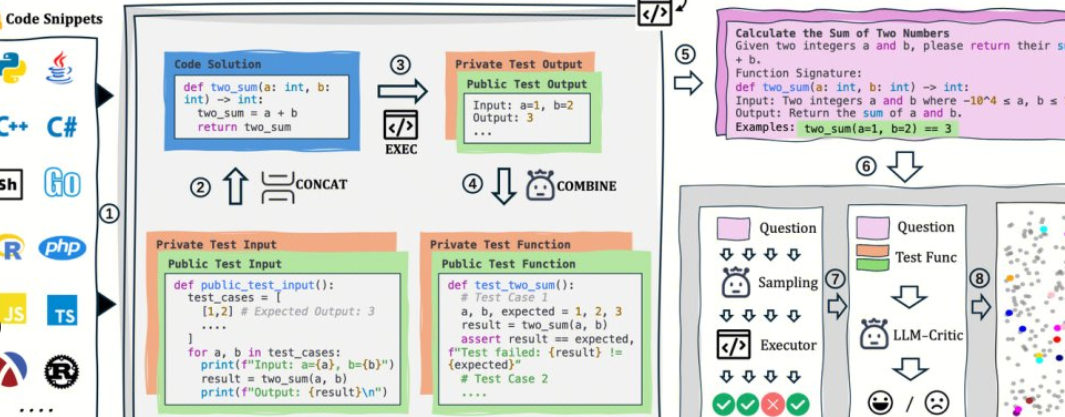
AutoCodeBench는 Tencent의 Hunyuan 팀에 의해 오픈 소스이며 그 핵심은 "LLM 생성 + 다국어 샌드박스 검증"의 자동화된 워크플로입니다. 이 프로젝트는 또한 AutoCodeGen(데이터 합성), AutoCodeBench(세 가지 벤치마크 세트, Full/Lite/Complete) 및 MultiLanguageSandbox(30+ 언어 샌드박스)를 오픈 소스로 제공하여 Base 및 Chat 모델의 다국어 코딩 기능을 평가하고 새로운 벤치마크의 자체 생성을 지원합니다.
1. 프로젝트 개요 및 가치
1. 수동 주석 없음: LLM을 사용하여 질문과 참조 답변을 합성하고 샌드박스를 통해 검증 가능한 표준 출력이 자동으로 생성됩니다.
2. 다국어와 어려움: 20개의 프로그래밍 언어와 3,920개의 실제 문제를 다루며 난이도 계층화는 실제 개발에 더 가깝습니다.
3. 평가와 데이터는 동일한 소스입니다: 동일한 프로세스로 데이터를 생성할 수 있을 뿐만 아니라 평가를 재생할 수 있어 재현성과 수평적 비교에 편리합니다.
2. 오픈 소스 주소
1. 프로젝트 홈페이지: https://autocodebench.github.io
2. 종이: https://arxiv.org/abs/2508.09101
3. 코드베이스: https://github.com/Tencent-Hunyuan/AutoCodeBenchmark
4. 데이터 세트: https://huggingface.co/datasets/tencent/AutoCodeBenchmark
3. 데이터 및 벤치마크 구성
1. 전체: 3,920개 언어를 다루는 20개의 질문으로 난이도와 다양성을 강조합니다.
2. 라이트: 1,586개의 질문, 교차 모델 "해결 가능성"으로 선별되어 빠른 비교에 더 도움이 됩니다.
3. 완료: 1,000문항, 3샷 설정, 베이스 모델에 대한 코드 완성 평가.
4. 언어 및 난이도 : 언어에 따른 균형 잡힌 샘플링, 난이도는 폭과 강도를 모두 고려하여 쉬움/중간/어려움으로 나뉩니다.
4. 평가 패러다임 및 지표
1. 통합 지침: 명령과 예제를 실행하지 않고 단일 코드 블록의 출력이 필요합니다.
