I. 要約
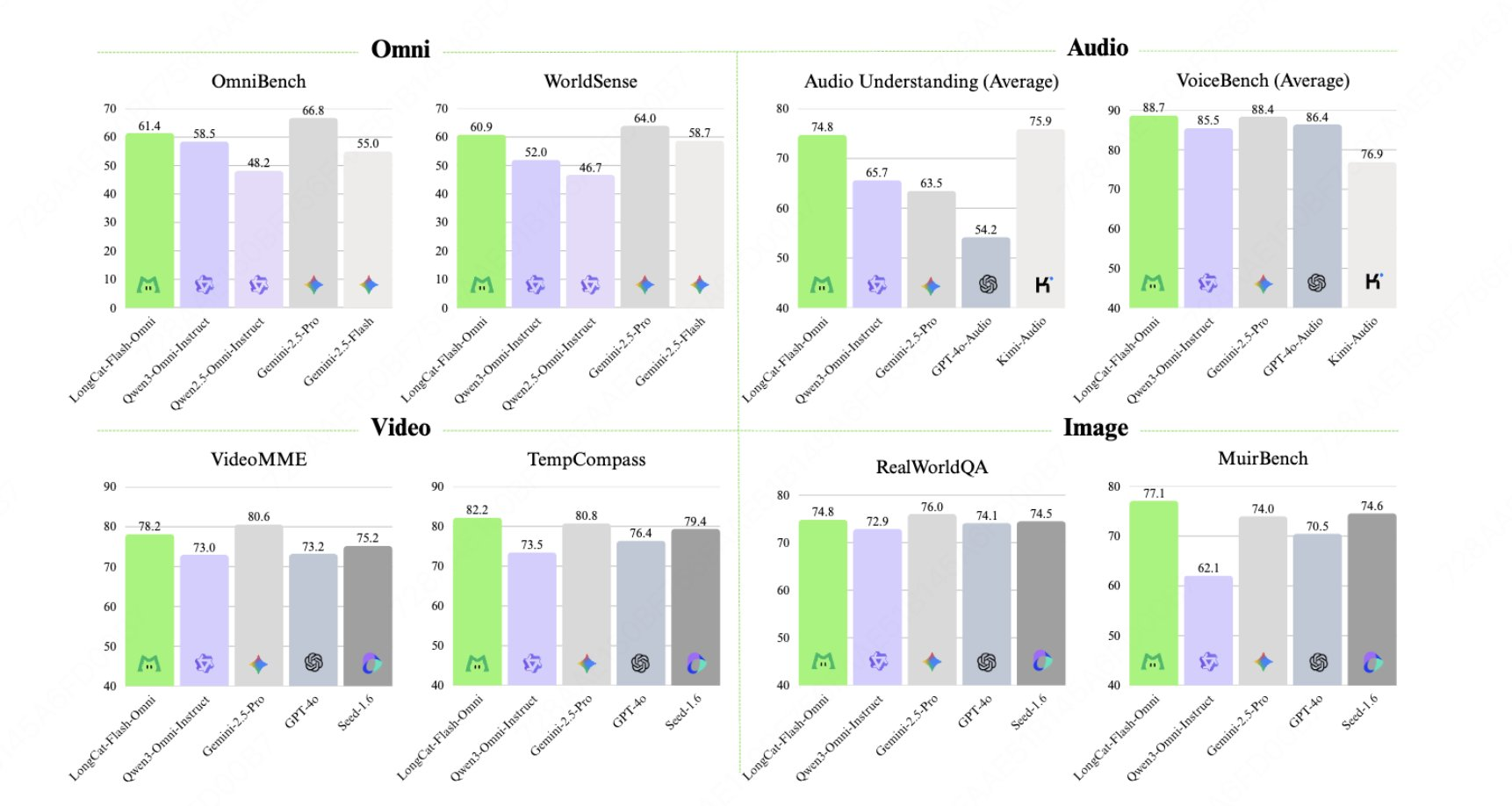
LongCat-Flash-Omniは、MeituanのLongCatチームによるオープンソースのマルチモーダル(オムニモーダル)モデルです。テキスト、画像、音声、動画の統合モデリングを提供することで、LongCat-FlashのScMoEアーキテクチャを拡張しています。約560バイトのパラメータと27バイトのアクティベーションを持ち、主にミリ秒レベルのエンドツーエンド音声対話、128Kコンテキスト、そして8分を超えるリアルタイム音声・動画インタラクションシナリオを対象としています。主な機能としては、早期マルチモーダル融合トレーニング、分離されたモーダル並列インフラストラクチャ、そして高品質な音声出力を実現するLongCat-Audio-Codecが挙げられます。
II. コア機能
- フルモーダル I/O: 入力はテキスト、画像、音声、ビデオの任意の組み合わせが可能で、出力はテキストまたは音声で、リアルタイムエージェントに適応します。
- 低遅延音声: エンドツーエンドの音声理解および合成の遅延はミリ秒レベルで制御され、「中断された」対話に適しています。
- 長いコンテキスト: ネイティブ 128K で、長時間の会議、複数ターンの音声、長時間のビデオ理解をサポートします。
- ScMoE アーキテクチャ: 合計 5600 億のパラメーター + 270 億のアクティベーション。計算コストは純粋なテキスト トレーニングの効率に近づきます。
- 統一されたトレーニングパラダイム: 単一の方法でポイントを失うことを避けるために、早い段階でマルチモーダルトレーニングを統合し、聞くこと、見ること、話すことを考慮に入れます。
III. インストール
1. GitHub リポジトリ:git clone https://github.com/meituan-longcat/LongCat-Flash-Omni をクローンし、ディレクトリに入ります。
- リポジトリに記載されている環境設定の指示に従って依存関係をインストールします。vLLM、SGLang、または独自開発の推論サービスから選択できます。GPUが必須で、ビデオメモリは40GB以上を推奨します。複数のGPUを並列で使用できます。
3. Hugging Face から対応する重みと例を取得します: https://huggingface.co/meituan-longcat/LongCat-Flash-Omni; 音声出力が必要な場合は、LongCat-Audio-Codec を同時にインストールします。
- デプロイ後、REST/WebSocket または公式の LongCat.AI フロントエンド経由でテキスト/音声テストを実施します。
IV. 典型的なユースケース
- リアルタイム音声アシスタント: 発信通話、顧客サービス、およびコンパニオンシップのインタラクションには、低遅延とマルチターンメモリが必要です。
- AV シーン理解: 会議/ライブ ブロードキャスト/コースのオーディオおよびビデオ入力から重要なポイントを抽出し、質問に答えます。
