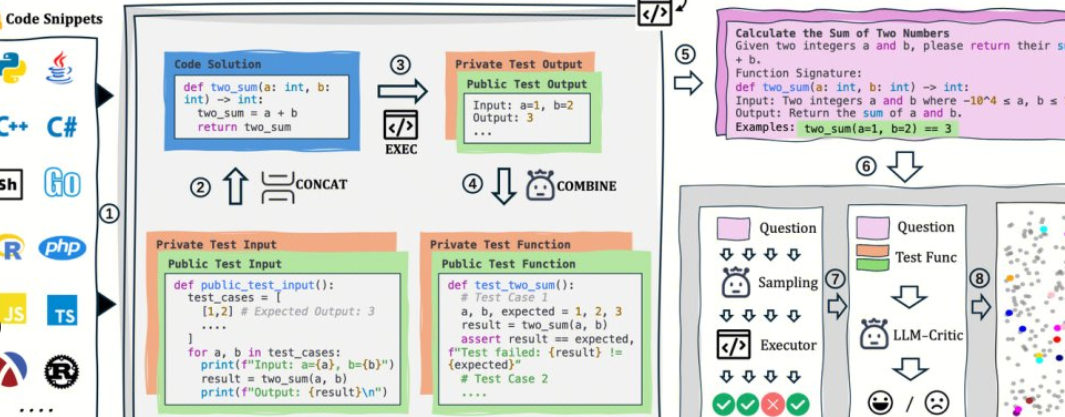
AutoCodeBench est open-source par l’équipe Hunyuan de Tencent, et son cœur est un flux de travail automatisé de « génération de LLM + validation de bac à sable multilingue ». Le projet utilise également en open source AutoCodeGen (synthèse de données), AutoCodeBench (trois ensembles de benchmarks, Full / Lite / Complete) et MultiLanguageSandbox (30+ bacs à sable linguistiques) pour évaluer les capacités de codage multilingue des modèles Base et Chat, et prendre en charge l’auto-génération de nouveaux benchmarks.
1. Vue d’ensemble et valeur du projet
1. Pas d’annotation manuelle : LLM est utilisé pour synthétiser les questions et référencer les réponses, et des sorties standard vérifiables sont automatiquement générées via le bac à sable.
2. Multilingue et difficile : Couvrant 20 langages de programmation et 3 920 problèmes pratiques, la superposition de la difficulté est plus proche du développement réel.
3. L’évaluation et les données sont la même source : le même processus peut non seulement générer des données, mais aussi lire l’évaluation, ce qui est pratique pour la reproductibilité et la comparaison horizontale.
2. Adresse open source
1. Page d’accueil du projet : https://autocodebench.github.io
2. Papier : https://arxiv.org/abs/2508.09101
3. Codebase : https://github.com/Tencent-Hunyuan/AutoCodeBenchmark
3. Composition des données et des points de référence
1. Complet : 3 920 questions, couvrant 20 langues, mettant l’accent sur la difficulté et la diversité.
2. Lite : 1 586 questions, filtrées par la « solvabilité » inter-modèles, ce qui est plus propice à une comparaison rapide.
3. Complet : 1 000 questions, réglage à 3 coups, évaluation de la complétion du code pour le modèle de base.
4. Langue et difficulté : Échantillonnage équilibré en fonction de la langue, la difficulté est divisée en facile/moyen/difficile, en tenant compte à la fois de l’ampleur et de l’intensité.
4. Paradigme et indicateurs d’évaluation
1. Instructions unifiées : nécessitent la sortie d’un seul bloc de code, sans exécuter de commandes ni d’exemples.
2. Vérification du bac à sable : compilez/exécutez le code généré sujet par sujet, calculez des indicateurs objectifs tels que pass@1.
3. Évaluation en deux lignes : Couvre simultanément la génération de chat et l’achèvement de la base pour réduire le biais de « tester uniquement le modèle de dialogue ».
5. Démarrez rapidement (5 étapes)
1. Préparez le résultat : utilisez votre modèle pour générer du code pour les questions dans autocodebench.jsonl question par question et enregistrez-le sous model_output.jsonl.
2. Tirez l’image : docker pull hunyuansandbox/multi-language-sandbox :v1.
3. Démarrez le service : docker run -d --name sandbox -p 8080:8080 hunyuansandbox/multi-language-sandbox :v1.
4. Vérification de l’état : soumettez l’échantillon minimum à POST/submit pour confirmer que la compilation/l’exécution est normale.
5. Métriques de calcul : utilisez des scripts d’entrepôt pour appeler les bacs à sable par lots, générer des résultats d’exécution et compter les pass@1.
6. Applications typiques et groupes applicables
1. Équipe modèle : régression inter-langage et comparaison de versions, localisation des cas d’échec de compilation/d’utilisation limites.
2. Évaluation de la recherche scientifique : Construisez des références multilingues de haute qualité à faible coût pour améliorer la reproductibilité.
3. Tests internes à l’entreprise : utilisez Lite/Complete pour effectuer une évaluation des niveaux de gris, observer la stabilité et les questions à longue traîne.
7. Suggestions pratiques
1. Lite d’abord, puis Full : Filtrez rapidement d’abord, puis effectuez une régression et un rapport complets.
2. Simultanéité et quotas : la compilation/l’exécution du bac à sable est un goulot d’étranglement, et il est recommandé de planifier les files d’attente et de les mettre en œuvre de manière distribuée.
3. Observabilité : Échec de l’enregistrement par type (compilation/exécution/limite/limite de temps), invites d’optimisation ciblées et hyperparamètres.
4. Coopérez avec le RAG : Les questions longues et les tâches inter-fichiers sont combinées à des améliorations de la recherche pour améliorer la stabilité.
8. Limitations et avertissements de risque
1. Cohérence environnementale : La mise en miroir et les dépendances affecteront le taux de réussite, et il est nécessaire de verrouiller la version et les graines aléatoires.
2. Conformité des données : Lorsque le sujet et le code impliquent des bases de données externes, il est nécessaire de faire un bon travail d’isolation et d’audit.
3. Limite extrapolée : Le score de référence n’est pas égal à la disponibilité de la production, et un échantillon d’entreprise réel A/B est toujours requis.
9. Foire aux questions
1. Est-ce vraiment « entièrement automatique et sans annotation manuelle » ?
Le processus est centré sur la génération de LLM et la vérification du bac à sable, et ne repose pas sur l’annotation manuelle sujet par sujet. Il est recommandé d’échantillonner manuellement les échantillons clés pour vérifier la qualité.
2. Quels langages sont pris en charge, et est-ce que cela penche vers Python ?
Le bac à sable prend en charge 30+ langages et couvre 20 langages de programmation avec équilibrage des données, réduisant considérablement le biais « Python uniquement ».
3. Comment évaluer Chat et Base en même temps ?
Le chat génère du code directement à partir d’invites système unifiées ; Base utilise les paramètres de complétion à 3 tirs de Complete pour maintenir la cohérence du protocole d’évaluation.
4. Puis-je utiliser le même flux de travail pour générer des références personnalisées ?
d’accord. AutoCodeGen synthétise automatiquement les nouvelles questions et les ensembles de tests dans un bac à sable en utilisant le même processus de vérification et de notation.



