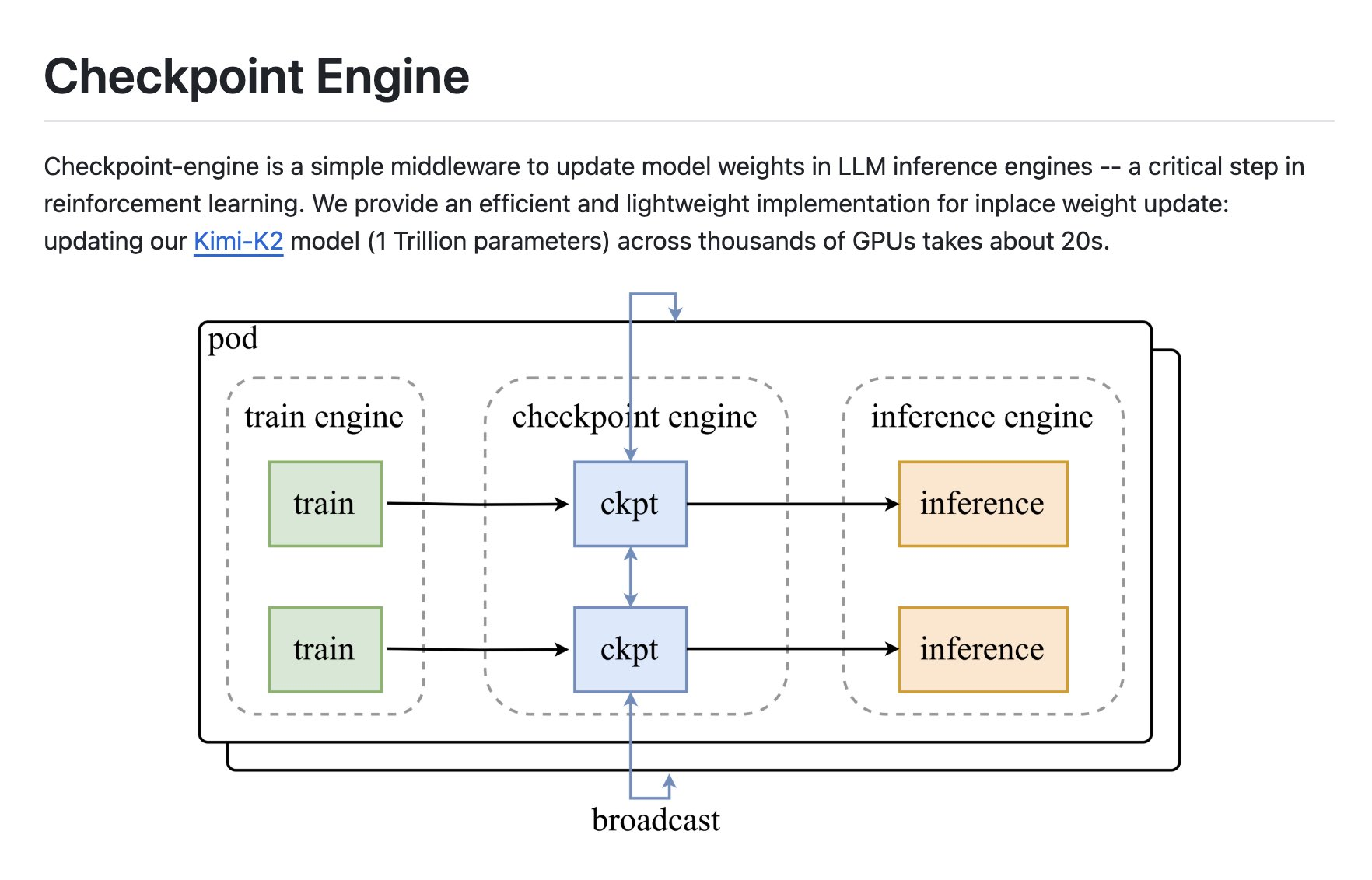
Pour les besoins de l’inférence RL et LLM à grande échelle, checkpoint-engine est un middleware léger qui implémente la « mise à jour du poids sur place », prend en charge la synchronisation de diffusion et le routage dynamique P2P, et combine l’optimisation de la communication et du chevauchement de copie. Sur des milliers de clusters GPU, les mises à jour du poids du modèle 1T peuvent être effectuées en 20 secondes environ, ce qui permet aux stratégies RL de boucler rapidement la boucle vers les services d’inférence en ligne.
1. Qu’est-ce que c’est et quels problèmes résout-il
1. La mise à jour en place pour raccourcir le moteur de point de contrôle en boucle fermée RL
termine la mise à jour du poids local pendant le processus d’inférence LLM pour éviter les redémarrages et les rechargements complets. Pour les boucles RL, checkpoint-engine permet de synchroniser rapidement les nouvelles politiques du côté de l’entraînement au côté de l’inférence en ligne, réduisant ainsi l’attente pour « build-feedback-update ».
