一、摘要
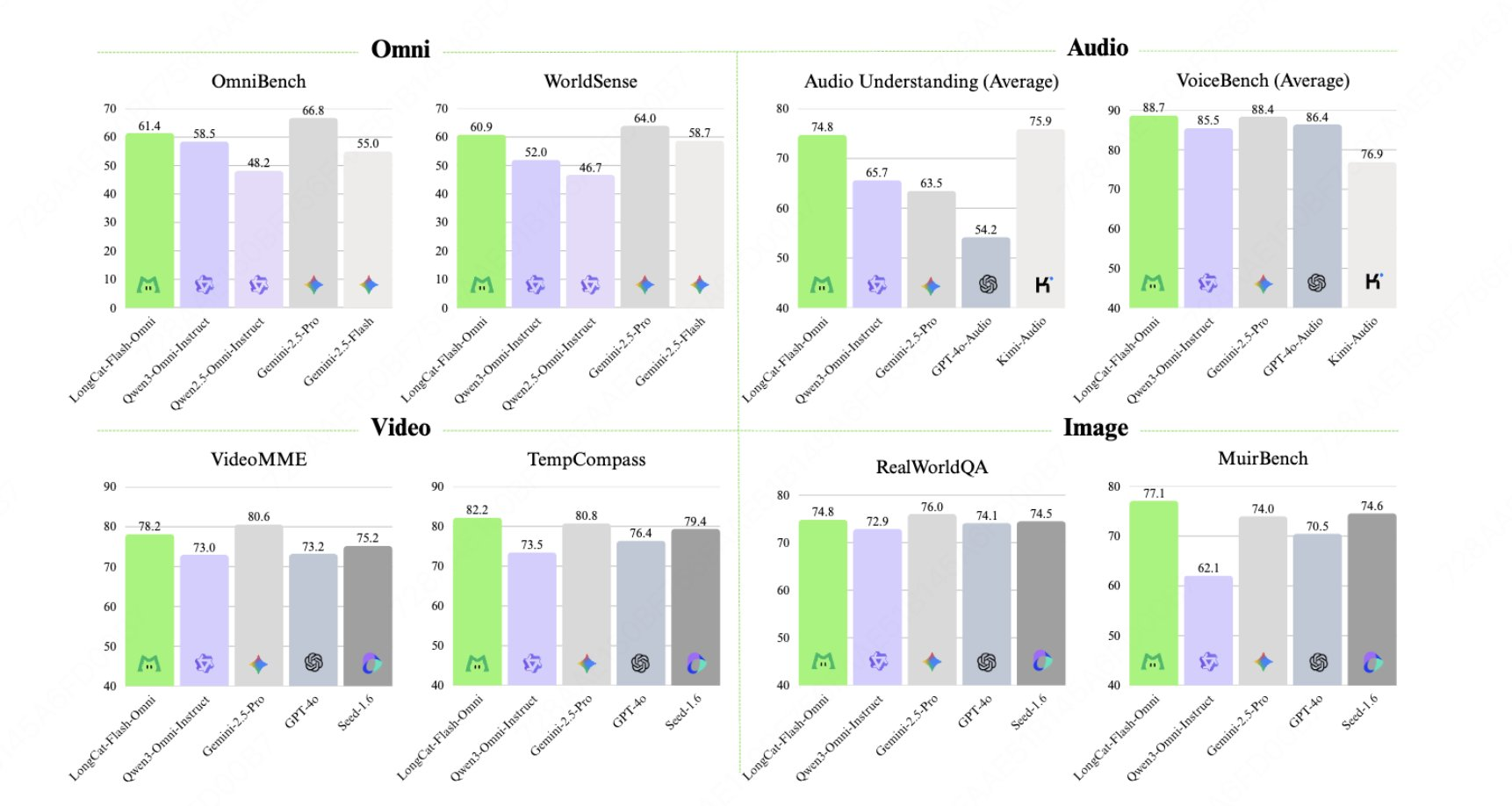
LongCat-Flash-Omni 是美团 LongCat 团队开源的全模态(Omni-modal)模型,在 LongCat-Flash 的 ScMoE 架构上扩展了文本、图像、音频、视频的统一建模,参数总量约 560B、激活约 27B,重点面向毫秒级端到端语音对话、128K 上下文及 8 分钟以上实时音视频交互场景。其特点是早期多模态融合训练、解耦的模态并行基础设施,以及配套的 LongCat-Audio-Codec,用于高质量语音输出。
二、核心特性
1、全模态 I/O:文本/图片/音频/视频任意组合输入,输出文本或语音,适配实时 Agent。
2、低时延语音:端到端语音理解与合成延迟控制在毫秒级,适合“打断式”对话。
3、长上下文:原生 128K,可支撑长会议、多轮语音及长视频理解。
4、ScMoE 架构:560B 总参 + 27B 激活,计算成本接近纯文本训练效率。
5、统一训练范式:早期融合多模态,避免单一模态掉点,兼顾听、看、说。
三、安装
1、GitHub 克隆仓库:git clone https://github.com/meituan-longcat/LongCat-Flash-Omni 并进入目录。
2、按仓库提供的环境说明安装依赖,可选 vLLM/SGLang/自研推理服务;需要 GPU 且显存建议≥40GB,多卡可并行。
3、从 Hugging Face 拉取对应权重与示例:https://huggingface.co/meituan-longcat/LongCat-Flash-Omni;若需语音输出,同步安装 LongCat-Audio-Codec。
4、部署后通过 REST/WebSocket 或官方 LongCat.AI 前端进行文本/语音测试。
四、典型用例
1、实时语音助手:外呼、客服、陪伴类交互,要求低时延与多轮记忆。
2、AV 场景理解:会议/直播/课程的音视频输入,做要点提取与问答。
3、图文+语音讲解:输入截图/照片/文档,生成语音讲解或多语种摘要。
4、Agent 工程入口:将视频/语音感知结果交给工具链或业务流程继续执行。
五、生态与竞品
1、生态:与 LongCat-Flash-Chat、LongCat-Flash-Thinking、LongCat-Audio-Codec 互补,可在同一组织下统一版本与训练范式。
2、竞品:同期开源的 Qwen 系列 Omni、InternLM/GLM 的语音多模态版本、多家社区的 MiniCPM-O/Omni 类模型在能力上可对比;LongCat 的长上下文 + 毫秒级语音是差异点。
3、应用端:官方给出了 iOS/Android App 与 Web 体验站点,方便验证语音链路性能。
六、局限与注意事项
1、真正的低时延依赖端到端语音链路与高带宽推理服务,本地或低配机器无法完全复现。
2、视频/长音频输入会显著拉高显存与算力,需按场景做裁剪或分段。
3、多模态早期融合虽能提升一致性,但对数据格式与标注质量敏感,二次训练要严格对齐官方示例。
4、开源仓库的更新频率较高,部署脚本、量化方式与模型分片需以最新版本为准。
七、项目地址
https://github.com/meituan-longcat/LongCat-Flash-Omni
八、常见问题
Q: LongCat-Flash-Omni 是否必须联网才能推理?
A: 权重开源,可本地/私有化部署,但语音合成与大批量多模态推理建议使用 GPU 集群以获得官方展示的实时性。
Q: 128K 上下文主要用在什么场景?
A: 适合长会议、长视频逐段理解、多轮语音对话状态保持,也可作为多模态 RAG 的长文档输入窗口。
Q: 若只要语音输入输出,需要加载完整 560B 吗?
A: 官方架构为 ScMoE,实际激活约 27B,可结合量化/裁剪与单任务微调减少资源消耗;具体以仓库部署说明为准。


