Qwen-Image-Layered Open Source Interpretation: 그래프를 편집 가능한 RGBA 레이어로 분해하는 '네이티브 레이어링' 모델입니다
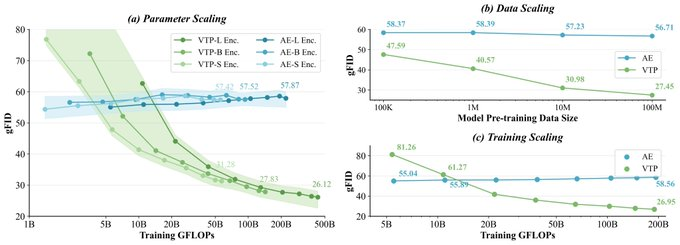
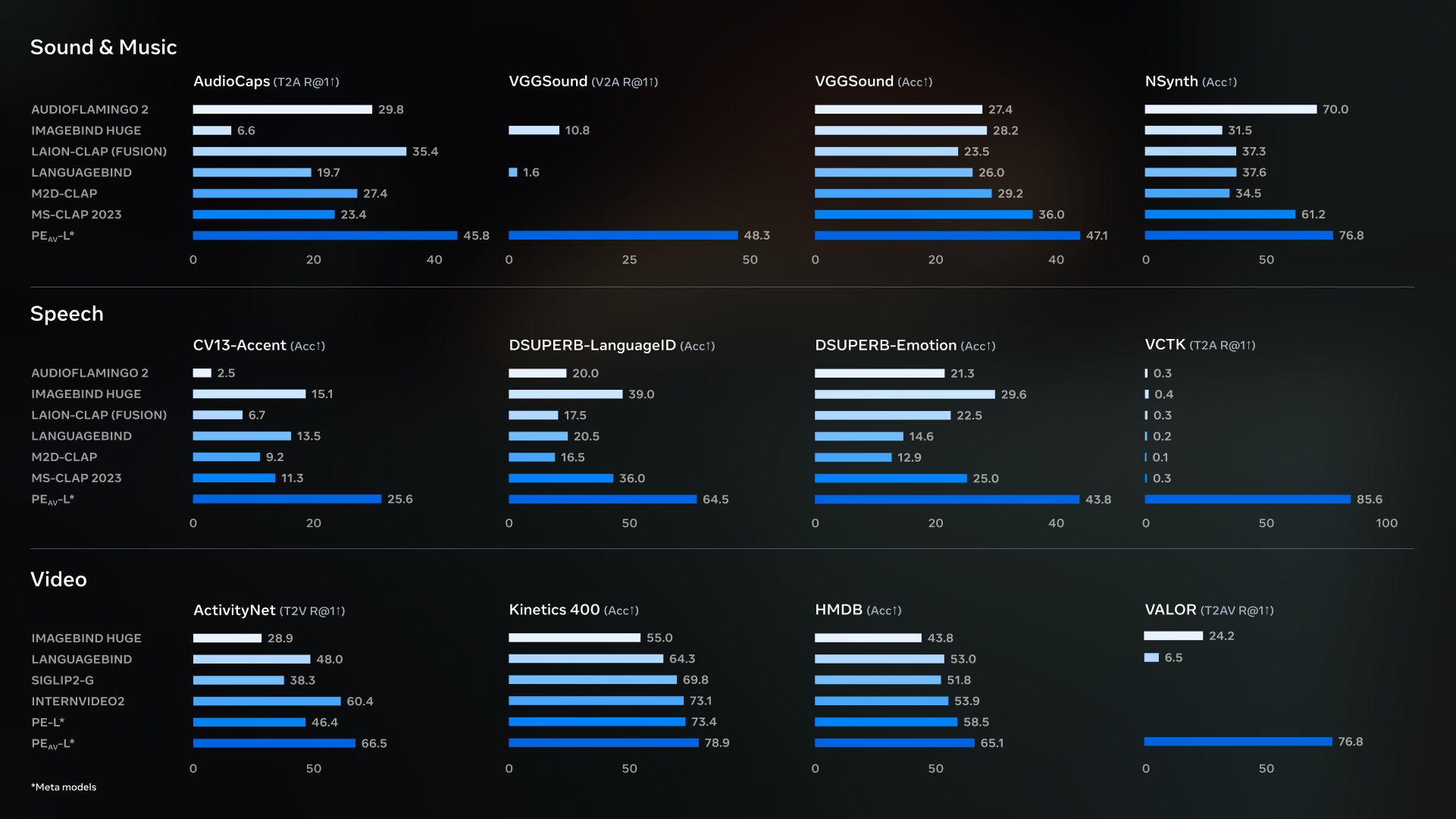
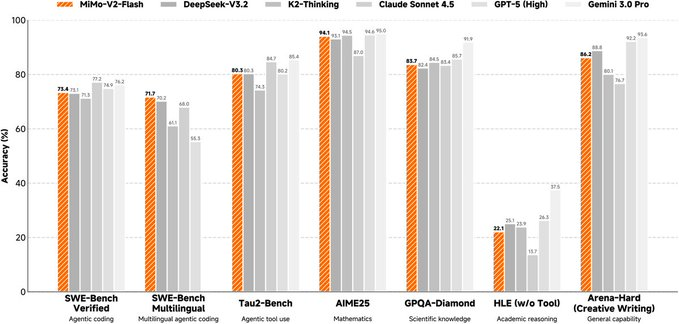
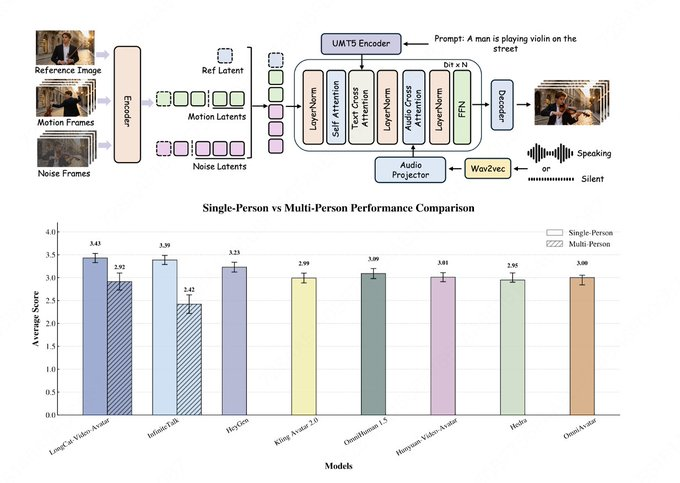
1. 초록 Qwen-Image-Layered는 Qwen 팀이 개발한 오픈 소스 이미지 '레이어링' 모델로, 일반 RGB 이미지를 물리적으로 분리된 여러 RGBA 레이어를 출력합니다. 일반적인 '동일한 평면 맵 편집'과 달리, 본체와 구조를 독립된 레이어로 분해하여 무거...
Admin •
303