2. Distribution bicanale : la diffusion et
le moteur de point de contrôle P2P prennent en charge à la fois les mises à jour synchrones de diffusion et la topologie dynamique P2P ; Il peut être commuté de manière flexible entre différentes salles informatiques et conditions de réseau afin de réduire le coût de la cohérence multicopie des grands modèles.
3. Léger et évolutif
Entant qu’intergiciel de contournement pour le moteur d’inférence, le moteur de point de contrôle se connecte aux services existants avec une intrusion minimale ; Fournit des mises à jour de pipeline pour les déploiements à grande échelle et est compatible avec les solutions de segmentation distribuée courantes.
2. Pourquoi est-ce plus rapide, points d’ingénierie
1. La communication et le chevauchement de copie
Dans lepipeline de mise à jour du moteur de point de contrôle, la communication et la copie de mémoire s’exécutent en parallèle pour réduire l’attente inactive ; La planification au niveau du flux permet d’utiliser les poids au fur et à mesure, ce qui augmente le débit global.
2. Les
itérations RL ne mettent généralement à jour que certains poids ou couches d’adaptation, et le moteur de point de contrôle prend en charge le découpage et le routage incrémentiel, réduisant ainsi le volume de gestion entre nœuds et compressant davantage le temps de mise à jour des modèles de niveau 1T.
3. Le moteur de point de contrôle destabilité et de restauration
a la version et la vérification par défaut, et maintient l’ancienne version réchauffée en mémoire en cas de défaillance, annulant rapidement et garantissant le SLA de l’inférence en ligne.
3. Comment l’utiliser, trois étapes
pour la mettre en œuvre 1. Scénarios d’accès
(1) Réglage fin de l’amélioration de l’apprentissage par renforcement : mises à jour fréquentes des politiques par petites étapes
(2) A/B en ligne : mises à jour en niveaux de gris pour des locataires ou un trafic spécifiques
(3) Charge mixte : le lot hors ligne et les requêtes en ligne coexistent
2. Processus de déploiement
(1) Charger le proxy du moteur de point de contrôle du côté de l’inférence
(2) Générer des blocs de poids et des index de métadonnées du côté de l’entraînement
(3) Sélectionner des itinéraires de diffusion ou P2P, activer la réplication qui se chevauche et surveiller la vérification
3. Gouvernance et observation
(1) Enregistrer la version, le hachage et la consommation de temps pour chaque changement de
poids (2) Définissez des seuils de simultanéité et de limitation pour protéger la latence du service
(3) Fixez des limites
4. Suggestions de comparaison et de sélection
1. VS moteur de point de contrôle de redémarrage/rechargement complet
traditionnel pour réduire les temps d’arrêt au deuxième niveau , ce qui convient mieux aux clusters à concurrence élevée et aux clusters à réplicas multiples.
2. VS serveur de paramètres purs
Leserveur de paramètres se concentre sur la synchronisation de gradient du côté de l’entraînement ; checkpoint-engine se concentre sur la distribution du poids côté inférence et la substitution in situ, ce qui est plus adapté à la boucle fermée hybride en ligne-hors ligne de RL.
3. Quand l’utiliser en premier
LorsqueRL est mis à jour fréquemment, qu’il comporte un grand nombre de modèles, qu’il a une grande taille de cluster et que « l’intégration sans interruption » est un indicateur concret, le moteur de point de contrôle est préféré.
Foire aux questions (Q&R)
Q : Comment le moteur de point de contrôle aide-t-il à accélérer les scènes RL ?
R : Il met à jour les poids en place du côté de l’inférence LLM, en téléchargeant de nouvelles stratégies d’apprentissage par renforcement presque « instantanément », réduisant considérablement le temps en boucle fermée entre la formation et le service.
Q : Comment choisir entre la diffusion et le P2P ?
R : Les réseaux à petite échelle ou homogènes préfèrent la radiodiffusion ; Choisissez le routage dynamique P2P entre les racks/centres de données et les topologies complexes, et combinez des copies qui se chevauchent pour obtenir un débit plus stable.
Q : Sur quelles conditions préalables le modèle 1T s’appuie-t-il pour une mise à jour de 20 secondes ?
R : S’appuyer sur l’incrément de morceaux, le chevauchement des copies de communication et le routage efficace ; L’échelle est plus évidente dans les grands clusters de milliers de GPU, ce qui dépend vraiment du réseau et de la stratégie de segmentation.
Q : Le moteur de point de contrôle est-il compatible avec les moteurs d’inférence existants ?
R : En tant que middleware léger, il peut accéder à la pile d’inférence distribuée principale sans modifier la logique métier. La restauration sécurisée et les niveaux de gris sont obtenues grâce à la gestion des versions et à la vérification.