I. Résumé
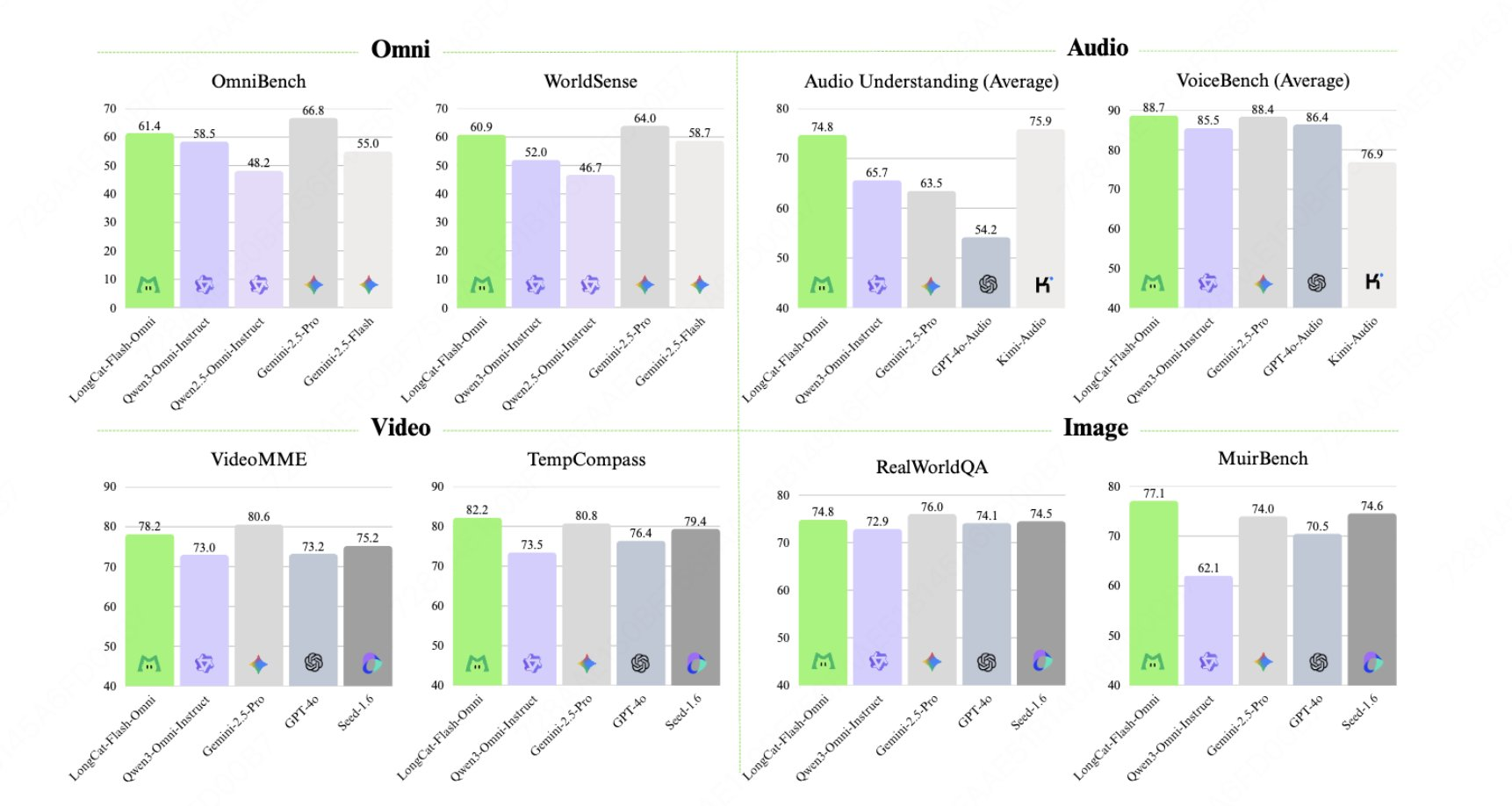
LongCat-Flash-Omni est un modèle multimodal (omnimodal) open source développé par l'équipe LongCat de Meituan. Il étend l'architecture ScMoE de LongCat-Flash en proposant une modélisation unifiée du texte, des images, de l'audio et de la vidéo. Il utilise environ 560 octets de paramètres et 27 octets d'activations, et cible principalement les dialogues vocaux de bout en bout à la milliseconde près, un contexte de 128 Ko et des scénarios d'interaction audio et vidéo en temps réel de plus de 8 minutes. Ses principales caractéristiques incluent un entraînement précoce à la fusion multimodale, une infrastructure parallèle modale découplée et le codec audio LongCat associé pour une restitution vocale de haute qualité.
II. Caractéristiques principales
- E/S entièrement modales : l'entrée peut être n'importe quelle combinaison de texte, d'image, d'audio ou de vidéo, et la sortie peut être du texte ou de la voix, s'adaptant ainsi aux agents en temps réel.
