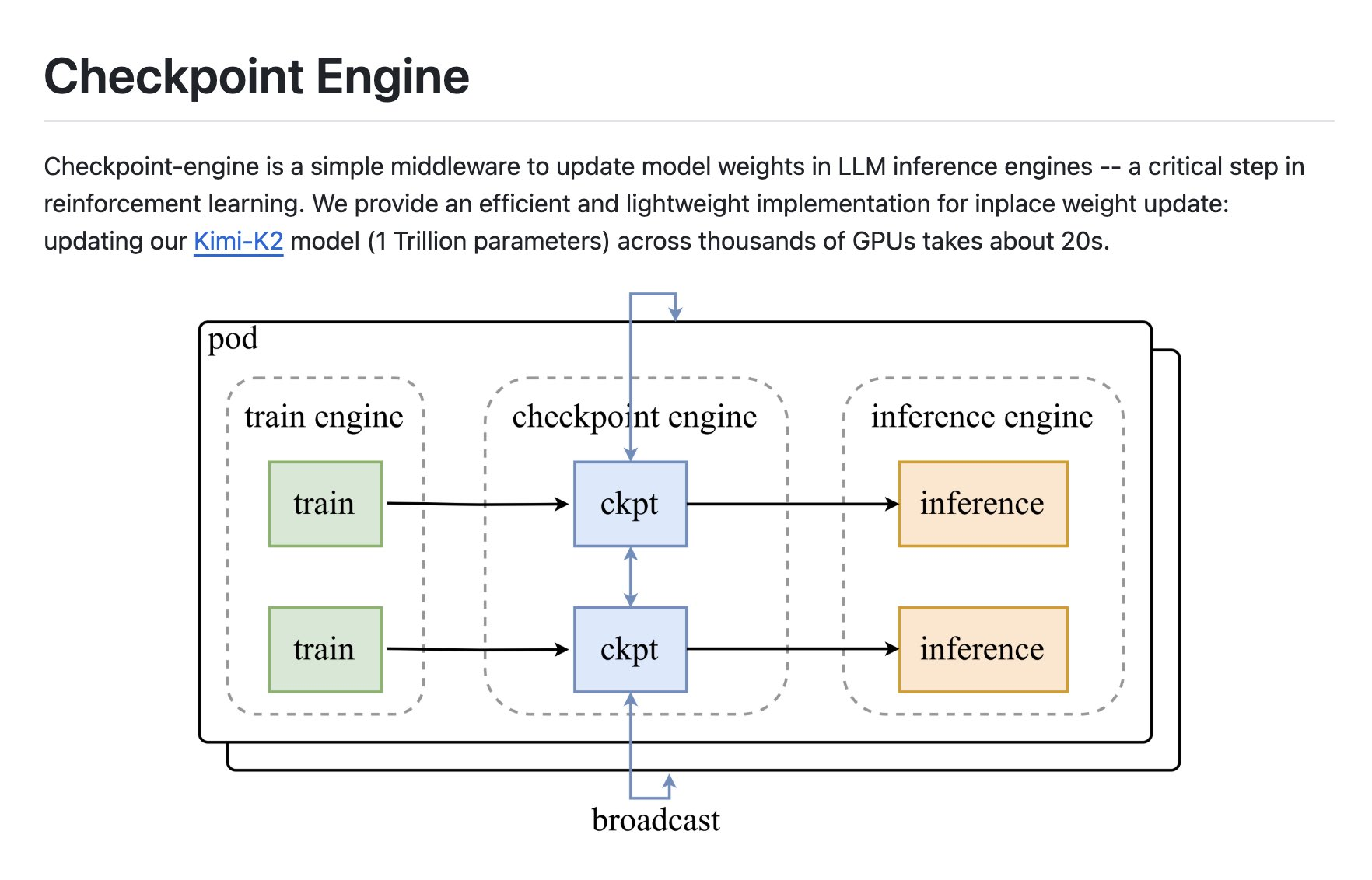
For the needs of RL and large-scale LLM inference, checkpoint-engine is a lightweight middleware that implements "in-place weight update", supports broadcast synchronization and P2P dynamic routing, and combines communication and copy overlap optimization. On thousands of GPU clusters, 1T model weight updates can be completed in about 20 seconds, helping RL policies quickly close the loop to online inference services.
