I. 초록
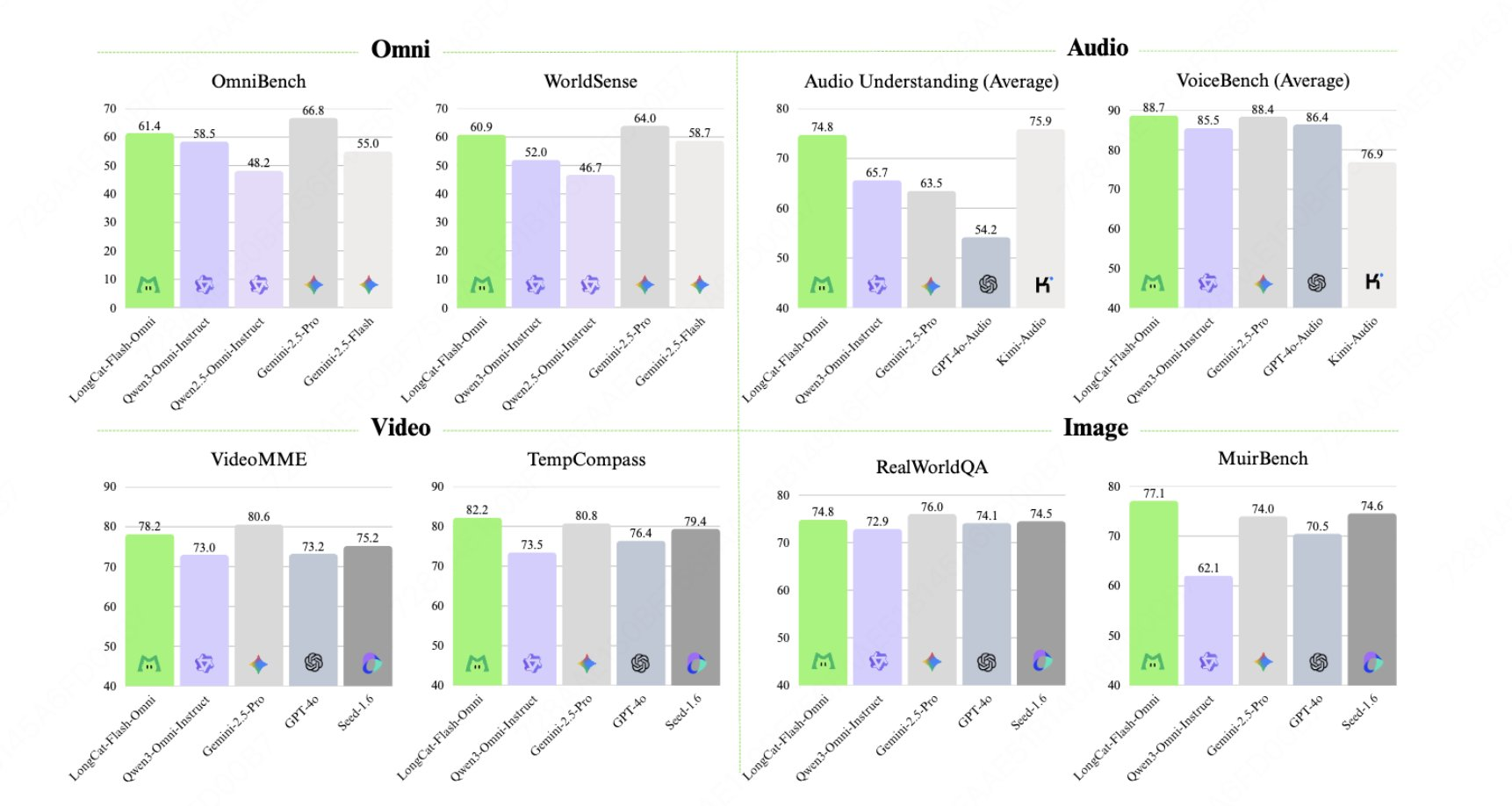
LongCat-Flash-Omni는 Meituan LongCat 팀이 개발한 오픈 소스 멀티모달(Omni-modal) 모델입니다. 텍스트, 이미지, 오디오 및 비디오에 대한 통합 모델링을 제공하여 LongCat-Flash의 ScMoE 아키텍처를 확장합니다. 약 560바이트의 매개변수와 27바이트의 활성화 함수를 가지며, 주로 밀리초 단위의 엔드투엔드 음성 대화, 128K 컨텍스트, 그리고 8분을 초과하는 실시간 오디오 및 비디오 상호작용 시나리오를 대상으로 합니다. 주요 기능으로는 초기 멀티모달 융합 학습, 분리된 모달 병렬 인프라, 그리고 고품질 음성 출력을 위한 LongCat-Audio-Codec이 있습니다.
II. 핵심 기능
- 풀모달 I/O: 입력은 텍스트, 이미지, 오디오 또는 비디오의 조합일 수 있으며, 출력은 텍스트 또는 음성으로, 실시간 에이전트에 맞춰 조정됩니다.
- 저지연 음성: 종단 간 음성 이해 및 합성 지연은 밀리초 수준으로 제어되므로 "중단된" 대화에 적합합니다.
