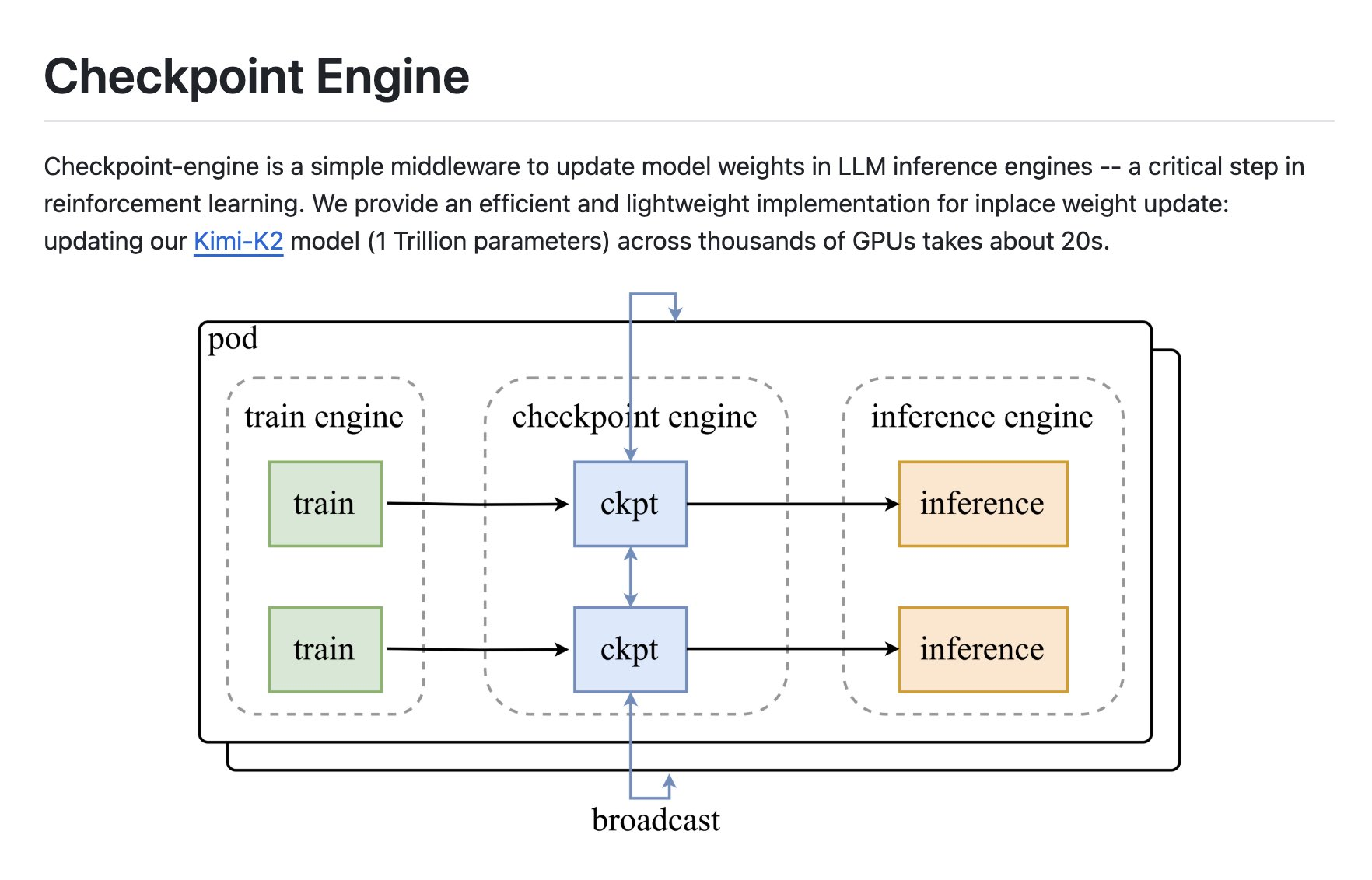
面向 RL 与大规模 LLM 推理的需求,checkpoint-engine 作为轻量中间件,实现“in-place 就地权重更新”,支持 broadcast 同步与 P2P 动态路由,结合通信与拷贝重叠优化。在数千 GPU 集群上,1T 模型权重更新可在约 20 秒内完成,帮助 RL 策略快速闭环到线上推理服务。
一、是什么,解决什么问题
1、就地更新,缩短 RL 闭环
checkpoint-engine 在 LLM 推理进程内完成就地权重更新,避免重启与完整 reload。对于 RL 循环,checkpoint-engine 让新策略从训练侧快速同步到在线推理侧,减少“生成-反馈-更新”的等待。
2、双通道分发:broadcast 与 P2P
checkpoint-engine 既支持 broadcast 同步更新,也支持 P2P 动态拓扑;在不同机房与网络条件下可灵活切换,降低大模型多副本一致性成本。
3、轻量与可扩展
作为推理引擎的旁路中间件,checkpoint-engine 以最小侵入对接现有服务;对大规模部署提供流水线化更新,兼容主流分布式切分方案。
二、为什么更快,工程要点
1、通信与拷贝重叠
在 checkpoint-engine 的更新管线中,通信与内存拷贝并行,减少空转等待;流级别的调度让权重块边到边用,提升总体吞吐。
2、按需粒度与路由优化
RL 迭代通常只更新部分权重或适配层,checkpoint-engine 支持分块与增量路由,降低跨节点搬运体量,进一步压缩 1T 级别模型的更新时间。
3、稳定性与回滚
checkpoint-engine 默认带版本与校验,失败时保持旧版本热身在内存中,回滚迅速,保障线上推理的 SLA。
三、怎么用,三步落地
1、接入场景
(1)RL 强化微调:策略频繁小步更新
(2)线上 A/B:为特定租户或流量灰度更新
(3)混合负载:离线批量与在线请求并存
2、部署流程
(1)在推理侧加载 checkpoint-engine 代理
(2)训练侧输出权重块与元数据索引
(3)选择 broadcast 或 P2P 路由,开启重叠复制并监控校验
3、治理与观测
(1)为每次权重变更记录版本、hash 与耗时
(2)设置并发与节流阈值,保护服务延迟
(3)按租户与模型分域做预算与频率限制
四、对比与选型建议
1、vs 传统重启/全量 reload
checkpoint-engine 把分钟级停机压到秒级热更,更适合高并发与多副本集群。
2、vs 纯参数服务器
参数服务器重在训练侧梯度同步;checkpoint-engine 聚焦推理侧权重分发与在位替换,更贴合 RL 在线-离线混合闭环。
3、何时优先使用
当 RL 高频更新、模型巨量、集群规模大且“无中断上线”是硬指标时,优先采用 checkpoint-engine。
常见问题解答(Q&A)
Q:checkpoint-engine 如何帮助 RL 场景提速?
A:它在 LLM 推理侧做就地权重更新,把 RL 新策略几乎“即时”上载,显著缩短从训练到服务的闭环时间。
Q:broadcast 与 P2P 两种方式如何选择?
A:小规模或同构网络优先 broadcast;跨机架/跨机房、拓扑复杂时选 P2P 动态路由,结合重叠拷贝获得更稳定吞吐。
Q:1T 模型 20 秒更新依赖哪些前提?
A:依赖分块增量、通信-拷贝重叠与高效路由;在数千 GPU 的大集群中更能体现规模效应,实际取决于网络与切分策略。
Q:checkpoint-engine 与现有推理引擎兼容吗?
A:作为轻量中间件,可在不改业务逻辑前提下接入主流分布式推理栈;通过版本化与校验实现安全回滚与灰度。