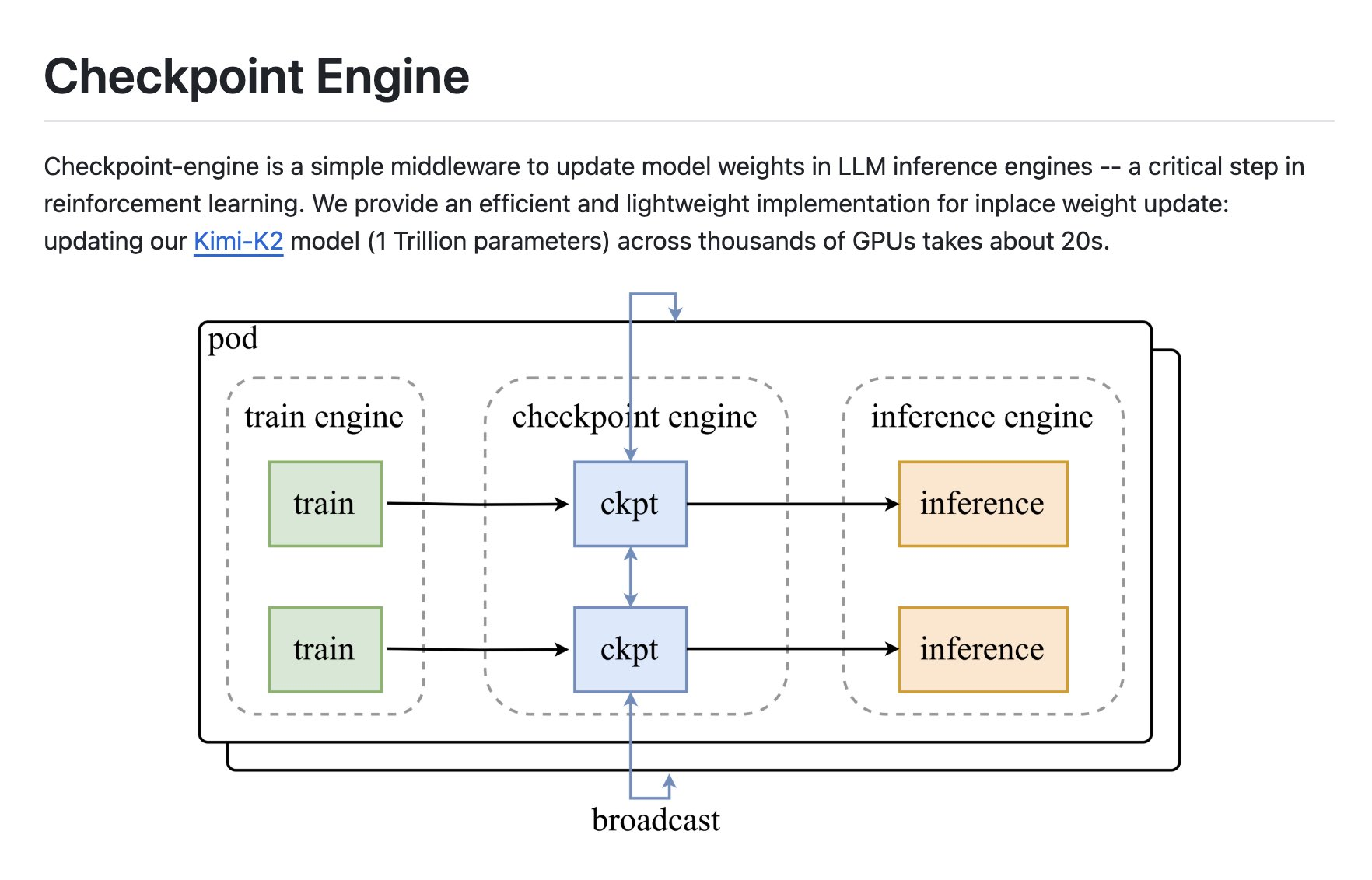
Für die Anforderungen von RL- und groß angelegten LLM-Inferenzen ist checkpoint-engine eine schlanke Middleware, die ein "In-Place-Weight-Update" implementiert, Broadcast-Synchronisation und dynamisches P2P-Routing unterstützt und die Optimierung von Kommunikation und Kopierüberlappung kombiniert. Auf Tausenden von GPU-Clustern können Aktualisierungen der 1T-Modellgewichtung in etwa 20 Sekunden abgeschlossen werden, was dazu beiträgt, dass RL-Richtlinien schnell den Kreis zu Online-Inferenzdiensten schließen.
1. Was ist das und welche Probleme werden dadurch gelöst
? 1. Update an Ort und Stelle zur Verkürzung der RL-Closed-Loop-Checkpoint-Engine
schließt die lokale Gewichtsaktualisierung während des LLM-Inferenzprozesses ab, um Neustarts und vollständige Neuladungen zu vermeiden. Für RL-Schleifen ermöglicht die checkpoint-engine die schnelle Synchronisierung neuer Richtlinien von der Trainingsseite zur Online-Inferenzseite, wodurch die Wartezeit auf "build-feedback-update" verkürzt wird.