2. 샌드박스 검증: 생성된 코드를 주제별로 컴파일/실행하고 pass@1와 같은 객관적인 지표를 계산합니다.
3. 2줄 평가: 채팅 생성과 베이스 완성을 동시에 다루어 "대화 모델만 테스트"하는 편견을 줄입니다.
5. 빠르게 시작하기(5단계)
1. 출력 준비: 모델을 사용하여 autocodebench.jsonl에서 질문별로 질문에 대한 코드를 생성하고 model_output.jsonl로 저장합니다.
2. 이미지를 가져옵니다: docker pull hunyuansandbox/multi-language-sandbox:v1.
3. docker run -d --name sandbox -p 8080:8080 hunyuansandbox/multi-language-sandbox:v1 서비스를 시작합니다.
4. 상태 점검: 최소 샘플을 POST /submit에 제출하여 컴파일/실행이 정상인지 확인합니다.
5. 계산 지표: 웨어하우스 스크립트를 사용하여 샌드박스를 일괄적으로 호출하고, 실행 결과를 생성하고, pass@1 계산합니다.
6. 일반적인 응용 프로그램 및 적용 가능한 그룹
1. 모델 팀: 언어 간 회귀 및 버전 비교, 컴파일 실패/경계 사용 사례 찾기.
2. 과학적 연구 평가: 저렴한 비용으로 고품질 다국어 벤치마크를 구축하여 재현성을 향상시킵니다.
3. 기업 내부 테스트: Lite/Complete를 사용하여 그레이스케일 평가를 수행하고 안정성 및 롱테일 질문을 관찰합니다.
7. 실용적인 제안
1. 먼저 라이트 다음 전체: 먼저 빠르게 선별한 다음 포괄적인 회귀 및 보고를 수행합니다.
2. 동시성 및 할당량: 샌드박스 컴파일/실행은 병목 현상이므로 대기열을 예약하고 분산 방식으로 구현하는 것이 좋습니다.
3. 관찰 가능성: 유형(컴파일/실행/경계/시간 제한), 대상 최적화 프롬프트 및 하이퍼파라미터별 기록 실패.
4. RAG와 협력: 긴 질문과 교차 파일 작업이 검색 향상과 결합되어 안정성을 향상시킵니다.
8. 제한 사항 및 위험 경고
1. 환경 일관성: 미러링 및 종속성은 통과율에 영향을 미치며 버전 및 임의 시드를 잠가야 합니다.
2. 데이터 규정 준수: 주제와 코드에 외부 데이터베이스가 포함된 경우 격리 및 감사를 잘 수행해야 합니다.
3. 외삽된 경계: 벤치마크 점수는 생산 가용성과 같지 않으며 실제 비즈니스 샘플 A/B가 여전히 필요합니다.
9. 자주 묻는 질문
1. 정말 "완전 자동 및 수동 주석 제로"입니까?
이 프로세스는 LLM 생성 및 샌드박스 검증을 중심으로 하며 주제별로 수동 주석에 의존하지 않습니다. 품질을 확인하기 위해 주요 샘플의 수동 샘플링을 권장합니다.
2. 어떤 언어가 지원되며 Python에 편향되어 있습니까?
샌드박스는 30+ 언어를 지원하고 데이터 밸런싱을 통해 20개의 프로그래밍 언어를 다루므로 "Python 전용" 편향을 크게 줄입니다.
3. Chat과 Base를 동시에 평가하는 방법은 무엇입니까?
Chat은 통합 시스템 프롬프트에서 직접 코드를 생성합니다. Base는 Complete의 3샷 완료 설정을 사용하여 평가 프로토콜을 일관되게 유지합니다.
4. 동일한 워크플로를 사용하여 사용자 지정 기준선을 생성할 수 있습니까?
그래. AutoCodeGen은 동일한 검증 및 채점 프로세스를 사용하여 샌드박스에서 새 문제와 테스트 세트를 자동으로 합성합니다.