1. What is it and what problems it solves
1. Update in place to shorten the RL closed-loop
checkpoint-engine completes the local weight update during the LLM inference process to avoid restarts and full reloads. For RL loops, checkpoint-engine allows new policies to be quickly synchronized from the training side to the online inference side, reducing the wait for "build-feedback-update".
2. Dual-channel distribution: broadcast and P2P
checkpoint-engine support both broadcast synchronous updates and P2P dynamic topology; It can be flexibly switched between different computer rooms and network conditions to reduce the cost of multi-copy consistency of large models.
3. Lightweight and scalable
Asa bypass middleware for the inference engine, checkpoint-engine connects to existing services with minimal intrusion; Provides pipeline updates for large-scale deployments and is compatible with mainstream distributed segmentation solutions.
2. Why is it faster, engineering points
1. Communication and copy overlap
In thecheckpoint-engine update pipeline, communication and memory copy run in parallel to reduce idle waiting; Stream-level scheduling allows weights to be used as they go, increasing overall throughput.
2. On-demand granularity and routing optimization
RL iterations usually only update some weights or adaptation layers, and checkpoint-engine supports chunking and incremental routing, reducing the volume of cross-node handling and further compressing the update time of 1T level models.
3. Stability and rollback
checkpoint-engine has version and verification by default, and keeps the old version warmed up in memory when it fails, rolling back quickly, and ensuring the SLA of online inference.
3. How to use it, three steps
to implement 1. Access scenarios
(1) RL enhancement fine-tuning: frequent policy updates in small steps
(2) Online A/B: grayscale updates for specific tenants or traffic
(3) Mixed load: offline batch and online requests coexist
2. Deployment process
(1) Load the checkpoint-engine proxy on the inference side
(2) Output weight blocks and metadata indexes on the training side
(3) Select broadcast or P2P routes, enable overlapping replication and monitor verification
3. Governance and observation
(1) Record version, hash, and time consumption for each weight change
(2) Set concurrency and throttling thresholds to protect service latency
(3) Make budget and frequency limits
4. Comparison and selection suggestions
1. VS traditional restart/full reload
checkpoint-engine to reduce the downtime to the second level , which is more suitable for high-concurrency and multi-replica clusters.
2. VS pure parameter server
Theparameter server focuses on gradient synchronization on the training side; checkpoint-engine focuses on inference-side weight distribution and in-situ substitution, which is more suitable for RL's online-offline hybrid closed loop.
3. When to use it first
WhenRL is updated frequently, has a large number of models, has a large cluster size, and "non-disruptive onboarding" is a hard indicator, the checkpoint-engine is preferred.
Frequently Asked Questions (Q&A)
Q: How does checkpoint-engine help speed up RL scenes?
A: It updates the in-place weights on the LLM inference side, uploading new RL strategies almost "instantly", significantly reducing the closed-loop time from training to service.
Q: How to choose between broadcast and P2P?
A: Small-scale or homogeneous networks prefer broadcasting; Choose P2P dynamic routing across racks/data centers, and complex topologies, and combine overlapping copies to obtain more stable throughput.
Q: What prerequisites does the 1T model rely on for a 20-second update?
A: Rely on chunk increment, communication-copy overlap and efficient routing; Scale is more evident in large clusters of thousands of GPUs, which really depends on the network and the segmentation strategy.
Q: Is checkpoint-engine compatible with existing inference engines?
A: As a lightweight middleware, it can access the mainstream distributed inference stack without changing the business logic. Secure rollback and grayscale are achieved through versioning and verification.