2. Dual-Channel-Verteilung: Broadcast und P2P-Checkpoint-Engine
unterstützen sowohl synchrone Broadcast-Updates als auch dynamische P2P-Topologie; Es kann flexibel zwischen verschiedenen Computerräumen und Netzwerkbedingungen umgeschaltet werden, um die Kosten für die Konsistenz mehrerer Kopien bei großen Modellen zu senken.
3. Leichtgewichtig und skalierbar
AlsBypass-Middleware für die Inferenz-Engine verbindet sich checkpoint-engine mit minimalem Eingriff mit bestehenden Diensten. Bietet Pipeline-Updates für umfangreiche Bereitstellungen und ist mit gängigen verteilten Segmentierungslösungen kompatibel.
2. Warum ist es schneller?
1. Überlappung von Kommunikation und Kopierüberlappung
In derUpdate-Pipeline der Checkpoint-Engine werden Kommunikation und Speicherkopie parallel ausgeführt, um Wartezeiten im Leerlauf zu reduzieren. Die Planung auf Stream-Ebene ermöglicht die Verwendung von Gewichtungen nach Belieben, wodurch der Gesamtdurchsatz erhöht wird.
2. On-Demand-Granularitäts- und Routing-Optimierung
RL-Iterationen aktualisieren in der Regel nur einige Gewichtungen oder Anpassungsschichten, und Checkpoint-Engine unterstützt Chunking und inkrementelles Routing, wodurch das Volumen der knotenübergreifenden Handhabung reduziert und die Aktualisierungszeit von 1T-Level-Modellen weiter verkürzt wird.
3. Die Stabilitäts- und Rollback-Checkpoint-Engine
verfügt standardmäßig über eine Versions- und Verifizierung und hält die alte Version im Speicher warm, wenn sie fehlschlägt, führt ein schnelles Rollback durch und stellt die SLA der Onlineinferenz sicher.
3. Wie man es benutzt, drei Schritte
zur Implementierung 1. Zugriffsszenarien
(1) Feinabstimmung der RL-Verbesserung: häufige Richtlinienaktualisierungen in kleinen Schritten
(2) Online A/B: Graustufen-Updates für bestimmte Mandanten oder Datenverkehr
(3) Gemischte Last: Offline-Batch- und Online-Anfragen existieren nebeneinander
2. Bereitstellungsprozess
(1) Laden Sie den Checkpoint-Engine-Proxy auf der Inferenzseite
(2) Geben Sie Gewichtungsblöcke und Metadatenindizes auf der Trainingsseite aus
(3) Wählen Sie Broadcast- oder P2P-Routen aus, aktivieren Sie die überlappende Replikation und überwachen Sie die Verifizierung
3. Governance und Beobachtung
(1) Aufzeichnen von Version, Hash und Zeitverbrauch für jede Gewichtsänderung
(2) Legen Sie Parallelitäts- und Drosselungsschwellenwerte fest, um die Dienstlatenz zu schützen
(3) Legen Sie Budget- und Häufigkeitsgrenzen
fest 4. Vergleichs- und Auswahlvorschläge
1. VS herkömmliche Checkpoint-Engine für Neustart/vollständiges Neuladen
, um die Ausfallzeit auf die zweite Ebene zu reduzieren , die sich besser für Cluster mit hoher Parallelität und mehreren Replikaten eignet.
2. VS reiner Parameterserver
DerParameterserver konzentriert sich auf die Gradientensynchronisation auf der Trainingsseite; checkpoint-engine konzentriert sich auf die inferenzseitige Gewichtsverteilung und die In-situ-Substitution, die besser für den Online-Offline-Hybrid-Closed-Loop von RL geeignet ist.
3. Wann sollte es zuerst verwendet werden
? Wenn RL häufig aktualisiert wird, eine große Anzahl von Modellen hat, eine große Clustergröße hat und "unterbrechungsfreies Onboarding" ein harter Indikator ist, wird die Checkpoint-Engine bevorzugt.
Häufig gestellte Fragen (Q&A)
F: Wie hilft die checkpoint-engine, RL-Szenen zu beschleunigen?
A: Es aktualisiert die In-Place-Gewichtungen auf der LLM-Inferenzseite und lädt neue RL-Strategien fast "sofort" hoch, wodurch die Closed-Loop-Zeit vom Training bis zum Service erheblich verkürzt wird.
F: Wie wählt man zwischen Broadcast und P2P?
A: Kleine oder homogene Netze bevorzugen den Rundfunk; Entscheiden Sie sich für dynamisches P2P-Routing über Racks/Rechenzentren und komplexe Topologien hinweg und kombinieren Sie überlappende Kopien, um einen stabileren Durchsatz zu erzielen.
F: Auf welche Voraussetzungen stützt sich das 1T-Modell für ein 20-Sekunden-Update?
A: Verlassen Sie sich auf Chunk-Inkrement, Überlappung von Kommunikation und Kopie und effizientes Routing. Die Skalierung ist bei großen Clustern mit Tausenden von GPUs deutlicher, was wirklich vom Netzwerk und der Segmentierungsstrategie abhängt.
F: Ist die Checkpoint-Engine mit vorhandenen Inferenz-Engines kompatibel?
A: Als schlanke Middleware kann sie auf den Mainstream-Distributed-Inferenz-Stack zugreifen, ohne die Geschäftslogik zu ändern. Sicheres Rollback und Graustufen werden durch Versionierung und Verifizierung erreicht.