- 긴 컨텍스트: 기본 128K로 긴 회의, 여러 턴의 음성 및 긴 영상 이해를 지원할 수 있습니다.
- ScMoE 아키텍처: 총 560B 매개변수 + 27B 활성화, 순수 텍스트 학습의 효율성에 근접한 계산 비용.
- 통합된 훈련 패러다임: 단일 모달리티에 대한 점수 손실을 피하기 위해 초기 단계에서 다중 모달 훈련을 통합하고 듣기, 보기, 말하기를 고려합니다.
III. 설치
1. GitHub 저장소를 복제합니다: git clone https://github.com/meituan-longcat/LongCat-Flash-Omni 그리고 디렉토리로 들어갑니다.
- 저장소에 제공된 환경 지침에 따라 종속성을 설치합니다. vLLM/SGLang/자체 개발 추론 서비스 중에서 선택할 수 있습니다. GPU가 필요하며, 비디오 메모리는 40GB 이상을 권장합니다. 여러 개의 GPU를 병렬로 사용할 수 있습니다.
3. Hugging Face에서 해당 가중치와 예를 가져옵니다: https://huggingface.co/meituan-longcat/LongCat-Flash-Omni; 음성 출력이 필요한 경우 LongCat-Audio-Codec을 동시에 설치합니다.
- 배포 후 REST/WebSocket 또는 공식 LongCat.AI 프런트엔드를 통해 텍스트/음성 테스트를 수행합니다.
IV. 일반적인 사용 사례
- 실시간 음성 지원: 발신 통화, 고객 서비스, 동반자 상호 작용에 사용되며, 낮은 지연 시간과 다중 턴 메모리가 필요합니다.
- AV 장면 이해: 회의/실시간 방송/과정을 위해 오디오 및 비디오 입력에서 핵심 요점을 추출하고 질문에 답합니다.
- 텍스트 및 오디오 설명: 스크린샷/사진/문서를 입력하여 오디오 설명이나 다국어 요약을 생성합니다.
- 에이전트 프로젝트 진입점: 비디오/음성 인식 결과를 추가 실행을 위해 툴체인이나 비즈니스 프로세스에 인계합니다.
V. 생태학과 경쟁자들
- 생태계: LongCat-Flash-Chat, LongCat-Flash-Thinking, LongCat-Audio-Codec을 보완하여 동일한 조직 내에서 통합 버전과 교육 패러다임을 사용할 수 있습니다.
- 경쟁 제품: Qwen 시리즈 Omni, InternLM/GLM 음성 멀티모달 버전, 다양한 커뮤니티의 MiniCPM-O/Omni 유사 모델의 성능은 비슷합니다. LongCat의 긴 컨텍스트 + 밀리초 수준 음성이 차별화 요소입니다.
- 애플리케이션 측면: 공식 웹사이트는 음성 링크 성능 검증을 용이하게 하기 위해 iOS/Android 앱과 웹 경험 사이트를 제공합니다.
VI. 제한 사항 및 주의사항
- 진정한 저지연성은 엔드투엔드 음성 링크와 고대역폭 추론 서비스에 의존하는데, 이는 로컬 또는 저사양 시스템에서는 완벽하게 재현할 수 없습니다.
- 비디오/긴 오디오 입력은 비디오 메모리와 컴퓨팅 파워를 크게 증가시키므로 시나리오에 맞게 트리밍하거나 분할하는 것이 필요합니다.
- 초기 멀티모달 융합은 일관성을 향상시킬 수 있지만, 데이터 형식과 주석 품질에 민감합니다. 2차 학습은 공식 예시를 엄격하게 준수해야 합니다.
- 오픈소스 저장소는 자주 업데이트되며, 배포 스크립트, 양자화 방법, 모델 샤딩은 최신 버전을 기반으로 해야 합니다.
VII. 프로젝트 주소
https://github.com/meituan-longcat/롱캣-플래시-옴니
VIII. 자주 묻는 질문
질문: LongCat-Flash-Omni에서 추론을 수행하려면 인터넷 연결이 필요합니까?
답변: 가중치는 오픈 소스이며 로컬 또는 비공개적으로 배포할 수 있지만 음성 합성 및 대규모 멀티모달 추론의 경우 공식 문서에 표시된 실시간 성능을 달성하려면 GPU 클러스터를 사용하는 것이 좋습니다.
질문: 128K 컨텍스트는 주로 어떤 시나리오에서 사용됩니까?
A: 장시간 회의, 긴 영상의 분할된 이해, 그리고 여러 차례에 걸친 음성 대화의 상태 유지에 적합합니다. 또한 다중 모드 RAG의 긴 문서 입력 창으로도 사용할 수 있습니다.
질문: 음성 입출력만 필요한 경우, 560B 전체를 로드해야 합니까?
A: 공식 아키텍처는 ScMoE이며, 실제 활성화 크기는 약 27바이트입니다. 리소스 소비를 줄이기 위해 양자화/프루닝 및 단일 작업 미세 조정과 결합할 수 있습니다. 자세한 내용은 저장소 배포 지침을 참조하십시오.


