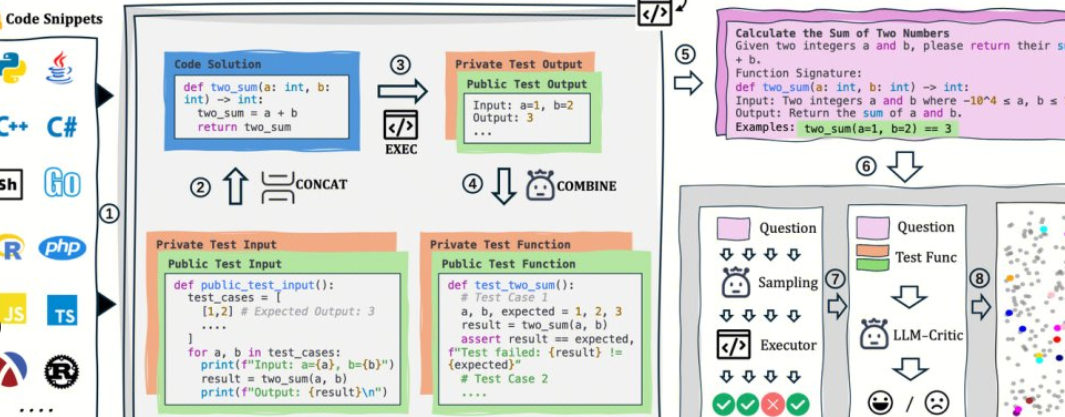
AutoCodeBench 由腾讯混元团队开源,核心是“LLM 生成 + 多语言沙箱验证”的自动化工作流。项目同时开源 AutoCodeGen(数据合成)、AutoCodeBench(Full / Lite / Complete 三套基准)与 MultiLanguageSandbox(30+ 语言沙箱),用于评测 Base 与 Chat 两类模型的多语种编码能力,并支持自行生成新基准。
一、项目概览与价值
1、无需人工标注:以 LLM 合成题面与参考答案,通过沙箱自动生成可验证的标准输出。
2、多语种与高难度:覆盖 20 种编程语言与 3,920 道实用题,难度分层更贴近真实开发。
3、评测与数据同源:同一套流程既能生成数据,也能回放评测,便于可复现与横向对比。
二、开源地址
1、项目主页:https://autocodebench.github.io
2、论文:https://arxiv.org/abs/2508.09101
3、代码库:https://github.com/Tencent-Hunyuan/AutoCodeBenchmark
4、数据集:https://huggingface.co/datasets/tencent/AutoCodeBenchmark
三、数据与基准构成
1、Full:3,920 题,覆盖 20 种语言,强调难度与多样性。
2、Lite:1,586 题,经跨模型“可解性”筛选,更利于快速比较。
3、Complete:1,000 题,3-shot 设置,面向 Base 模型的代码补全评测。
4、语言与难度:按语言均衡采样,难度分为 easy / medium / hard,兼顾广度与强度。
四、评测范式与指标
1、统一指令:要求输出单一代码块,不附带运行命令与样例。
2、沙箱核验:对生成代码逐题编译/运行,计算 pass@1 等客观指标。
3、双线评测:同时覆盖 Chat 生成与 Base 补全,减少“只测对话模型”的偏差。
五、快速上手(五步)
1、准备输出:用你的模型对 autocodebench.jsonl 的 question 逐题生成代码,保存为 model_output.jsonl。
2、拉取镜像:docker pull hunyuansandbox/multi-language-sandbox:v1。
3、启动服务:docker run -d --name sandbox -p 8080:8080 hunyuansandbox/multi-language-sandbox:v1。
4、健康检查:向 POST /submit 提交最小样例,确认编译/执行正常。
5、计算指标:使用仓库脚本批量调用沙箱,生成执行结果并统计 pass@1。
六、典型应用与适用人群
1、模型团队:跨语言回归与版本对比,定位编译失败/边界用例。
2、科研评测:低成本构建高质量多语种基准,提升可复现性。
3、企业内测:以 Lite/Complete 做灰度评测,观察稳定性与长尾题。
七、实践建议
1、先 Lite 后 Full:先快速筛选,再做全面回归与报告。
2、并发与配额:沙箱编译/运行是瓶颈,建议队列调度与分布式执行。
3、可观测性:分类型记录失败(编译/运行/边界/时限),针对性优化提示与超参。
4、配合 RAG:长题面与跨文件任务搭配检索增强更稳。
八、局限与风险提示
1、环境一致性:镜像与依赖微差会影响通过率,需锁定版本与随机种子。
2、数据合规:题面与代码涉及外部库时,要做好隔离与审计。
3、外推边界:基准分数不等于生产可用性,仍需真实业务样本 A/B。
九、常见问题
1、是否真正“全自动、零人工标注”?
流程以 LLM 生成与沙箱核验为核心,不依赖逐题人工标注;关键样本建议人工抽检以把关质量。
2、支持哪些语言,是否偏科 Python?
沙箱支持 30+ 语言,数据均衡覆盖 20 种编程语言,显著弱化“只测 Python”的偏差。
3、如何同时评测 Chat 与 Base?
Chat 直接按统一系统提示生成代码;Base 采用 Complete 的 3-shot 补全设置,保持评测协议一致。
4、能否用同一工作流生成自定义基准?
可以。通过 AutoCodeGen 在沙箱内自动合成新题与测试集,并沿用同一套核验与计分流程。