- Parole à faible latence : La latence de compréhension et de synthèse vocale de bout en bout est contrôlée au niveau de la milliseconde, ce qui convient aux dialogues « interrompus ».
- Contexte long : 128K natif, permettant de prendre en charge les réunions longues, les conversations vocales à plusieurs tours et la compréhension de longues vidéos.
- Architecture ScMoE : 560 milliards de paramètres au total + 27 milliards d'activations, avec un coût de calcul proche de l'efficacité de l'entraînement de texte pur.
- Paradigme de formation unifié : Intégrer la formation multimodale dans les premières étapes pour éviter de perdre des points dans une seule modalité et prendre en compte l'écoute, le visionnage et la parole.
III. Installation
1. Clonez le dépôt GitHub : git clone https://github.com/meituan-longcat/LongCat-Flash-Omni et entrez dans le répertoire.
- Installez les dépendances en suivant les instructions d'environnement fournies dans le dépôt. Vous pouvez choisir entre vLLM, SGLang et un service d'inférence développé par vos soins. Un GPU est requis et il est recommandé d'avoir au moins 40 Go de mémoire vidéo. Plusieurs GPU peuvent être utilisés en parallèle.
3. Extrayez les poids et exemples correspondants de Hugging Face : https://huggingface.co/meituan-longcat/LongCat-Flash-Omni; Si la sortie vocale est requise, installez simultanément LongCat-Audio-Codec.
- Après le déploiement, effectuez des tests texte/voix via REST/WebSocket ou l'interface officielle LongCat.AI.
IV. Cas d'utilisation typiques
- Assistant vocal en temps réel : appels sortants, service client et interactions de compagnie, nécessitant une faible latence et une mémoire multi-tours.
- Compréhension de la scène audiovisuelle : extraire les points clés et répondre aux questions à partir des entrées audio et vidéo pour les réunions/diffusions en direct/cours.
- Explication textuelle et audio : Saisissez des captures d’écran/photos/documents pour générer des explications audio ou des résumés multilingues.
- Point d'entrée du projet de l'agent : Transmet les résultats de perception vidéo/vocale à la chaîne d'outils ou au processus métier pour une exécution ultérieure.
V. Écologie et concurrents
- Écosystème : Complémentaire à LongCat-Flash-Chat, LongCat-Flash-Thinking et LongCat-Audio-Codec, permettant des versions unifiées et des paradigmes de formation au sein de la même organisation.
- Concurrents : Les capacités des modèles multimodaux vocaux de la série Qwen Omni, InternLM/GLM et des modèles de type MiniCPM-O/Omni issus de différentes communautés sont comparables ; le contexte long et la parole au niveau de la milliseconde de LongCat constituent le facteur de différenciation.
- Côté application : Le site Web officiel propose une application iOS/Android et un site Web pour faciliter la vérification des performances de la liaison vocale.
VI. Limitations et précautions
- Une véritable faible latence repose sur des liaisons vocales de bout en bout et des services d'inférence à large bande passante, qui ne peuvent pas être entièrement reproduits sur des machines locales ou de faible spécification.
- L'entrée vidéo/audio longue augmentera considérablement la mémoire vidéo et la puissance de calcul, il est donc nécessaire de découper ou de segmenter en fonction du scénario.
- Bien que la fusion multimodale précoce puisse améliorer la cohérence, elle est sensible au format des données et à la qualité des annotations. L'entraînement secondaire doit être strictement conforme aux exemples officiels.
- Les dépôts open source sont fréquemment mis à jour, et les scripts de déploiement, les méthodes de quantification et le partitionnement des modèles doivent être basés sur la dernière version.
VII. Adresse du projet
https://github.com/meituan-longcat/LongCat-Flash-Omni
VIII. Foire aux questions
Q : LongCat-Flash-Omni nécessite-t-il une connexion Internet pour effectuer l'inférence ?
A : Les poids sont open source et peuvent être déployés localement ou en privé, mais pour la synthèse vocale et l'inférence multimodale à grande échelle, il est recommandé d'utiliser un cluster GPU pour atteindre les performances en temps réel indiquées dans la documentation officielle.
Q : Dans quels scénarios le contexte 128K est-il principalement utilisé ?
A : Adapté aux réunions longues, à la compréhension segmentée de vidéos longues et au maintien de l'état des dialogues vocaux à plusieurs tours de parole. Il peut également servir de fenêtre de saisie de documents longs pour les RAG multimodaux.
Q : Si seules l'entrée et la sortie vocales sont nécessaires, est-il nécessaire de charger la totalité du 560B ?
A : L'architecture officielle est ScMoE, avec une activation effective d'environ 27 octets. Elle peut être combinée avec la quantification/l'élagage et l'optimisation fine de tâches individuelles pour réduire la consommation de ressources ; veuillez consulter les instructions de déploiement du dépôt pour plus de détails.


