I. Abstract
UNO-Bench is an open-source benchmark for unified evaluation of "single-model/full-model" questions, covering both perception and reasoning dimensions. It provides Chinese real-world scenario questions and multi-step open-ended question answering (MO) questions. The data and tools emphasize high quality and human-led construction, and are equipped with a general scoring model for automated evaluation.
II. Core Features
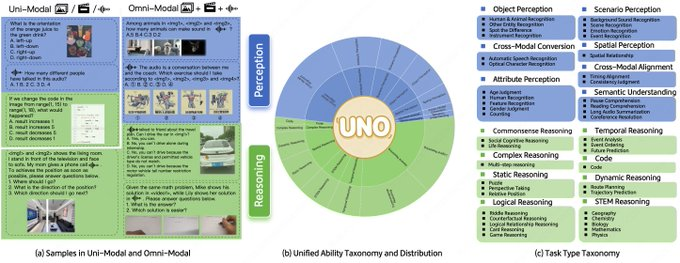
- Unified capability framework: 44 types of tasks, 5 modal combinations, with the same indicator caliber for single-modality and full-modality tasks.
- High quality and solvability: 1250 full-modal data points, human-reviewed construction, 98% solvable across modalities.
- Efficiency optimization: Automatic compression of 18 public benchmarks speeds up evaluation by approximately 90% and improves consistency by approximately 98%.
- More realistic question types: Multi-step open-ended questions and answers have been added to cover complex reasoning chains.
- General scoring: Supports 6 types of questions, with approximately 95% consistency in annotation in OOD scenarios.
- Key findings: Strong models exhibit "power-law synergy" (capabilities increase multiplicatively with modal combinations).
III. Installation
1. Dataset: datasets.load_dataset("meituan-longcat/UNO-Bench") Retrieves the default shards.
- Source code and documentation: View the README and evaluation script examples in the cloned GitHub repository.
- Environment: Python/Transformers/Datasets. A standard environment is sufficient. Install dependencies according to the repository instructions.
IV. Typical Use Cases
- Model cross-sectional evaluation: Compare the differences between single-model and full-model under a unified scale.
- Chinese scenario verification: Perception and reasoning ability in real-life/cultural/social contexts.
- Reasoning chain analysis: Use multi-step open-ended question answering to diagnose weaknesses in long-chain reasoning.
- RAG/Multimodal System: Validate the overall benefits of audio, image, and video fusion.
V. Ecology and Competitors
- Ecosystem: Provides datasets, leaderboards, and papers; the toolchain is under development.
- Competitors: Compared with visual/subject-specific benchmarks such as MMBEC, MMMU, and MathVista, UNO-Bench emphasizes "unified evaluation of single-mode to full-mode" and real-world Chinese scenarios; its compression method facilitates rapid alignment of multiple benchmarks.
VI. Limitations and Precautions
- The applicability of automatic compression needs to be verified on a task-by-task basis; some sub-tasks may lack sufficient information.
- The general scoring model may still have biases for long answers/generative outputs, and it is recommended to manually review samples.
- Currently, the focus is on Chinese-language scenarios, and collaborations for multilingual extensions and English versions are still being solicited.
- "Power-law synergy" is an empirical discovery, and it needs to be re-verified when transferred to new tasks.
VII. Project Address
https://github.com/meituan-longcat/UNO-Bench
VIII. Frequently Asked Questions
Q: What modalities and tasks does UNO-Bench cover?
A: It covers combinations of audio, images, and video, with a total of 5 modal combinations and 44 task categories, targeting both perception and reasoning dimensions.
Q: How can I quickly run the UNO-Bench benchmark?
A: Load data via Hugging Face, and perform inference and scoring using sample scripts from the repository and a general scoring model.
Q: How much does automatic compression affect the reliability of the results?
A: The ranking consistency is maintained at approximately 98% across 18 publicly available benchmarks, but it is still recommended to combine this with sampling of the original set.
Q: Does it support English or multiple languages?
A: The official focus is currently on the Chinese language version, and we are looking for partners to jointly develop English and multilingual versions.
Q: Does power-law collaboration hold true for all models?
A: It is mainly significant in strong models; for weak models, it is more like a "weakest link effect" and needs to be specifically evaluated and confirmed.