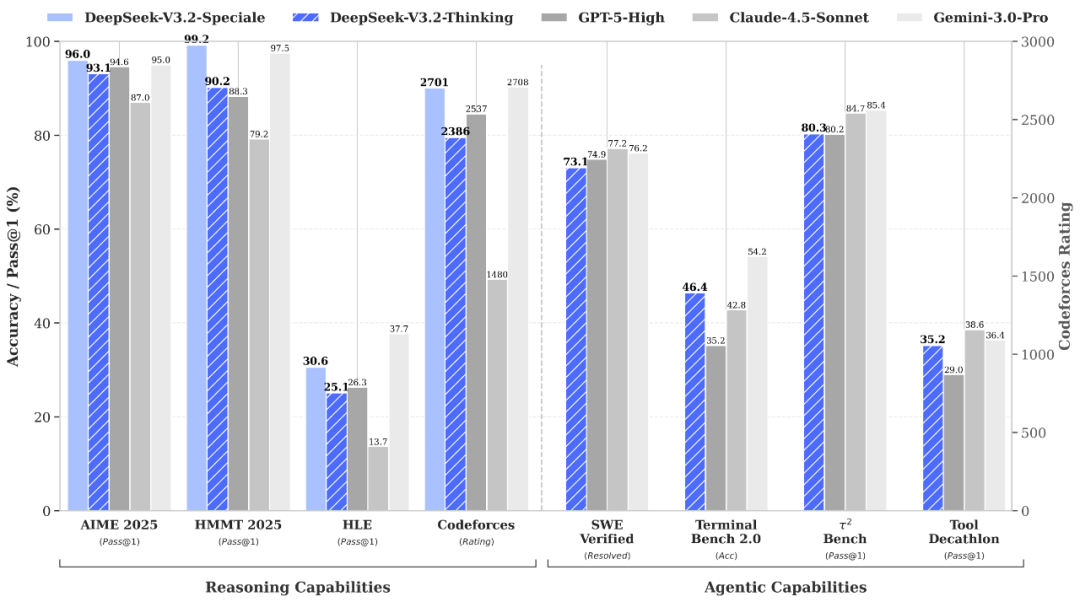
1. Abstract DeepSeek-V3.2는 V3.2-Exp를 기반으로 한 공식 출시 버전으로, 추론 효율성과 출력 길이 최적화에 중점을 두고, DSA 희소 주의 메커니즘을 활용해 장기 컨텍스트 성능을 향상시킵니다. DeepSeek-V3.2-Speciale는 극도의...