- テキストと音声による説明: スクリーンショット/写真/ドキュメントを入力して、音声による説明や多言語による要約を生成します。
- エージェント プロジェクトのエントリ ポイント: ビデオ/音声認識の結果をツールチェーンまたはビジネス プロセスに渡して、さらに実行します。
V. 生態と競合相手
- エコシステム: LongCat-Flash-Chat、LongCat-Flash-Thinking、および LongCat-Audio-Codec を補完し、同じ組織内での統一されたバージョンとトレーニング パラダイムを可能にします。
- 競合製品: Qwen シリーズの Omni、InterLM/GLM 音声マルチモーダル バージョン、およびさまざまなコミュニティの MiniCPM-O/Omni のようなモデルの機能は同等ですが、LongCat の長いコンテキスト + ミリ秒レベルの音声が差別化要因となっています。
- アプリケーション側: 公式サイトでは、音声リンクのパフォーマンス検証を容易にするために、iOS/Android アプリと Web 体験サイトを提供しています。
VI. 制限事項と注意事項
- 真の低遅延は、エンドツーエンドの音声リンクと高帯域幅の推論サービスに依存しており、ローカルマシンや低スペックのマシンでは完全に再現できません。
- ビデオ/長いオーディオを入力すると、ビデオメモリと計算能力が大幅に増加するため、シナリオに応じてトリミングまたはセグメント化する必要があります。
- 早期のマルチモーダル融合は一貫性を向上させる可能性がありますが、データ形式とアノテーションの品質に敏感です。二次トレーニングは公式サンプルに厳密に準拠する必要があります。
- オープンソース リポジトリは頻繁に更新されるため、デプロイメント スクリプト、量子化方法、モデル シャーディングは最新バージョンに基づく必要があります。
VII. プロジェクト住所
https://github.com/meituan-longcat/LongCat-Flash-Omni
VIII. よくある質問
Q: LongCat-Flash-Omni では推論を実行するためにインターネット接続が必要ですか?
A: 重みはオープンソースであり、ローカルまたはプライベートに展開できますが、音声合成や大規模なマルチモーダル推論の場合、公式ドキュメントに示されているリアルタイムパフォーマンスを実現するために、GPU クラスターを使用することをお勧めします。
Q: 128K コンテキストは主にどのようなシナリオで使用されますか?
A: 長時間の会議、長時間の動画のセグメント理解、複数ターンの音声対話の状態維持に適しています。また、マルチモーダルRAGの長文ドキュメント入力ウィンドウとしても使用できます。
Q: 音声入出力のみが必要な場合、560B をフルにロードする必要がありますか?
A: 公式アーキテクチャはScMoEで、実際のアクティベーションは約27バイトです。量子化/プルーニングとシングルタスクのファインチューニングを組み合わせることで、リソース消費を削減できます。詳細はリポジトリのデプロイ手順をご覧ください。


