I. Résumé
UNO-Bench est un banc d'essai open source pour l'évaluation unifiée des questions « modèle unique/modèle complet », couvrant à la fois la perception et le raisonnement. Il propose des questions issues de scénarios réels en chinois et des questions ouvertes à plusieurs étapes. Les données et les outils privilégient la qualité et l'expertise humaine, et intègrent un modèle de notation général pour l'évaluation automatisée.
II. Caractéristiques principales
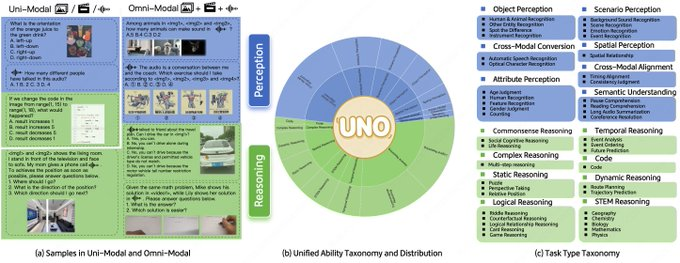
- Cadre de capacités unifié : 44 types de tâches, 5 combinaisons modales, avec le même calibre d'indicateur pour les tâches à modalité unique et à modalité complète.
- Haute qualité et solvabilité : 1250 points de données multimodaux complets, construction vérifiée par l'homme, 98 % soluble dans toutes les modalités.
- Optimisation de l'efficacité : La compression automatique de 18 benchmarks publics accélère l'évaluation d'environ 90 % et améliore la cohérence d'environ 98 %.
- Des types de questions plus réalistes : des questions et réponses ouvertes à plusieurs étapes ont été ajoutées pour couvrir des chaînes de raisonnement complexes.
- Notation générale : Prend en charge 6 types de questions, avec une cohérence d'annotation d'environ 95 % dans les scénarios OOD.
- Principales conclusions : Les modèles performants présentent une « synergie de loi de puissance » (les capacités augmentent de manière multiplicative avec les combinaisons modales).
III. Installation
1. Jeu de données : datasets.load_dataset("meituan-longcat/UNO-Bench") Récupère les fragments par défaut.
- Code source et documentation : Consultez le fichier README et les exemples de scripts d’évaluation dans le dépôt GitHub cloné.
- Environnement : Python/Transformers/Datasets. Un environnement standard suffit. Installez les dépendances en suivant les instructions du dépôt.
IV. Cas d'utilisation typiques
- Évaluation transversale du modèle : comparer les différences entre le modèle unique et le modèle complet sur une échelle unifiée.
- Vérification de scénarios chinois : Capacité de perception et de raisonnement dans des contextes réels/culturels/sociaux.
- Analyse de la chaîne de raisonnement : Utiliser des questions ouvertes en plusieurs étapes pour diagnostiquer les faiblesses du raisonnement en chaîne longue.
- Système RAG/multimodal : Valider les avantages globaux de la fusion audio, image et vidéo.
V. Écologie et concurrents
- Écosystème : Fournit des ensembles de données, des classements et des articles ; la chaîne d'outils est en cours de développement.
- Concurrents : Comparé aux benchmarks visuels/spécifiques à un sujet tels que MMBEC, MMMU et MathVista, UNO-Bench met l'accent sur « l'évaluation unifiée du mode unique au mode complet » et sur des scénarios chinois réels ; sa méthode de compression facilite l'alignement rapide de plusieurs benchmarks.
VI. Limitations et précautions
- L’applicabilité de la compression automatique doit être vérifiée tâche par tâche ; certaines sous-tâches peuvent manquer d’informations suffisantes.
- Le modèle de notation général peut encore présenter des biais pour les réponses longues/les productions génératives, et il est recommandé d'examiner manuellement les échantillons.
- Actuellement, l'accent est mis sur les scénarios en langue chinoise, et les collaborations pour des extensions multilingues et des versions anglaises sont toujours sollicitées.
- La « synergie de la loi de puissance » est une découverte empirique et doit être revérifiée lorsqu'elle est transférée à de nouvelles tâches.
VII. Adresse du projet
https://github.com/meituan-longcat/UNO-Bench
VIII. Foire aux questions
Q : Quelles sont les modalités et les tâches couvertes par UNO-Bench ?
A : Il couvre des combinaisons d'audio, d'images et de vidéo, avec un total de 5 combinaisons modales et 44 catégories de tâches, ciblant à la fois les dimensions de la perception et du raisonnement.
Q : Comment puis-je exécuter rapidement le test de performance UNO-Bench ?
A : Charger les données via Hugging Face, puis effectuer l'inférence et le scoring à l'aide d'exemples de scripts du dépôt et d'un modèle de scoring général.
Q : Dans quelle mesure la compression automatique affecte-t-elle la fiabilité des résultats ?
A : La cohérence du classement est maintenue à environ 98 % sur 18 benchmarks accessibles au public, mais il est toujours recommandé de combiner cela avec un échantillonnage de l'ensemble original.
Q : Prend-il en charge l'anglais ou plusieurs langues ?
A: Officiellement, nous nous concentrons actuellement sur la version en langue chinoise, et nous recherchons des partenaires pour développer conjointement des versions en anglais et multilingues.
Q : La collaboration en loi de puissance est-elle valable pour tous les modèles ?
A : C’est surtout significatif dans les modèles robustes ; pour les modèles faibles, cela s’apparente davantage à un « effet de maillon faible » et doit être spécifiquement évalué et confirmé.