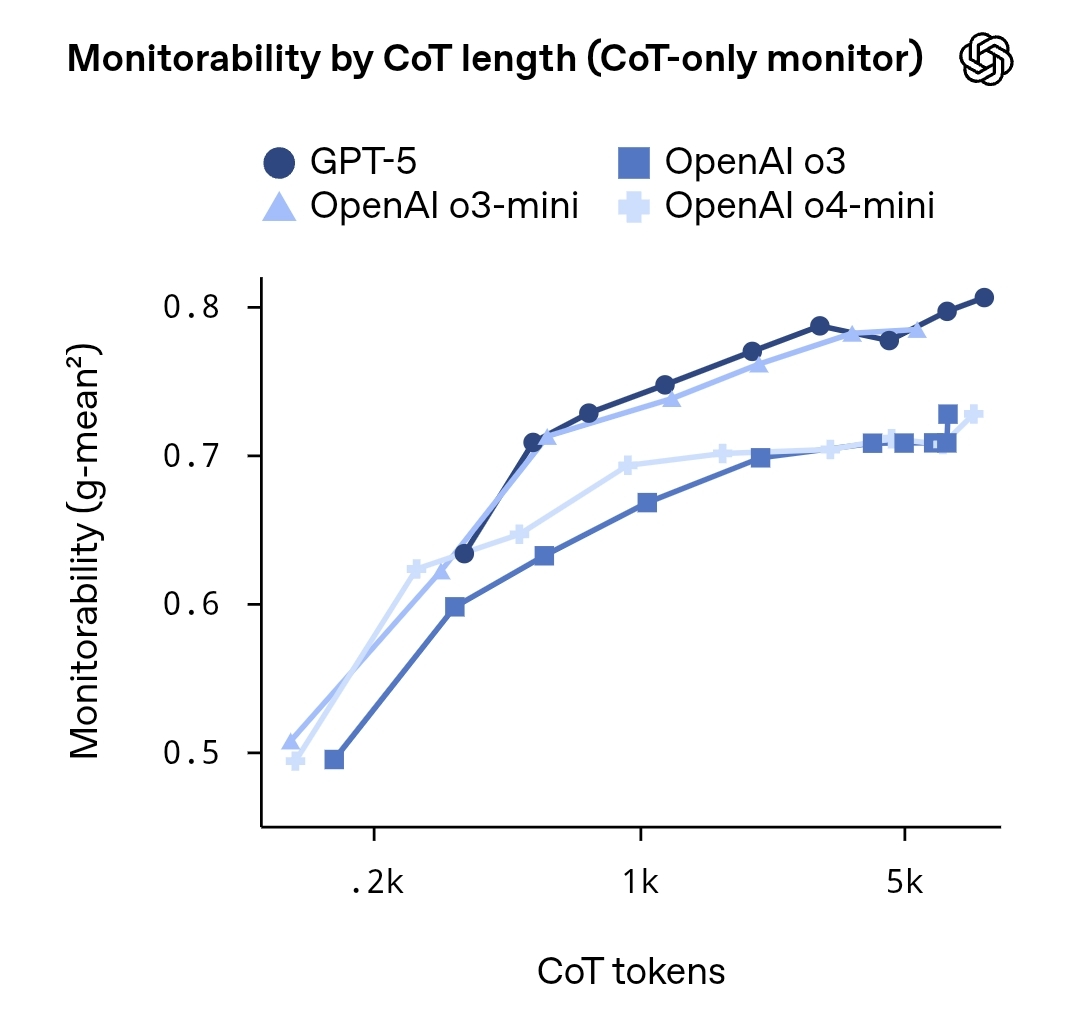
OpenAI released a research report "Evaluating Chain-of-Thought Monitorability", which systematically evaluates the monitorability and security impact of the "Chain-of-Thought" (CoT) within large language models. The report pointed out that although the reasoning process generated by the model can be predicted to a certain extent through external prompts or proxy models, its complete and accurate thinking trajectory is still highly uncertain and unreproducible.
The research team used different model sizes and task types in multiple experiments to analyze how to evaluate the transparency and auditability of the model chain of thought through "proxy model monitoring" and "implicit labeling reasoning steps". The results show that higher-level inference targets can be partially monitored, but there is still a risk of randomness and sensitive information leakage in the details. The report recommends maintaining a balance between security and privacy, and in the future, AI can be improved in mission-critical scenarios through specific oversight mechanisms, sandbox reasoning, and explanatory annotation frameworks.
OpenAI emphasized at the end of the article that the study aims to provide technical reference for AI governance, risk auditing and scientific research security, and does not mean that the current public model has or exposes an internal "complete chain of thought". Subsequent research will focus on how to improve inference transparency and process verification without affecting model performance.
FAQsQ: What is the topic of this study?
A: The research mainly explores whether the "chain of thought" within large language models can be monitored, interpreted, or partially predicted, and the security implications of this visibility.
Q: What is a "Chain-of-Thought"?
A: Refers to the intermediate reasoning steps or logical processes of the model before generating answers, which are usually not visible in the output but affect the final result.
Q: What are the main conclusions found by the study?
A: Chains of thought can be partially predicted, but they cannot be fully reproducible, and there are risks of randomness, privacy, and abuse.
Q: Why study the monitorability of chains of thought?
A: In order to improve the security and auditability of AI systems, researchers can better understand the reasoning behavior of models in critical tasks.
Q: Does the research mean that OpenAI has disclosed its internal reasoning mechanisms?
A: No. The report is for academic evaluation and security governance reference only, and does not disclose any interfaces or features that can access the model's internal inference.